 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaTtE-Flow: Layerwise Timestep-Expert Flow-based Transformer
Jun 08, 2025Recent advances in multimodal foundation models unifying image understanding and generation have opened exciting avenues for tackling a wide range of vision-language tasks within a single framework. Despite progress, existing unified models typically require extensive pretraining and struggle to achieve the same level of performance compared to models dedicated to each task. Additionally, many of these models suffer from slow image generation speeds, limiting their practical deployment in real-time or resource-constrained settings. In this work, we propose Layerwise Timestep-Expert Flow-based Transformer (LaTtE-Flow), a novel and efficient architecture that unifies image understanding and generation within a single multimodal model. LaTtE-Flow builds upon powerful pretrained Vision-Language Models (VLMs) to inherit strong multimodal understanding capabilities, and extends them with a novel Layerwise Timestep Experts flow-based architecture for efficient image generation. LaTtE-Flow distributes the flow-matching process across specialized groups of Transformer layers, each responsible for a distinct subset of timesteps. This design significantly improves sampling efficiency by activating only a small subset of layers at each sampling timestep. To further enhance performance, we propose a Timestep-Conditioned Residual Attention mechanism for efficient information reuse across layers. Experiments demonstrate that LaTtE-Flow achieves strong performance on multimodal understanding tasks, while achieving competitive image generation quality with around 6x faster inference speed compared to recent unified multimodal models.
R2I-Bench: Benchmarking Reasoning-Driven Text-to-Image Generation
May 29, 2025
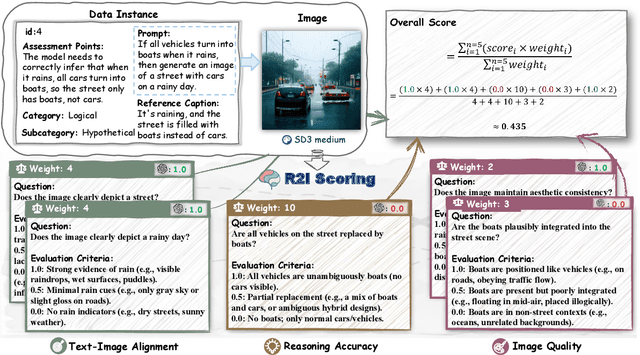
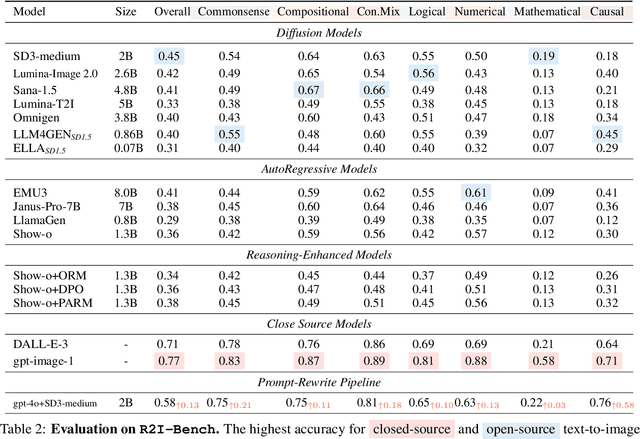

Reasoning is a fundamental capability often required in real-world text-to-image (T2I) generation, e.g., generating ``a bitten apple that has been left in the air for more than a week`` necessitates understanding temporal decay and commonsense concepts. While recent T2I models have made impressive progress in producing photorealistic images, their reasoning capability remains underdeveloped and insufficiently evaluated. To bridge this gap, we introduce R2I-Bench, a comprehensive benchmark specifically designed to rigorously assess reasoning-driven T2I generation. R2I-Bench comprises meticulously curated data instances, spanning core reasoning categories, including commonsense, mathematical, logical, compositional, numerical, causal, and concept mixing. To facilitate fine-grained evaluation, we design R2IScore, a QA-style metric based on instance-specific, reasoning-oriented evaluation questions that assess three critical dimensions: text-image alignment, reasoning accuracy, and image quality. Extensive experiments with 16 representative T2I models, including a strong pipeline-based framework that decouples reasoning and generation using the state-of-the-art language and image generation models, demonstrate consistently limited reasoning performance, highlighting the need for more robust, reasoning-aware architectures in the next generation of T2I systems. Project Page: https://r2i-bench.github.io
Lateralization LoRA: Interleaved Instruction Tuning with Modality-Specialized Adaptations
Jul 04, 2024Recent advancements in Vision-Language Models (VLMs) have led to the development of Vision-Language Generalists (VLGs) capable of understanding and generating interleaved images and text. Despite these advances, VLGs still struggle to follow user instructions for interleaved text and image generation. To address this issue, we introduce LeafInstruct, the first open-sourced interleaved instruction tuning data with over 30,000 high-quality instances across more than 10 domains. Due to the extensive size of existing VLGs, we opt for parameter-efficient tuning. However, we observe that VLGs tuned with a standard LoRA typically exhibit inferior performance in interleaved text-image generation. We attribute this problem to modality interference and the lack of modality-specialized adaptation design. Hence, we propose Lateralization LoRA, a novel modality-specialized adaptation method inspired by the concept of brain lateralization. Lateralization LoRA employs a hybrid approach, combining the traditional linear LoRA and a Convolutional LoRA for generating text and images, enabling the generation of high-quality text and images by leveraging modality-specific structures and parameter sets. We perform instruction tuning of the VLG (i.e., EMU2) using Lateralization LoRA on the LeafInstruct dataset. Extensive experiments demonstrate that EMU2 tuned with Lateralization LoRA achieve state-of-the-art performance, significantly surpassing baseline models in complex interleaved tasks.
Holistic Evaluation for Interleaved Text-and-Image Generation
Jun 20, 2024



Interleaved text-and-image generation has been an intriguing research direction, where the models are required to generate both images and text pieces in an arbitrary order. Despite the emerging advancements in interleaved generation, the progress in its evaluation still significantly lags behind. Existing evaluation benchmarks do not support arbitrarily interleaved images and text for both inputs and outputs, and they only cover a limited number of domains and use cases. Also, current works predominantly use similarity-based metrics which fall short in assessing the quality in open-ended scenarios. To this end, we introduce InterleavedBench, the first benchmark carefully curated for the evaluation of interleaved text-and-image generation. InterleavedBench features a rich array of tasks to cover diverse real-world use cases. In addition, we present InterleavedEval, a strong reference-free metric powered by GPT-4o to deliver accurate and explainable evaluation. We carefully define five essential evaluation aspects for InterleavedEval, including text quality, perceptual quality, image coherence, text-image coherence, and helpfulness, to ensure a comprehensive and fine-grained assessment. Through extensive experiments and rigorous human evaluation, we show that our benchmark and metric can effectively evaluate the existing models with a strong correlation with human judgments surpassing previous reference-based metrics. We also provide substantial findings and insights to foster future research in interleaved generation and its evaluation.
DECDM: Document Enhancement using Cycle-Consistent Diffusion Models
Nov 16, 2023



The performance of optical character recognition (OCR) heavily relies on document image quality, which is crucial for automatic document processing and document intelligence. However, most existing document enhancement methods require supervised data pairs, which raises concerns about data separation and privacy protection, and makes it challenging to adapt these methods to new domain pairs. To address these issues, we propose DECDM, an end-to-end document-level image translation method inspired by recent advances in diffusion models. Our method overcomes the limitations of paired training by independently training the source (noisy input) and target (clean output) models, making it possible to apply domain-specific diffusion models to other pairs. DECDM trains on one dataset at a time, eliminating the need to scan both datasets concurrently, and effectively preserving data privacy from the source or target domain. We also introduce simple data augmentation strategies to improve character-glyph conservation during translation. We compare DECDM with state-of-the-art methods on multiple synthetic data and benchmark datasets, such as document denoising and {\color{black}shadow} removal, and demonstrate the superiority of performance quantitatively and qualitatively.
RE$^2$: Region-Aware Relation Extraction from Visually Rich Documents
May 24, 2023Current research in form understanding predominantly relies on large pre-trained language models, necessitating extensive data for pre-training. However, the importance of layout structure (i.e., the spatial relationship between the entity blocks in the visually rich document) to relation extraction has been overlooked. In this paper, we propose REgion-Aware Relation Extraction (RE$^2$) that leverages region-level spatial structure among the entity blocks to improve their relation prediction. We design an edge-aware graph attention network to learn the interaction between entities while considering their spatial relationship defined by their region-level representations. We also introduce a constraint objective to regularize the model towards consistency with the inherent constraints of the relation extraction task. Extensive experiments across various datasets, languages and domains demonstrate the superiority of our proposed approach.