 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Pruning of Large Vision Language Models: A Comprehensive Study on Pruning Dynamics, Recovery, and Data Efficiency
Apr 27, 2026While Large Vision Language Models (LVLMs) demonstrate impressive capabilities, their substantial computational and memory requirements pose deployment challenges on resource-constrained edge devices. Current parameter reduction techniques primarily involve training LVLMs from small language models, but these methods offer limited flexibility and remain computationally intensive. We study a complementary route: compressing existing LVLMs by applying structured pruning to the language model backbone, followed by lightweight recovery training. Specifically, we investigate two structural pruning paradigms: layerwise and widthwise pruning, and pair them with supervised finetuning and knowledge distillation on logits and hidden states. Additionally, we assess the feasibility of conducting recovery training with only a small fraction of the available data. Our results show that widthwise pruning generally maintains better performance in low-resource scenarios, where computational resources are limited or there is insufficient finetuning data. As for the recovery training, finetuning only the multimodal projector is sufficient at small compression levels. Furthermore, a combination of supervised finetuning and hidden-state distillation yields optimal recovery across various pruning levels. Notably, effective recovery can be achieved using just 5% of the original data, while retaining over 95% of the original performance. Through empirical study on three representative LVLM families ranging from 3B to 7B parameters, this study offers actionable insights for practitioners to compress LVLMs without extensive computation resources or sufficient data. The code base is available at https://github.com/YiranHuangIrene/VLMCompression.git.
Dissecting Multimodal In-Context Learning: Modality Asymmetries and Circuit Dynamics in modern Transformers
Jan 28, 2026Transformer-based multimodal large language models often exhibit in-context learning (ICL) abilities. Motivated by this phenomenon, we ask: how do transformers learn to associate information across modalities from in-context examples? We investigate this question through controlled experiments on small transformers trained on synthetic classification tasks, enabling precise manipulation of data statistics and model architecture. We begin by revisiting core principles of unimodal ICL in modern transformers. While several prior findings replicate, we find that Rotary Position Embeddings (RoPE) increases the data complexity threshold for ICL. Extending to the multimodal setting reveals a fundamental learning asymmetry: when pretrained on high-diversity data from a primary modality, surprisingly low data complexity in the secondary modality suffices for multimodal ICL to emerge. Mechanistic analysis shows that both settings rely on an induction-style mechanism that copies labels from matching in-context exemplars; multimodal training refines and extends these circuits across modalities. Our findings provide a mechanistic foundation for understanding multimodal ICL in modern transformers and introduce a controlled testbed for future investigation.
BrainATCL: Adaptive Temporal Brain Connectivity Learning for Functional Link Prediction and Age Estimation
Aug 09, 2025Functional Magnetic Resonance Imaging (fMRI) is an imaging technique widely used to study human brain activity. fMRI signals in areas across the brain transiently synchronise and desynchronise their activity in a highly structured manner, even when an individual is at rest. These functional connectivity dynamics may be related to behaviour and neuropsychiatric disease. To model these dynamics, temporal brain connectivity representations are essential, as they reflect evolving interactions between brain regions and provide insight into transient neural states and network reconfigurations. However, conventional graph neural networks (GNNs) often struggle to capture long-range temporal dependencies in dynamic fMRI data. To address this challenge, we propose BrainATCL, an unsupervised, nonparametric framework for adaptive temporal brain connectivity learning, enabling functional link prediction and age estimation. Our method dynamically adjusts the lookback window for each snapshot based on the rate of newly added edges. Graph sequences are subsequently encoded using a GINE-Mamba2 backbone to learn spatial-temporal representations of dynamic functional connectivity in resting-state fMRI data of 1,000 participants from the Human Connectome Project. To further improve spatial modeling, we incorporate brain structure and function-informed edge attributes, i.e., the left/right hemispheric identity and subnetwork membership of brain regions, enabling the model to capture biologically meaningful topological patterns. We evaluate our BrainATCL on two tasks: functional link prediction and age estimation. The experimental results demonstrate superior performance and strong generalization, including in cross-session prediction scenarios.
Investigating Structural Pruning and Recovery Techniques for Compressing Multimodal Large Language Models: An Empirical Study
Jul 28, 2025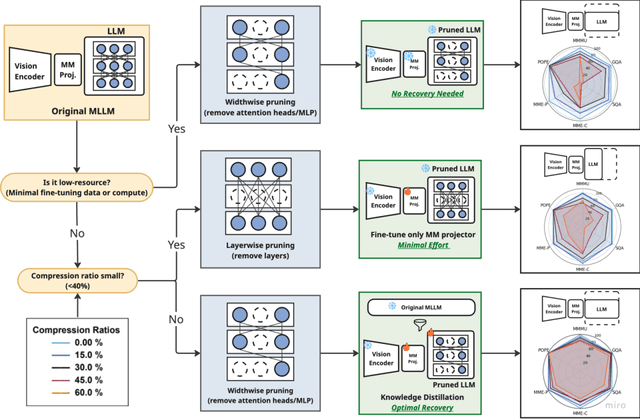
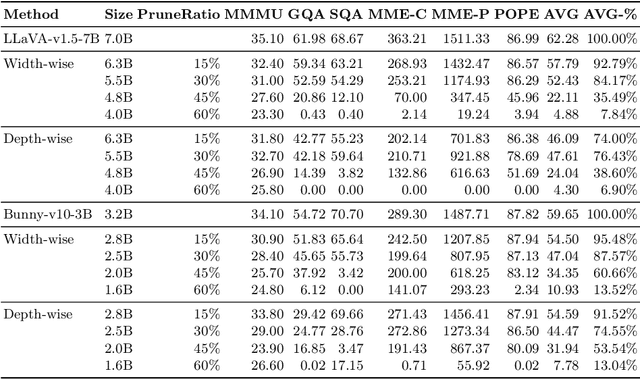
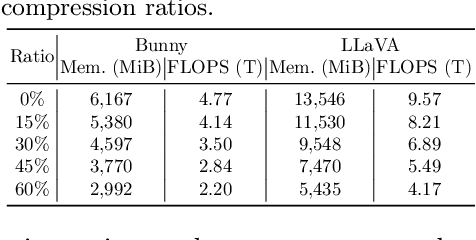
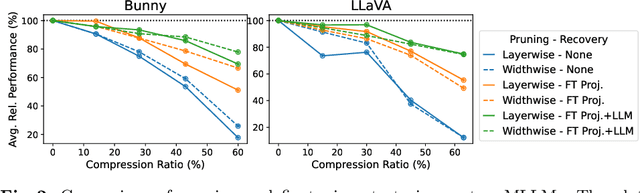
While Multimodal Large Language Models (MLLMs) demonstrate impressive capabilities, their substantial computational and memory requirements pose significant barriers to practical deployment. Current parameter reduction techniques primarily involve training MLLMs from Small Language Models (SLMs), but these methods offer limited flexibility and remain computationally intensive. To address this gap, we propose to directly compress existing MLLMs through structural pruning combined with efficient recovery training. Specifically, we investigate two structural pruning paradigms--layerwise and widthwise pruning--applied to the language model backbone of MLLMs, alongside supervised finetuning and knowledge distillation. Additionally, we assess the feasibility of conducting recovery training with only a small fraction of the available data. Our results show that widthwise pruning generally maintains better performance in low-resource scenarios with limited computational resources or insufficient finetuning data. As for the recovery training, finetuning only the multimodal projector is sufficient at small compression levels (< 20%). Furthermore, a combination of supervised finetuning and hidden-state distillation yields optimal recovery across various pruning levels. Notably, effective recovery can be achieved with as little as 5% of the original training data, while retaining over 95% of the original performance. Through empirical study on two representative MLLMs, i.e., LLaVA-v1.5-7B and Bunny-v1.0-3B, this study offers actionable insights for practitioners aiming to compress MLLMs effectively without extensive computation resources or sufficient data.
DD-Ranking: Rethinking the Evaluation of Dataset Distillation
May 19, 2025



In recent years, dataset distillation has provided a reliable solution for data compression, where models trained on the resulting smaller synthetic datasets achieve performance comparable to those trained on the original datasets. To further improve the performance of synthetic datasets, various training pipelines and optimization objectives have been proposed, greatly advancing the field of dataset distillation. Recent decoupled dataset distillation methods introduce soft labels and stronger data augmentation during the post-evaluation phase and scale dataset distillation up to larger datasets (e.g., ImageNet-1K). However, this raises a question: Is accuracy still a reliable metric to fairly evaluate dataset distillation methods? Our empirical findings suggest that the performance improvements of these methods often stem from additional techniques rather than the inherent quality of the images themselves, with even randomly sampled images achieving superior results. Such misaligned evaluation settings severely hinder the development of DD. Therefore, we propose DD-Ranking, a unified evaluation framework, along with new general evaluation metrics to uncover the true performance improvements achieved by different methods. By refocusing on the actual information enhancement of distilled datasets, DD-Ranking provides a more comprehensive and fair evaluation standard for future research advancements.
Efficient Human-in-the-Loop Active Learning: A Novel Framework for Data Labeling in AI Systems
Dec 31, 2024



Modern AI algorithms require labeled data. In real world, majority of data are unlabeled. Labeling the data are costly. this is particularly true for some areas requiring special skills, such as reading radiology images by physicians. To most efficiently use expert's time for the data labeling, one promising approach is human-in-the-loop active learning algorithm. In this work, we propose a novel active learning framework with significant potential for application in modern AI systems. Unlike the traditional active learning methods, which only focus on determining which data point should be labeled, our framework also introduces an innovative perspective on incorporating different query scheme. We propose a model to integrate the information from different types of queries. Based on this model, our active learning frame can automatically determine how the next question is queried. We further developed a data driven exploration and exploitation framework into our active learning method. This method can be embedded in numerous active learning algorithms. Through simulations on five real-world datasets, including a highly complex real image task, our proposed active learning framework exhibits higher accuracy and lower loss compared to other methods.
Revealing and Reducing Gender Biases in Vision and Language Assistants (VLAs)
Oct 25, 2024



Pre-trained large language models (LLMs) have been reliably integrated with visual input for multimodal tasks. The widespread adoption of instruction-tuned image-to-text vision-language assistants (VLAs) like LLaVA and InternVL necessitates evaluating gender biases. We study gender bias in 22 popular open-source VLAs with respect to personality traits, skills, and occupations. Our results show that VLAs replicate human biases likely present in the data, such as real-world occupational imbalances. Similarly, they tend to attribute more skills and positive personality traits to women than to men, and we see a consistent tendency to associate negative personality traits with men. To eliminate the gender bias in these models, we find that finetuning-based debiasing methods achieve the best tradeoff between debiasing and retaining performance on downstream tasks. We argue for pre-deploying gender bias assessment in VLAs and motivate further development of debiasing strategies to ensure equitable societal outcomes.
Synthetic Knowledge Ingestion: Towards Knowledge Refinement and Injection for Enhancing Large Language Models
Oct 12, 2024



Large language models (LLMs) are proficient in capturing factual knowledge across various domains. However, refining their capabilities on previously seen knowledge or integrating new knowledge from external sources remains a significant challenge. In this work, we propose a novel synthetic knowledge ingestion method called Ski, which leverages fine-grained synthesis, interleaved generation, and assemble augmentation strategies to construct high-quality data representations from raw knowledge sources. We then integrate Ski and its variations with three knowledge injection techniques: Retrieval Augmented Generation (RAG), Supervised Fine-tuning (SFT), and Continual Pre-training (CPT) to inject and refine knowledge in language models. Extensive empirical experiments are conducted on various question-answering tasks spanning finance, biomedicine, and open-generation domains to demonstrate that Ski significantly outperforms baseline methods by facilitating effective knowledge injection. We believe that our work is an important step towards enhancing the factual accuracy of LLM outputs by refining knowledge representation and injection capabilities.
Explainable Deep Learning Framework for Human Activity Recognition
Aug 21, 2024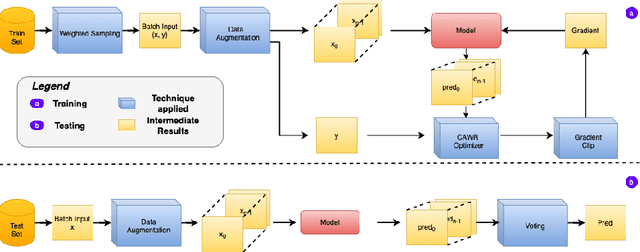
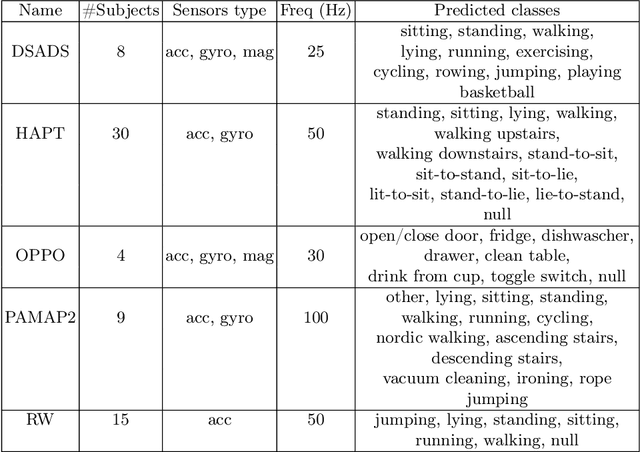
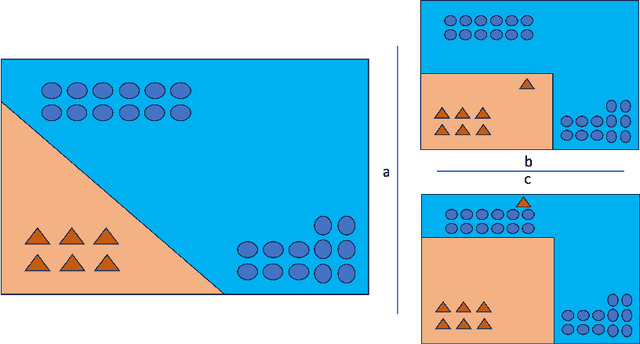
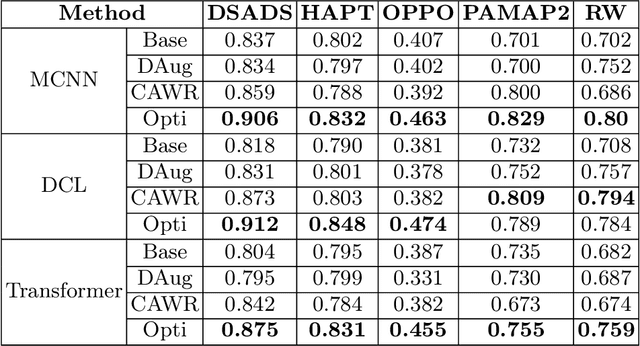
In the realm of human activity recognition (HAR), the integration of explainable Artificial Intelligence (XAI) emerges as a critical necessity to elucidate the decision-making processes of complex models, fostering transparency and trust. Traditional explanatory methods like Class Activation Mapping (CAM) and attention mechanisms, although effective in highlighting regions vital for decisions in various contexts, prove inadequate for HAR. This inadequacy stems from the inherently abstract nature of HAR data, rendering these explanations obscure. In contrast, state-of-th-art post-hoc interpretation techniques for time series can explain the model from other perspectives. However, this requires extra effort. It usually takes 10 to 20 seconds to generate an explanation. To overcome these challenges, we proposes a novel, model-agnostic framework that enhances both the interpretability and efficacy of HAR models through the strategic use of competitive data augmentation. This innovative approach does not rely on any particular model architecture, thereby broadening its applicability across various HAR models. By implementing competitive data augmentation, our framework provides intuitive and accessible explanations of model decisions, thereby significantly advancing the interpretability of HAR systems without compromising on performance.
Towards Automatic Evaluation for LLMs' Clinical Capabilities: Metric, Data, and Algorithm
Mar 25, 2024



Large language models (LLMs) are gaining increasing interests to improve clinical efficiency for medical diagnosis, owing to their unprecedented performance in modelling natural language. Ensuring the safe and reliable clinical applications, the evaluation of LLMs indeed becomes critical for better mitigating the potential risks, e.g., hallucinations. However, current evaluation methods heavily rely on labor-intensive human participation to achieve human-preferred judgements. To overcome this challenge, we propose an automatic evaluation paradigm tailored to assess the LLMs' capabilities in delivering clinical services, e.g., disease diagnosis and treatment. The evaluation paradigm contains three basic elements: metric, data, and algorithm. Specifically, inspired by professional clinical practice pathways, we formulate a LLM-specific clinical pathway (LCP) to define the clinical capabilities that a doctor agent should possess. Then, Standardized Patients (SPs) from the medical education are introduced as the guideline for collecting medical data for evaluation, which can well ensure the completeness of the evaluation procedure. Leveraging these steps, we develop a multi-agent framework to simulate the interactive environment between SPs and a doctor agent, which is equipped with a Retrieval-Augmented Evaluation (RAE) to determine whether the behaviors of a doctor agent are in accordance with LCP. The above paradigm can be extended to any similar clinical scenarios to automatically evaluate the LLMs' medical capabilities. Applying such paradigm, we construct an evaluation benchmark in the field of urology, including a LCP, a SPs dataset, and an automated RAE. Extensive experiments are conducted to demonstrate the effectiveness of the proposed approach, providing more insights for LLMs' safe and reliable deployments in clinical practice.