 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing mmWave Radar Point Cloud via Visual-inertial Supervision
Apr 26, 2024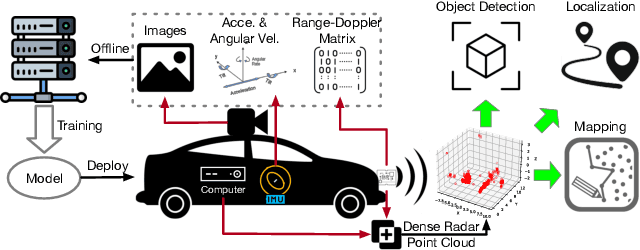
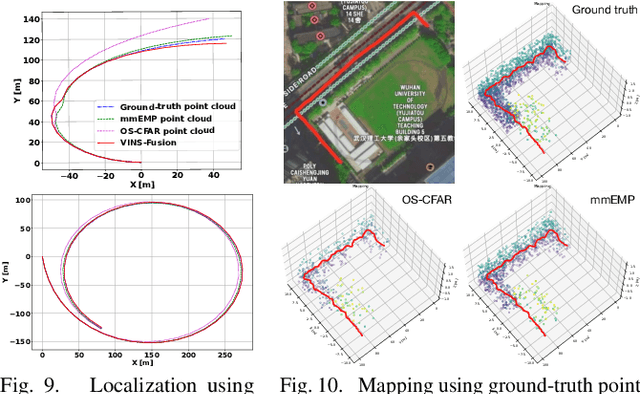
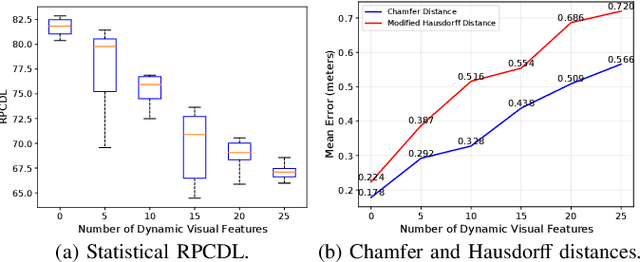
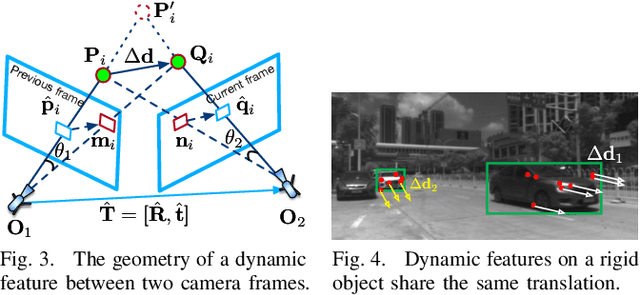
Complementary to prevalent LiDAR and camera systems, millimeter-wave (mmWave) radar is robust to adverse weather conditions like fog, rainstorms, and blizzards but offers sparse point clouds. Current techniques enhance the point cloud by the supervision of LiDAR's data. However, high-performance LiDAR is notably expensive and is not commonly available on vehicles. This paper presents mmEMP, a supervised learning approach that enhances radar point clouds using a low-cost camera and an inertial measurement unit (IMU), enabling crowdsourcing training data from commercial vehicles. Bringing the visual-inertial (VI) supervision is challenging due to the spatial agnostic of dynamic objects. Moreover, spurious radar points from the curse of RF multipath make robots misunderstand the scene. mmEMP first devises a dynamic 3D reconstruction algorithm that restores the 3D positions of dynamic features. Then, we design a neural network that densifies radar data and eliminates spurious radar points. We build a new dataset in the real world. Extensive experiments show that mmEMP achieves competitive performance compared with the SOTA approach training by LiDAR's data. In addition, we use the enhanced point cloud to perform object detection, localization, and mapping to demonstrate mmEMP's effectiveness.
RJUA-MedDQA: A Multimodal Benchmark for Medical Document Question Answering and Clinical Reasoning
Feb 19, 2024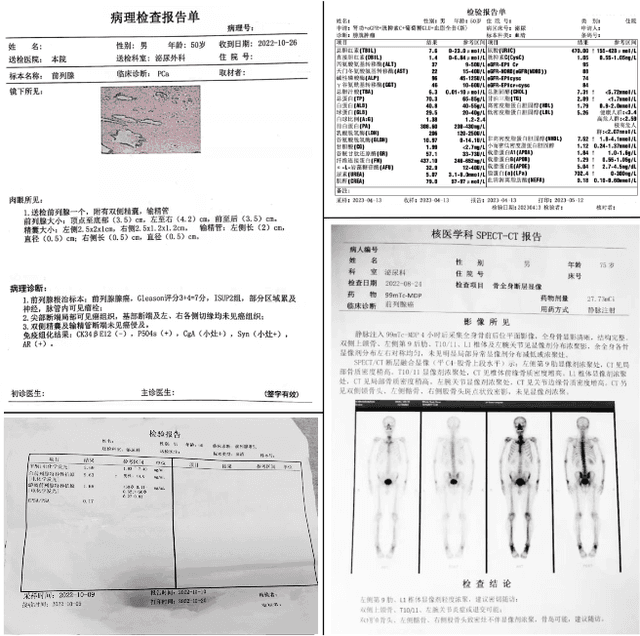
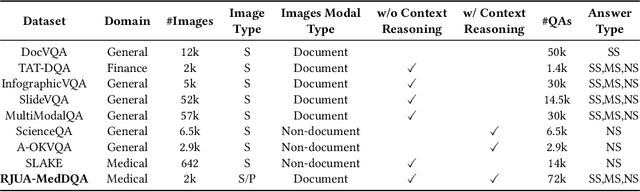
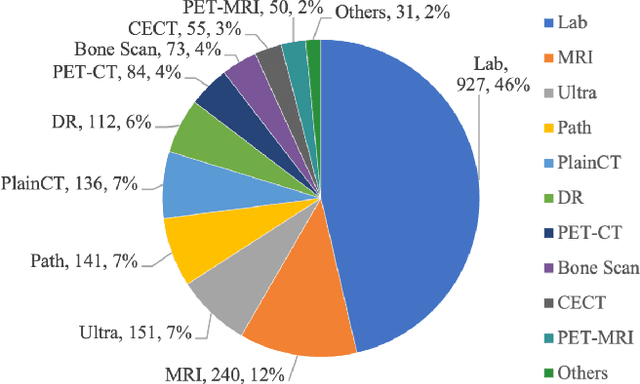

Recent advancements in Large Language Models (LLMs) and Large Multi-modal Models (LMMs) have shown potential in various medical applications, such as Intelligent Medical Diagnosis. Although impressive results have been achieved, we find that existing benchmarks do not reflect the complexity of real medical reports and specialized in-depth reasoning capabilities. In this work, we introduced RJUA-MedDQA, a comprehensive benchmark in the field of medical specialization, which poses several challenges: comprehensively interpreting imgage content across diverse challenging layouts, possessing numerical reasoning ability to identify abnormal indicators and demonstrating clinical reasoning ability to provide statements of disease diagnosis, status and advice based on medical contexts. We carefully design the data generation pipeline and proposed the Efficient Structural Restoration Annotation (ESRA) Method, aimed at restoring textual and tabular content in medical report images. This method substantially enhances annotation efficiency, doubling the productivity of each annotator, and yields a 26.8% improvement in accuracy. We conduct extensive evaluations, including few-shot assessments of 5 LMMs which are capable of solving Chinese medical QA tasks. To further investigate the limitations and potential of current LMMs, we conduct comparative experiments on a set of strong LLMs by using image-text generated by ESRA method. We report the performance of baselines and offer several observations: (1) The overall performance of existing LMMs is still limited; however LMMs more robust to low-quality and diverse-structured images compared to LLMs. (3) Reasoning across context and image content present significant challenges. We hope this benchmark helps the community make progress on these challenging tasks in multi-modal medical document understanding and facilitate its application in healthcare.
OrchMoE: Efficient Multi-Adapter Learning with Task-Skill Synergy
Jan 19, 2024We advance the field of Parameter-Efficient Fine-Tuning (PEFT) with our novel multi-adapter method, OrchMoE, which capitalizes on modular skill architecture for enhanced forward transfer in neural networks. Unlike prior models that depend on explicit task identification inputs, OrchMoE automatically discerns task categories, streamlining the learning process. This is achieved through an integrated mechanism comprising an Automatic Task Classification module and a Task-Skill Allocation module, which collectively deduce task-specific classifications and tailor skill allocation matrices. Our extensive evaluations on the 'Super Natural Instructions' dataset, featuring 1,600 diverse instructional tasks, indicate that OrchMoE substantially outperforms comparable multi-adapter baselines in terms of both performance and sample utilization efficiency, all while operating within the same parameter constraints. These findings suggest that OrchMoE offers a significant leap forward in multi-task learning efficiency.
GACE: Learning Graph-Based Cross-Page Ads Embedding For Click-Through Rate Prediction
Jan 15, 2024Predicting click-through rate (CTR) is the core task of many ads online recommendation systems, which helps improve user experience and increase platform revenue. In this type of recommendation system, we often encounter two main problems: the joint usage of multi-page historical advertising data and the cold start of new ads. In this paper, we proposed GACE, a graph-based cross-page ads embedding generation method. It can warm up and generate the representation embedding of cold-start and existing ads across various pages. Specifically, we carefully build linkages and a weighted undirected graph model considering semantic and page-type attributes to guide the direction of feature fusion and generation. We designed a variational auto-encoding task as pre-training module and generated embedding representations for new and old ads based on this task. The results evaluated in the public dataset AliEC from RecBole and the real-world industry dataset from Alipay show that our GACE method is significantly superior to the SOTA method. In the online A/B test, the click-through rate on three real-world pages from Alipay has increased by 3.6%, 2.13%, and 3.02%, respectively. Especially in the cold-start task, the CTR increased by 9.96%, 7.51%, and 8.97%, respectively.
Customizable Combination of Parameter-Efficient Modules for Multi-Task Learning
Dec 06, 2023



Modular and composable transfer learning is an emerging direction in the field of Parameter Efficient Fine-Tuning, as it enables neural networks to better organize various aspects of knowledge, leading to improved cross-task generalization. In this paper, we introduce a novel approach Customized Polytropon C-Poly that combines task-common skills and task-specific skills, while the skill parameters being highly parameterized using low-rank techniques. Each task is associated with a customizable number of exclusive specialized skills and also benefits from skills shared with peer tasks. A skill assignment matrix is jointly learned. To evaluate our approach, we conducted extensive experiments on the Super-NaturalInstructions and the SuperGLUE benchmarks. Our findings demonstrate that C-Poly outperforms fully-shared, task-specific, and skill-indistinguishable baselines, significantly enhancing the sample efficiency in multi-task learning scenarios.
From Beginner to Expert: Modeling Medical Knowledge into General LLMs
Dec 02, 2023



Recently, large language model (LLM) based artificial intelligence (AI) systems have demonstrated remarkable capabilities in natural language understanding and generation. However, these models face a significant challenge when it comes to sensitive applications, such as reasoning over medical knowledge and answering medical questions in a physician-like manner. Prior studies attempted to overcome this challenge by increasing the model size (>100B) to learn more general medical knowledge, while there is still room for improvement in LLMs with smaller-scale model sizes (<100B). In this work, we start from a pre-trained general LLM model (AntGLM-10B) and fine-tune it from a medical beginner towards a medical expert (called AntGLM-Med-10B), which leverages a 3-stage optimization procedure, \textit{i.e.}, general medical knowledge injection, medical domain instruction tuning, and specific medical task adaptation. Our contributions are threefold: (1) We specifically investigate how to adapt a pre-trained general LLM in medical domain, especially for a specific medical task. (2) We collect and construct large-scale medical datasets for each stage of the optimization process. These datasets encompass various data types and tasks, such as question-answering, medical reasoning, multi-choice questions, and medical conversations. (3) Specifically for multi-choice questions in the medical domain, we propose a novel Verification-of-Choice approach for prompting engineering, which significantly enhances the reasoning ability of LLMs. Remarkably, by combining the above approaches, our AntGLM-Med-10B model can outperform the most of LLMs on PubMedQA, including both general and medical LLMs, even when these LLMs have larger model size.