 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCE: Scalable Consistency Ensembles Make Blackbox Large Language Model Generation More Reliable
Mar 13, 2025Large language models (LLMs) have demonstrated remarkable performance, yet their diverse strengths and weaknesses prevent any single LLM from achieving dominance across all tasks. Ensembling multiple LLMs is a promising approach to generate reliable responses but conventional ensembling frameworks suffer from high computational overheads. This work introduces Scalable Consistency Ensemble (SCE), an efficient framework for ensembling LLMs by prompting consistent outputs. The SCE framework systematically evaluates and integrates outputs to produce a cohesive result through two core components: SCE-CHECK, a mechanism that gauges the consistency between response pairs via semantic equivalence; and SCE-FUSION, which adeptly merges the highest-ranked consistent responses from SCE-CHECK, to optimize collective strengths and mitigating potential weaknesses. To improve the scalability with multiple inference queries, we further propose ``{You Only Prompt Once}'' (YOPO), a novel technique that reduces the inference complexity of pairwise comparison from quadratic to constant time. We perform extensive empirical evaluations on diverse benchmark datasets to demonstrate \methodName's effectiveness. Notably, the \saccheckcomponent outperforms conventional baselines with enhanced performance and a significant reduction in computational overhead.
Automatic Prompt Optimization via Heuristic Search: A Survey
Feb 26, 2025



Recent advances in Large Language Models have led to remarkable achievements across a variety of Natural Language Processing tasks, making prompt engineering increasingly central to guiding model outputs. While manual methods can be effective, they typically rely on intuition and do not automatically refine prompts over time. In contrast, automatic prompt optimization employing heuristic-based search algorithms can systematically explore and improve prompts with minimal human oversight. This survey proposes a comprehensive taxonomy of these methods, categorizing them by where optimization occurs, what is optimized, what criteria drive the optimization, which operators generate new prompts, and which iterative search algorithms are applied. We further highlight specialized datasets and tools that support and accelerate automated prompt refinement. We conclude by discussing key open challenges pointing toward future opportunities for more robust and versatile LLM applications.
Synthetic Knowledge Ingestion: Towards Knowledge Refinement and Injection for Enhancing Large Language Models
Oct 12, 2024



Large language models (LLMs) are proficient in capturing factual knowledge across various domains. However, refining their capabilities on previously seen knowledge or integrating new knowledge from external sources remains a significant challenge. In this work, we propose a novel synthetic knowledge ingestion method called Ski, which leverages fine-grained synthesis, interleaved generation, and assemble augmentation strategies to construct high-quality data representations from raw knowledge sources. We then integrate Ski and its variations with three knowledge injection techniques: Retrieval Augmented Generation (RAG), Supervised Fine-tuning (SFT), and Continual Pre-training (CPT) to inject and refine knowledge in language models. Extensive empirical experiments are conducted on various question-answering tasks spanning finance, biomedicine, and open-generation domains to demonstrate that Ski significantly outperforms baseline methods by facilitating effective knowledge injection. We believe that our work is an important step towards enhancing the factual accuracy of LLM outputs by refining knowledge representation and injection capabilities.
Do You Know What You Are Talking About? Characterizing Query-Knowledge Relevance For Reliable Retrieval Augmented Generation
Oct 10, 2024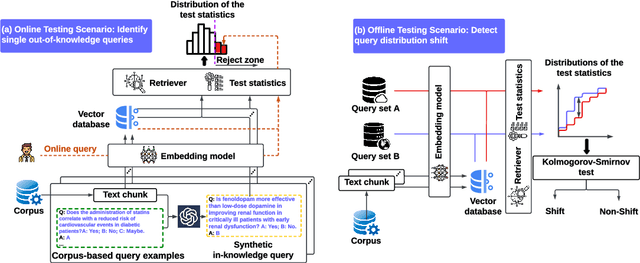
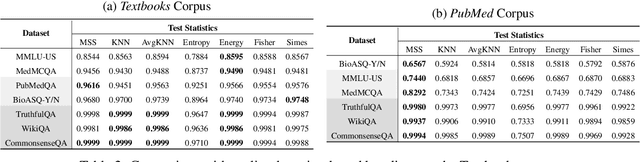
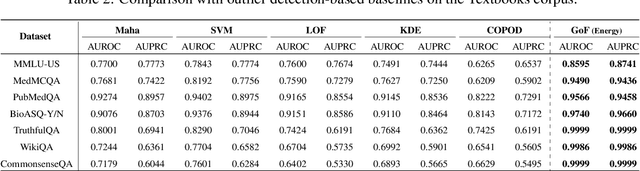
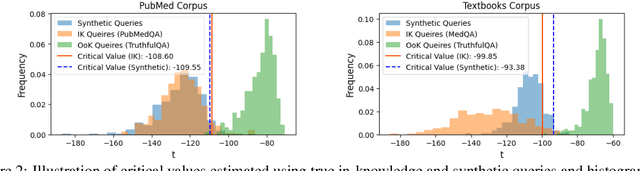
Language models (LMs) are known to suffer from hallucinations and misinformation. Retrieval augmented generation (RAG) that retrieves verifiable information from an external knowledge corpus to complement the parametric knowledge in LMs provides a tangible solution to these problems. However, the generation quality of RAG is highly dependent on the relevance between a user's query and the retrieved documents. Inaccurate responses may be generated when the query is outside of the scope of knowledge represented in the external knowledge corpus or if the information in the corpus is out-of-date. In this work, we establish a statistical framework that assesses how well a query can be answered by an RAG system by capturing the relevance of knowledge. We introduce an online testing procedure that employs goodness-of-fit (GoF) tests to inspect the relevance of each user query to detect out-of-knowledge queries with low knowledge relevance. Additionally, we develop an offline testing framework that examines a collection of user queries, aiming to detect significant shifts in the query distribution which indicates the knowledge corpus is no longer sufficiently capable of supporting the interests of the users. We demonstrate the capabilities of these strategies through a systematic evaluation on eight question-answering (QA) datasets, the results of which indicate that the new testing framework is an efficient solution to enhance the reliability of existing RAG systems.
Discriminant Distance-Aware Representation on Deterministic Uncertainty Quantification Methods
Feb 20, 2024
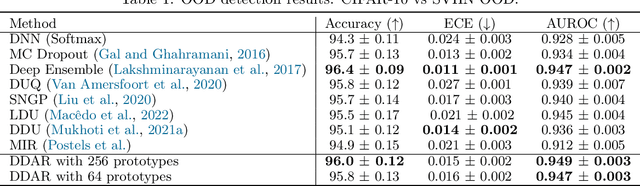

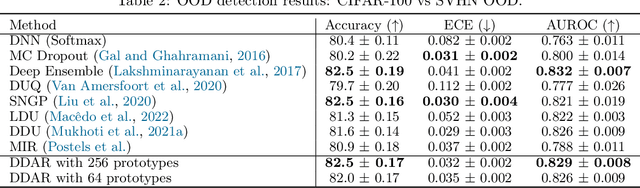
Uncertainty estimation is a crucial aspect of deploying dependable deep learning models in safety-critical systems. In this study, we introduce a novel and efficient method for deterministic uncertainty estimation called Discriminant Distance-Awareness Representation (DDAR). Our approach involves constructing a DNN model that incorporates a set of prototypes in its latent representations, enabling us to analyze valuable feature information from the input data. By leveraging a distinction maximization layer over optimal trainable prototypes, DDAR can learn a discriminant distance-awareness representation. We demonstrate that DDAR overcomes feature collapse by relaxing the Lipschitz constraint that hinders the practicality of deterministic uncertainty methods (DUMs) architectures. Our experiments show that DDAR is a flexible and architecture-agnostic method that can be easily integrated as a pluggable layer with distance-sensitive metrics, outperforming state-of-the-art uncertainty estimation methods on multiple benchmark problems.
PhaseEvo: Towards Unified In-Context Prompt Optimization for Large Language Models
Feb 17, 2024



Crafting an ideal prompt for Large Language Models (LLMs) is a challenging task that demands significant resources and expert human input. Existing work treats the optimization of prompt instruction and in-context learning examples as distinct problems, leading to sub-optimal prompt performance. This research addresses this limitation by establishing a unified in-context prompt optimization framework, which aims to achieve joint optimization of the prompt instruction and examples. However, formulating such optimization in the discrete and high-dimensional natural language space introduces challenges in terms of convergence and computational efficiency. To overcome these issues, we present PhaseEvo, an efficient automatic prompt optimization framework that combines the generative capability of LLMs with the global search proficiency of evolution algorithms. Our framework features a multi-phase design incorporating innovative LLM-based mutation operators to enhance search efficiency and accelerate convergence. We conduct an extensive evaluation of our approach across 35 benchmark tasks. The results demonstrate that PhaseEvo significantly outperforms the state-of-the-art baseline methods by a large margin whilst maintaining good efficiency.
DCR-Consistency: Divide-Conquer-Reasoning for Consistency Evaluation and Improvement of Large Language Models
Jan 04, 2024Evaluating the quality and variability of text generated by Large Language Models (LLMs) poses a significant, yet unresolved research challenge. Traditional evaluation methods, such as ROUGE and BERTScore, which measure token similarity, often fail to capture the holistic semantic equivalence. This results in a low correlation with human judgments and intuition, which is especially problematic in high-stakes applications like healthcare and finance where reliability, safety, and robust decision-making are highly critical. This work proposes DCR, an automated framework for evaluating and improving the consistency of LLM-generated texts using a divide-conquer-reasoning approach. Unlike existing LLM-based evaluators that operate at the paragraph level, our method employs a divide-and-conquer evaluator (DCE) that breaks down the paragraph-to-paragraph comparison between two generated responses into individual sentence-to-paragraph comparisons, each evaluated based on predefined criteria. To facilitate this approach, we introduce an automatic metric converter (AMC) that translates the output from DCE into an interpretable numeric score. Beyond the consistency evaluation, we further present a reason-assisted improver (RAI) that leverages the analytical reasons with explanations identified by DCE to generate new responses aimed at reducing these inconsistencies. Through comprehensive and systematic empirical analysis, we show that our approach outperforms state-of-the-art methods by a large margin (e.g., +19.3% and +24.3% on the SummEval dataset) in evaluating the consistency of LLM generation across multiple benchmarks in semantic, factual, and summarization consistency tasks. Our approach also substantially reduces nearly 90% of output inconsistencies, showing promise for effective hallucination mitigation.
DECDM: Document Enhancement using Cycle-Consistent Diffusion Models
Nov 16, 2023



The performance of optical character recognition (OCR) heavily relies on document image quality, which is crucial for automatic document processing and document intelligence. However, most existing document enhancement methods require supervised data pairs, which raises concerns about data separation and privacy protection, and makes it challenging to adapt these methods to new domain pairs. To address these issues, we propose DECDM, an end-to-end document-level image translation method inspired by recent advances in diffusion models. Our method overcomes the limitations of paired training by independently training the source (noisy input) and target (clean output) models, making it possible to apply domain-specific diffusion models to other pairs. DECDM trains on one dataset at a time, eliminating the need to scan both datasets concurrently, and effectively preserving data privacy from the source or target domain. We also introduce simple data augmentation strategies to improve character-glyph conservation during translation. We compare DECDM with state-of-the-art methods on multiple synthetic data and benchmark datasets, such as document denoising and {\color{black}shadow} removal, and demonstrate the superiority of performance quantitatively and qualitatively.
SAC$^3$: Reliable Hallucination Detection in Black-Box Language Models via Semantic-aware Cross-check Consistency
Nov 03, 2023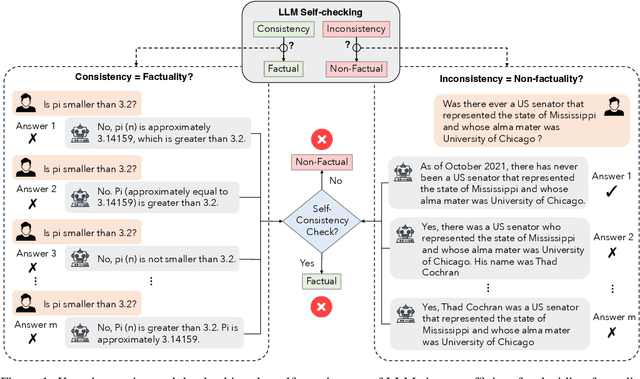
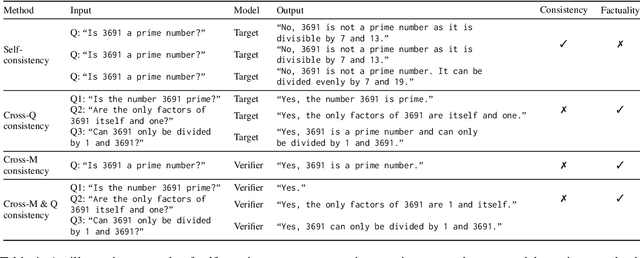

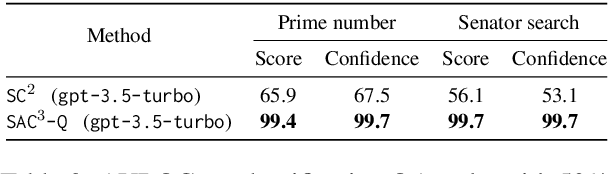
Hallucination detection is a critical step toward understanding the trustworthiness of modern language models (LMs). To achieve this goal, we re-examine existing detection approaches based on the self-consistency of LMs and uncover two types of hallucinations resulting from 1) question-level and 2) model-level, which cannot be effectively identified through self-consistency check alone. Building upon this discovery, we propose a novel sampling-based method, i.e., semantic-aware cross-check consistency (SAC$^3$) that expands on the principle of self-consistency checking. Our SAC$^3$ approach incorporates additional mechanisms to detect both question-level and model-level hallucinations by leveraging advances including semantically equivalent question perturbation and cross-model response consistency checking. Through extensive and systematic empirical analysis, we demonstrate that SAC$^3$ outperforms the state of the art in detecting both non-factual and factual statements across multiple question-answering and open-domain generation benchmarks.
Interactive Multi-fidelity Learning for Cost-effective Adaptation of Language Model with Sparse Human Supervision
Oct 31, 2023Large language models (LLMs) have demonstrated remarkable capabilities in various tasks. However, their suitability for domain-specific tasks, is limited due to their immense scale at deployment, susceptibility to misinformation, and more importantly, high data annotation costs. We propose a novel Interactive Multi-Fidelity Learning (IMFL) framework for the cost-effective development of small domain-specific LMs under limited annotation budgets. Our approach formulates the domain-specific fine-tuning process as a multi-fidelity learning problem, focusing on identifying the optimal acquisition strategy that balances between low-fidelity automatic LLM annotations and high-fidelity human annotations to maximize model performance. We further propose an exploration-exploitation query strategy that enhances annotation diversity and informativeness, incorporating two innovative designs: 1) prompt retrieval that selects in-context examples from human-annotated samples to improve LLM annotation, and 2) variable batch size that controls the order for choosing each fidelity to facilitate knowledge distillation, ultimately enhancing annotation quality. Extensive experiments on financial and medical tasks demonstrate that IMFL achieves superior performance compared with single fidelity annotations. Given a limited budget of human annotation, IMFL significantly outperforms the human annotation baselines in all four tasks and achieves very close performance as human annotations on two of the tasks. These promising results suggest that the high human annotation costs in domain-specific tasks can be significantly reduced by employing IMFL, which utilizes fewer human annotations, supplemented with cheaper and faster LLM (e.g., GPT-3.5) annotations to achieve comparable performance.