 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Value in the Age of Scaling: Understanding LLM Scaling Dynamics Under Real-Synthetic Data Mixtures
Nov 17, 2025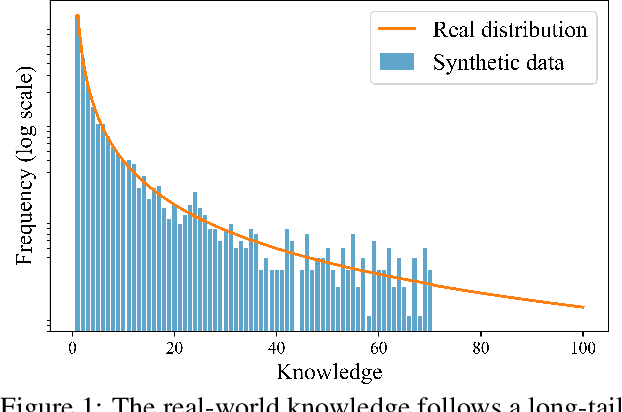
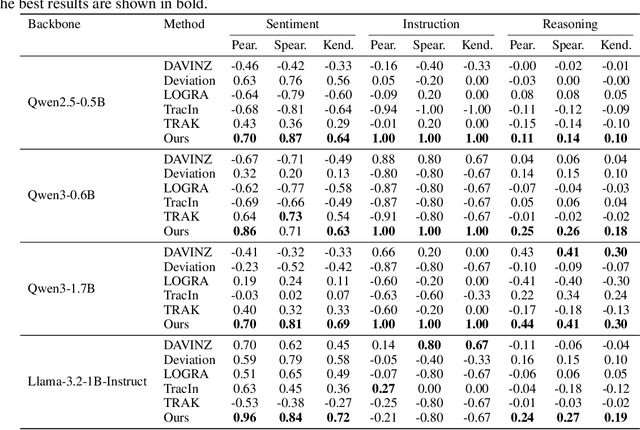
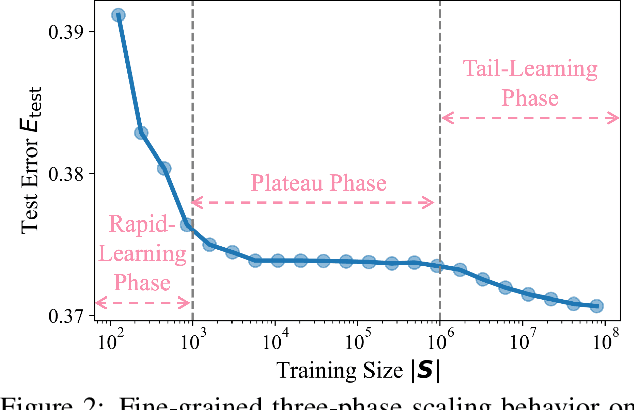
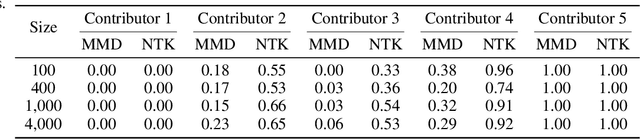
The rapid progress of large language models (LLMs) is fueled by the growing reliance on datasets that blend real and synthetic data. While synthetic data offers scalability and cost-efficiency, it often introduces systematic distributional discrepancies, particularly underrepresenting long-tail knowledge due to truncation effects from data generation mechanisms like top-p sampling, temperature scaling, and finite sampling. These discrepancies pose fundamental challenges in characterizing and evaluating the utility of mixed real-synthetic datasets. In this paper, we identify a three-phase scaling behavior characterized by two breakpoints that reflect transitions in model behavior across learning head and tail knowledge. We further derive an LLM generalization bound designed for real and synthetic mixtures, revealing several key factors that govern their generalization performance. Building on our theoretical findings, we propose an effective yet efficient data valuation method that scales to large-scale datasets. Comprehensive experiments across four tasks, including image classification, sentiment classification, instruction following, and complex reasoning, demonstrate that our method surpasses state-of-the-art baselines in data valuation with significantly low computational cost.
EVINET: Towards Open-World Graph Learning via Evidential Reasoning Network
Jun 11, 2025Graph learning has been crucial to many real-world tasks, but they are often studied with a closed-world assumption, with all possible labels of data known a priori. To enable effective graph learning in an open and noisy environment, it is critical to inform the model users when the model makes a wrong prediction to in-distribution data of a known class, i.e., misclassification detection or when the model encounters out-of-distribution from novel classes, i.e., out-of-distribution detection. This paper introduces Evidential Reasoning Network (EVINET), a framework that addresses these two challenges by integrating Beta embedding within a subjective logic framework. EVINET includes two key modules: Dissonance Reasoning for misclassification detection and Vacuity Reasoning for out-of-distribution detection. Extensive experiments demonstrate that EVINET outperforms state-of-the-art methods across multiple metrics in the tasks of in-distribution classification, misclassification detection, and out-of-distribution detection. EVINET demonstrates the necessity of uncertainty estimation and logical reasoning for misclassification detection and out-of-distribution detection and paves the way for open-world graph learning. Our code and data are available at https://github.com/SSSKJ/EviNET.
EviNet: Evidential Reasoning Network for Resilient Graph Learning in the Open and Noisy Environments
Jun 08, 2025Graph learning has been crucial to many real-world tasks, but they are often studied with a closed-world assumption, with all possible labels of data known a priori. To enable effective graph learning in an open and noisy environment, it is critical to inform the model users when the model makes a wrong prediction to in-distribution data of a known class, i.e., misclassification detection or when the model encounters out-of-distribution from novel classes, i.e., out-of-distribution detection. This paper introduces Evidential Reasoning Network (EVINET), a framework that addresses these two challenges by integrating Beta embedding within a subjective logic framework. EVINET includes two key modules: Dissonance Reasoning for misclassification detection and Vacuity Reasoning for out-of-distribution detection. Extensive experiments demonstrate that EVINET outperforms state-of-the-art methods across multiple metrics in the tasks of in-distribution classification, misclassification detection, and out-of-distribution detection. EVINET demonstrates the necessity of uncertainty estimation and logical reasoning for misclassification detection and out-of-distribution detection and paves the way for open-world graph learning. Our code and data are available at https://github.com/SSSKJ/EviNET.
LENSLLM: Unveiling Fine-Tuning Dynamics for LLM Selection
May 01, 2025The proliferation of open-sourced Large Language Models (LLMs) and diverse downstream tasks necessitates efficient model selection, given the impracticality of fine-tuning all candidates due to computational constraints. Despite the recent advances in LLM selection, a fundamental research question largely remains nascent: how can we model the dynamic behaviors of LLMs during fine-tuning, thereby enhancing our understanding of their generalization performance across diverse downstream tasks? In this work, we propose a novel theoretical framework that provides a proper lens to assess the generalization capabilities of LLMs, thereby enabling accurate and efficient LLM selection for downstream applications. In particular, we first derive a Hessian-based PAC-Bayes generalization bound that unveils fine-tuning dynamics of LLMs and then introduce LENSLLM, a Neural Tangent Kernel(NTK)-based Rectified Scaling Model that enables accurate performance predictions across diverse tasks while maintaining computational efficiency. Extensive empirical results on 3 large-scale benchmarks demonstrate that our model achieves up to 91.1% accuracy and reduces up to 88.5% computational cost in LLM selection, outperforming 5 state-of-the-art methods. We open-source our proposed LENSLLM model and corresponding results at the Github link: https://github.com/Susan571/LENSLLM.git.
MetaScientist: A Human-AI Synergistic Framework for Automated Mechanical Metamaterial Design
Dec 20, 2024



The discovery of novel mechanical metamaterials, whose properties are dominated by their engineered structures rather than chemical composition, is a knowledge-intensive and resource-demanding process. To accelerate the design of novel metamaterials, we present MetaScientist, a human-in-the-loop system that integrates advanced AI capabilities with expert oversight with two primary phases: (1) hypothesis generation, where the system performs complex reasoning to generate novel and scientifically sound hypotheses, supported with domain-specific foundation models and inductive biases retrieved from existing literature; (2) 3D structure synthesis, where a 3D structure is synthesized with a novel 3D diffusion model based on the textual hypothesis and refined it with a LLM-based refinement model to achieve better structure properties. At each phase, domain experts iteratively validate the system outputs, and provide feedback and supplementary materials to ensure the alignment of the outputs with scientific principles and human preferences. Through extensive evaluation from human scientists, MetaScientist is able to deliver novel and valid mechanical metamaterial designs that have the potential to be highly impactful in the metamaterial field.
HeroLT: Benchmarking Heterogeneous Long-Tailed Learning
Jul 17, 2023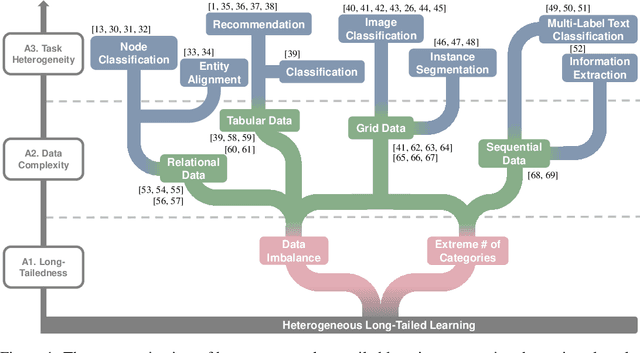


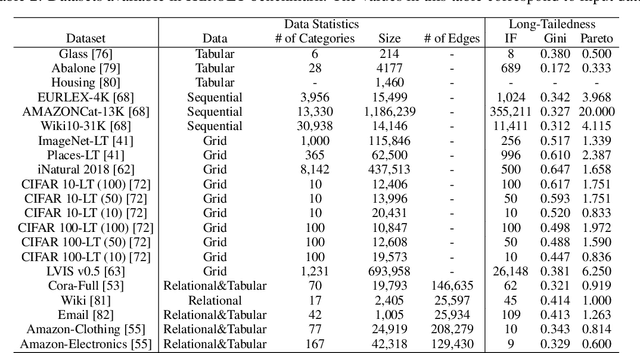
Long-tailed data distributions are prevalent in a variety of domains, including finance, e-commerce, biomedical science, and cyber security. In such scenarios, the performance of machine learning models is often dominated by the head categories, while the learning of tail categories is significantly inadequate. Given abundant studies conducted to alleviate the issue, this work aims to provide a systematic view of long-tailed learning with regard to three pivotal angles: (A1) the characterization of data long-tailedness, (A2) the data complexity of various domains, and (A3) the heterogeneity of emerging tasks. To achieve this, we develop the most comprehensive (to the best of our knowledge) long-tailed learning benchmark named HeroLT, which integrates 13 state-of-the-art algorithms and 6 evaluation metrics on 14 real-world benchmark datasets across 4 tasks from 3 domains. HeroLT with novel angles and extensive experiments (264 in total) enables researchers and practitioners to effectively and fairly evaluate newly proposed methods compared with existing baselines on varying types of datasets. Finally, we conclude by highlighting the significant applications of long-tailed learning and identifying several promising future directions. For accessibility and reproducibility, we open-source our benchmark HeroLT and corresponding results at https://github.com/SSSKJ/HeroLT.
GPatcher: A Simple and Adaptive MLP Model for Alleviating Graph Heterophily
Jun 25, 2023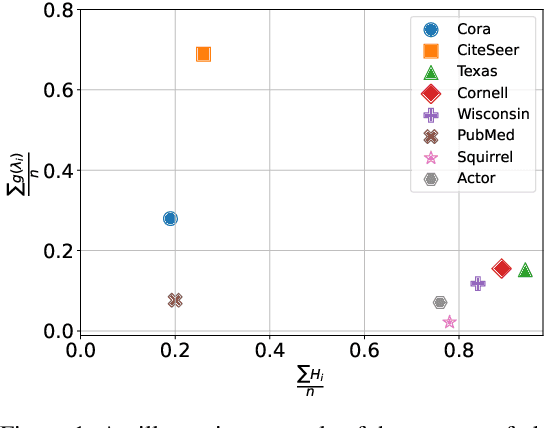
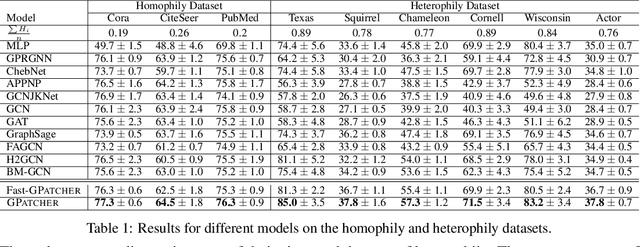
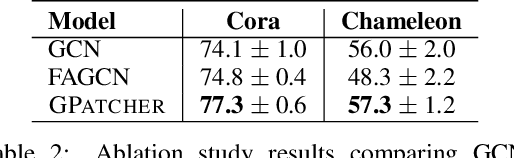
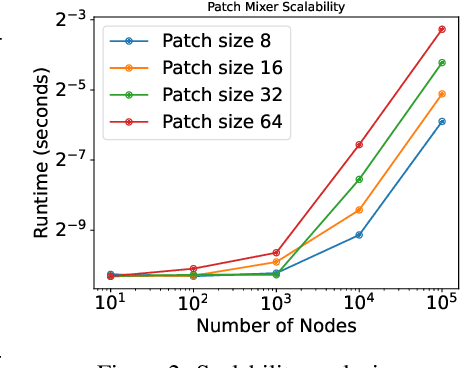
While graph heterophily has been extensively studied in recent years, a fundamental research question largely remains nascent: How and to what extent will graph heterophily affect the prediction performance of graph neural networks (GNNs)? In this paper, we aim to demystify the impact of graph heterophily on GNN spectral filters. Our theoretical results show that it is essential to design adaptive polynomial filters that adapts different degrees of graph heterophily to guarantee the generalization performance of GNNs. Inspired by our theoretical findings, we propose a simple yet powerful GNN named GPatcher by leveraging the MLP-Mixer architectures. Our approach comprises two main components: (1) an adaptive patch extractor function that automatically transforms each node's non-Euclidean graph representations to Euclidean patch representations given different degrees of heterophily, and (2) an efficient patch mixer function that learns salient node representation from both the local context information and the global positional information. Through extensive experiments, the GPatcher model demonstrates outstanding performance on node classification compared with popular homophily GNNs and state-of-the-art heterophily GNNs.
Characterizing Long-Tail Categories on Graphs
May 17, 2023Long-tail data distributions are prevalent in many real-world networks, including financial transaction networks, e-commerce networks, and collaboration networks. Despite the success of recent developments, the existing works mainly focus on debiasing the machine learning models via graph augmentation or objective reweighting. However, there is limited literature that provides a theoretical tool to characterize the behaviors of long-tail categories on graphs and understand the generalization performance in real scenarios. To bridge this gap, we propose the first generalization bound for long-tail classification on graphs by formulating the problem in the fashion of multi-task learning, i.e., each task corresponds to the prediction of one particular category. Our theoretical results show that the generalization performance of long-tail classification is dominated by the range of losses across all tasks and the total number of tasks. Building upon the theoretical findings, we propose a novel generic framework Tail2Learn to improve the performance of long-tail categories on graphs. In particular, we start with a hierarchical task grouping module that allows label-limited classes to benefit from the relevant information shared by other classes; then, we further design a balanced contrastive learning module to balance the gradient contributions of head and tail classes. Finally, extensive experiments on various real-world datasets demonstrate the effectiveness of Tail2Learn in capturing long-tail categories on graphs.
Dynamic Transfer Learning across Graphs
May 02, 2023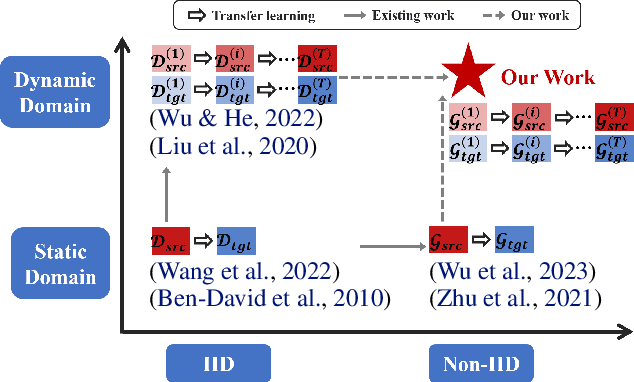
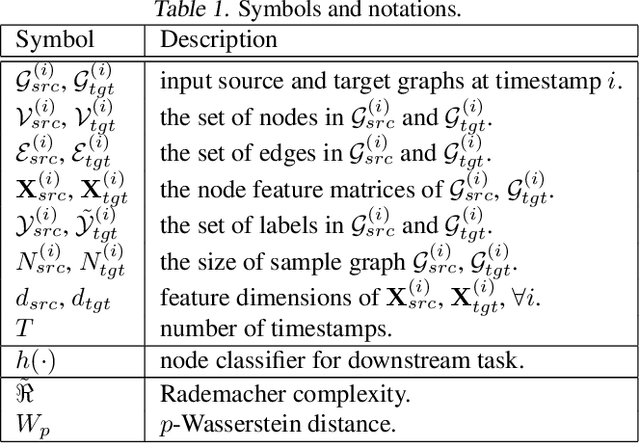
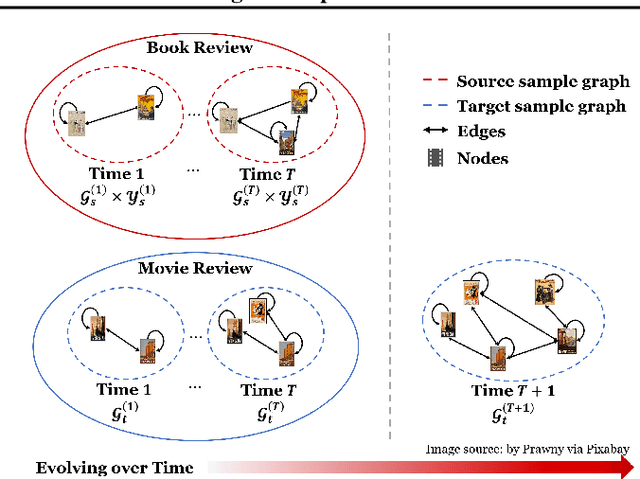
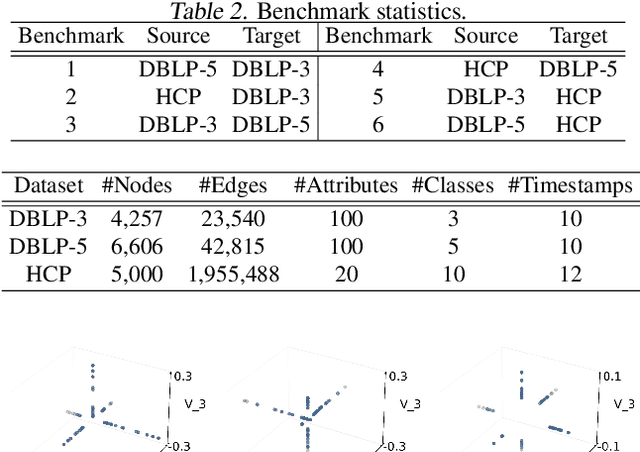
Transferring knowledge across graphs plays a pivotal role in many high-stake domains, ranging from transportation networks to e-commerce networks, from neuroscience to finance. To date, the vast majority of existing works assume both source and target domains are sampled from a universal and stationary distribution. However, many real-world systems are intrinsically dynamic, where the underlying domains are evolving over time. To bridge the gap, we propose to shift the problem to the dynamic setting and ask: given the label-rich source graphs and the label-scarce target graphs observed in previous T timestamps, how can we effectively characterize the evolving domain discrepancy and optimize the generalization performance of the target domain at the incoming T+1 timestamp? To answer the question, for the first time, we propose a generalization bound under the setting of dynamic transfer learning across graphs, which implies the generalization performance is dominated by domain evolution and domain discrepancy between source and target domains. Inspired by the theoretical results, we propose a novel generic framework DyTrans to improve knowledge transferability across dynamic graphs. In particular, we start with a transformer-based temporal encoding module to model temporal information of the evolving domains; then, we further design a dynamic domain unification module to efficiently learn domain-invariant representations across the source and target domains. Finally, extensive experiments on various real-world datasets demonstrate the effectiveness of DyTrans in transferring knowledge from dynamic source domains to dynamic target domains.
A Benchmark for Federated Hetero-Task Learning
Jun 21, 2022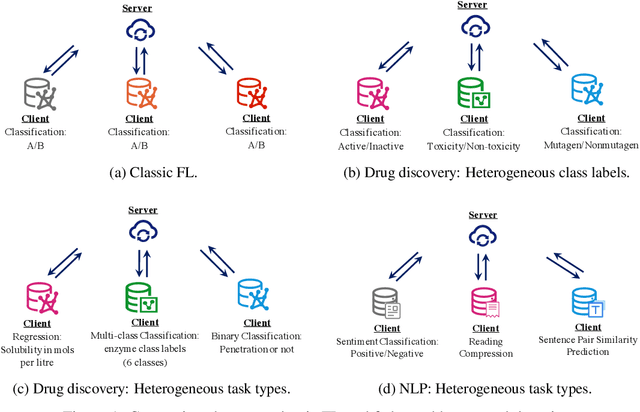
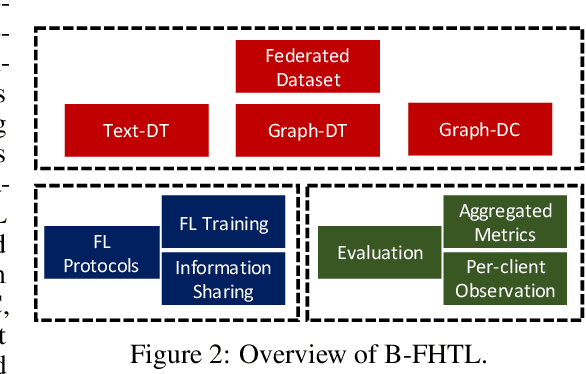
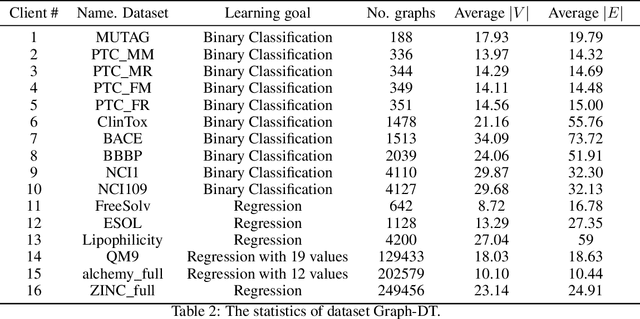
To investigate the heterogeneity in federated learning in real-world scenarios, we generalize the classic federated learning to federated hetero-task learning, which emphasizes the inconsistency across the participants in federated learning in terms of both data distribution and learning tasks. We also present B-FHTL, a federated hetero-task learning benchmark consisting of simulation dataset, FL protocols and a unified evaluation mechanism. B-FHTL dataset contains three well-designed federated learning tasks with increasing heterogeneity. Each task simulates the clients with different non-IID data and learning tasks. To ensure fair comparison among different FL algorithms, B-FHTL builds in a full suite of FL protocols by providing high-level APIs to avoid privacy leakage, and presets most common evaluation metrics spanning across different learning tasks, such as regression, classification, text generation and etc. Furthermore, we compare the FL algorithms in fields of federated multi-task learning, federated personalization and federated meta learning within B-FHTL, and highlight the influence of heterogeneity and difficulties of federated hetero-task learning. Our benchmark, including the federated dataset, protocols, the evaluation mechanism and the preliminary experiment, is open-sourced at https://github.com/alibaba/FederatedScope/tree/master/benchmark/B-FHTL