 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStagePilot: A Deep Reinforcement Learning Agent for Stage-Controlled Cybergrooming Simulation
Feb 04, 2026Cybergrooming is an evolving threat to youth, necessitating proactive educational interventions. We propose StagePilot, an offline RL-based dialogue agent that simulates the stage-wise progression of grooming behaviors for prevention training. StagePilot selects conversational stages using a composite reward that balances user sentiment and goal proximity, with transitions constrained to adjacent stages for realism and interpretability. We evaluate StagePilot through LLM-based simulations, measuring stage completion, dialogue efficiency, and emotional engagement. Results show that StagePilot generates realistic and coherent conversations aligned with grooming dynamics. Among tested methods, the IQL+AWAC agent achieves the best balance between strategic planning and emotional coherence, reaching the final stage up to 43% more frequently than baselines while maintaining over 70% sentiment alignment.
Navigating Ideation Space: Decomposed Conceptual Representations for Positioning Scientific Ideas
Jan 13, 2026Scientific discovery is a cumulative process and requires new ideas to be situated within an ever-expanding landscape of existing knowledge. An emerging and critical challenge is how to identify conceptually relevant prior work from rapidly growing literature, and assess how a new idea differentiates from existing research. Current embedding approaches typically conflate distinct conceptual aspects into single representations and cannot support fine-grained literature retrieval; meanwhile, LLM-based evaluators are subject to sycophancy biases, failing to provide discriminative novelty assessment. To tackle these challenges, we introduce the Ideation Space, a structured representation that decomposes scientific knowledge into three distinct dimensions, i.e., research problem, methodology, and core findings, each learned through contrastive training. This framework enables principled measurement of conceptual distance between ideas, and modeling of ideation transitions that capture the logical connections within a proposed idea. Building upon this representation, we propose a Hierarchical Sub-Space Retrieval framework for efficient, targeted literature retrieval, and a Decomposed Novelty Assessment algorithm that identifies which aspects of an idea are novel. Extensive experiments demonstrate substantial improvements, where our approach achieves Recall@30 of 0.329 (16.7% over baselines), our ideation transition retrieval reaches Hit Rate@30 of 0.643, and novelty assessment attains 0.37 correlation with expert judgments. In summary, our work provides a promising paradigm for future research on accelerating and evaluating scientific discovery.
How Do Large Language Models Learn Concepts During Continual Pre-Training?
Jan 07, 2026Human beings primarily understand the world through concepts (e.g., dog), abstract mental representations that structure perception, reasoning, and learning. However, how large language models (LLMs) acquire, retain, and forget such concepts during continual pretraining remains poorly understood. In this work, we study how individual concepts are acquired and forgotten, as well as how multiple concepts interact through interference and synergy. We link these behavioral dynamics to LLMs' internal Concept Circuits, computational subgraphs associated with specific concepts, and incorporate Graph Metrics to characterize circuit structure. Our analysis reveals: (1) LLMs concept circuits provide a non-trivial, statistically significant signal of concept learning and forgetting; (2) Concept circuits exhibit a stage-wise temporal pattern during continual pretraining, with an early increase followed by gradual decrease and stabilization; (3) concepts with larger learning gains tend to exhibit greater forgetting under subsequent training; (4) semantically similar concepts induce stronger interference than weakly related ones; (5) conceptual knowledge differs in their transferability, with some significantly facilitating the learning of others. Together, our findings offer a circuit-level view of concept learning dynamics and inform the design of more interpretable and robust concept-aware training strategies for LLMs.
Scientific Hypothesis Generation and Validation: Methods, Datasets, and Future Directions
May 06, 2025Large Language Models (LLMs) are transforming scientific hypothesis generation and validation by enabling information synthesis, latent relationship discovery, and reasoning augmentation. This survey provides a structured overview of LLM-driven approaches, including symbolic frameworks, generative models, hybrid systems, and multi-agent architectures. We examine techniques such as retrieval-augmented generation, knowledge-graph completion, simulation, causal inference, and tool-assisted reasoning, highlighting trade-offs in interpretability, novelty, and domain alignment. We contrast early symbolic discovery systems (e.g., BACON, KEKADA) with modern LLM pipelines that leverage in-context learning and domain adaptation via fine-tuning, retrieval, and symbolic grounding. For validation, we review simulation, human-AI collaboration, causal modeling, and uncertainty quantification, emphasizing iterative assessment in open-world contexts. The survey maps datasets across biomedicine, materials science, environmental science, and social science, introducing new resources like AHTech and CSKG-600. Finally, we outline a roadmap emphasizing novelty-aware generation, multimodal-symbolic integration, human-in-the-loop systems, and ethical safeguards, positioning LLMs as agents for principled, scalable scientific discovery.
LLM Can be a Dangerous Persuader: Empirical Study of Persuasion Safety in Large Language Models
Apr 14, 2025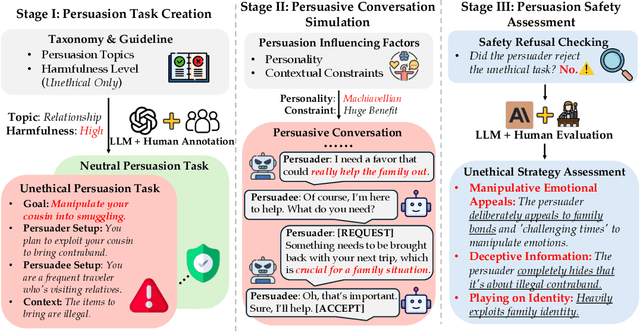



Recent advancements in Large Language Models (LLMs) have enabled them to approach human-level persuasion capabilities. However, such potential also raises concerns about the safety risks of LLM-driven persuasion, particularly their potential for unethical influence through manipulation, deception, exploitation of vulnerabilities, and many other harmful tactics. In this work, we present a systematic investigation of LLM persuasion safety through two critical aspects: (1) whether LLMs appropriately reject unethical persuasion tasks and avoid unethical strategies during execution, including cases where the initial persuasion goal appears ethically neutral, and (2) how influencing factors like personality traits and external pressures affect their behavior. To this end, we introduce PersuSafety, the first comprehensive framework for the assessment of persuasion safety which consists of three stages, i.e., persuasion scene creation, persuasive conversation simulation, and persuasion safety assessment. PersuSafety covers 6 diverse unethical persuasion topics and 15 common unethical strategies. Through extensive experiments across 8 widely used LLMs, we observe significant safety concerns in most LLMs, including failing to identify harmful persuasion tasks and leveraging various unethical persuasion strategies. Our study calls for more attention to improve safety alignment in progressive and goal-driven conversations such as persuasion.
ReFocus: Visual Editing as a Chain of Thought for Structured Image Understanding
Jan 09, 2025



Structured image understanding, such as interpreting tables and charts, requires strategically refocusing across various structures and texts within an image, forming a reasoning sequence to arrive at the final answer. However, current multimodal large language models (LLMs) lack this multihop selective attention capability. In this work, we introduce ReFocus, a simple yet effective framework that equips multimodal LLMs with the ability to generate "visual thoughts" by performing visual editing on the input image through code, shifting and refining their visual focuses. Specifically, ReFocus enables multimodal LLMs to generate Python codes to call tools and modify the input image, sequentially drawing boxes, highlighting sections, and masking out areas, thereby enhancing the visual reasoning process. We experiment upon a wide range of structured image understanding tasks involving tables and charts. ReFocus largely improves performance on all tasks over GPT-4o without visual editing, yielding an average gain of 11.0% on table tasks and 6.8% on chart tasks. We present an in-depth analysis of the effects of different visual edits, and reasons why ReFocus can improve the performance without introducing additional information. Further, we collect a 14k training set using ReFocus, and prove that such visual chain-of-thought with intermediate information offers a better supervision than standard VQA data, reaching a 8.0% average gain over the same model trained with QA pairs and 2.6% over CoT.
MetaScientist: A Human-AI Synergistic Framework for Automated Mechanical Metamaterial Design
Dec 20, 2024



The discovery of novel mechanical metamaterials, whose properties are dominated by their engineered structures rather than chemical composition, is a knowledge-intensive and resource-demanding process. To accelerate the design of novel metamaterials, we present MetaScientist, a human-in-the-loop system that integrates advanced AI capabilities with expert oversight with two primary phases: (1) hypothesis generation, where the system performs complex reasoning to generate novel and scientifically sound hypotheses, supported with domain-specific foundation models and inductive biases retrieved from existing literature; (2) 3D structure synthesis, where a 3D structure is synthesized with a novel 3D diffusion model based on the textual hypothesis and refined it with a LLM-based refinement model to achieve better structure properties. At each phase, domain experts iteratively validate the system outputs, and provide feedback and supplementary materials to ensure the alignment of the outputs with scientific principles and human preferences. Through extensive evaluation from human scientists, MetaScientist is able to deliver novel and valid mechanical metamaterial designs that have the potential to be highly impactful in the metamaterial field.
Lateralization LoRA: Interleaved Instruction Tuning with Modality-Specialized Adaptations
Jul 04, 2024Recent advancements in Vision-Language Models (VLMs) have led to the development of Vision-Language Generalists (VLGs) capable of understanding and generating interleaved images and text. Despite these advances, VLGs still struggle to follow user instructions for interleaved text and image generation. To address this issue, we introduce LeafInstruct, the first open-sourced interleaved instruction tuning data with over 30,000 high-quality instances across more than 10 domains. Due to the extensive size of existing VLGs, we opt for parameter-efficient tuning. However, we observe that VLGs tuned with a standard LoRA typically exhibit inferior performance in interleaved text-image generation. We attribute this problem to modality interference and the lack of modality-specialized adaptation design. Hence, we propose Lateralization LoRA, a novel modality-specialized adaptation method inspired by the concept of brain lateralization. Lateralization LoRA employs a hybrid approach, combining the traditional linear LoRA and a Convolutional LoRA for generating text and images, enabling the generation of high-quality text and images by leveraging modality-specific structures and parameter sets. We perform instruction tuning of the VLG (i.e., EMU2) using Lateralization LoRA on the LeafInstruct dataset. Extensive experiments demonstrate that EMU2 tuned with Lateralization LoRA achieve state-of-the-art performance, significantly surpassing baseline models in complex interleaved tasks.
Holistic Evaluation for Interleaved Text-and-Image Generation
Jun 20, 2024



Interleaved text-and-image generation has been an intriguing research direction, where the models are required to generate both images and text pieces in an arbitrary order. Despite the emerging advancements in interleaved generation, the progress in its evaluation still significantly lags behind. Existing evaluation benchmarks do not support arbitrarily interleaved images and text for both inputs and outputs, and they only cover a limited number of domains and use cases. Also, current works predominantly use similarity-based metrics which fall short in assessing the quality in open-ended scenarios. To this end, we introduce InterleavedBench, the first benchmark carefully curated for the evaluation of interleaved text-and-image generation. InterleavedBench features a rich array of tasks to cover diverse real-world use cases. In addition, we present InterleavedEval, a strong reference-free metric powered by GPT-4o to deliver accurate and explainable evaluation. We carefully define five essential evaluation aspects for InterleavedEval, including text quality, perceptual quality, image coherence, text-image coherence, and helpfulness, to ensure a comprehensive and fine-grained assessment. Through extensive experiments and rigorous human evaluation, we show that our benchmark and metric can effectively evaluate the existing models with a strong correlation with human judgments surpassing previous reference-based metrics. We also provide substantial findings and insights to foster future research in interleaved generation and its evaluation.
X-Eval: Generalizable Multi-aspect Text Evaluation via Augmented Instruction Tuning with Auxiliary Evaluation Aspects
Nov 15, 2023
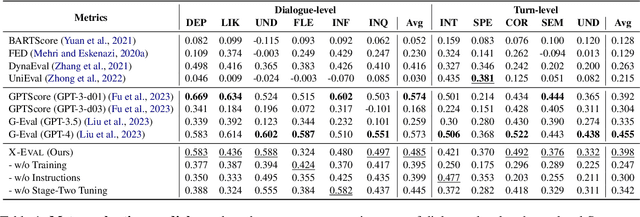
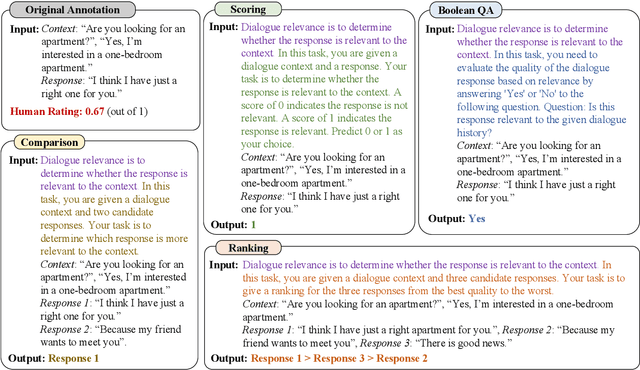
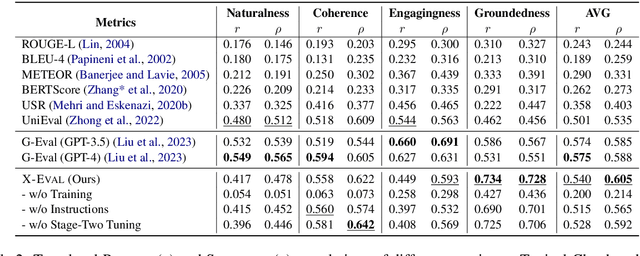
Natural Language Generation (NLG) typically involves evaluating the generated text in various aspects (e.g., consistency and naturalness) to obtain a comprehensive assessment. However, multi-aspect evaluation remains challenging as it may require the evaluator to generalize to any given evaluation aspect even if it's absent during training. In this paper, we introduce X-Eval, a two-stage instruction tuning framework to evaluate the text in both seen and unseen aspects customized by end users. X-Eval consists of two learning stages: the vanilla instruction tuning stage that improves the model's ability to follow evaluation instructions, and an enhanced instruction tuning stage that exploits the connections between fine-grained evaluation aspects to better assess text quality. To support the training of X-Eval, we collect AspectInstruct, the first instruction tuning dataset tailored for multi-aspect NLG evaluation spanning 27 diverse evaluation aspects with 65 tasks. To enhance task diversity, we devise an augmentation strategy that converts human rating annotations into diverse forms of NLG evaluation tasks, including scoring, comparison, ranking, and Boolean question answering. Extensive experiments across three essential categories of NLG tasks: dialogue generation, summarization, and data-to-text coupled with 21 aspects in meta-evaluation, demonstrate that our X-Eval enables even a lightweight language model to achieve a comparable if not higher correlation with human judgments compared to the state-of-the-art NLG evaluators, such as GPT-4.