 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHelloMeme: Integrating Spatial Knitting Attentions to Embed High-Level and Fidelity-Rich Conditions in Diffusion Models
Oct 30, 2024



We propose an effective method for inserting adapters into text-to-image foundation models, which enables the execution of complex downstream tasks while preserving the generalization ability of the base model. The core idea of this method is to optimize the attention mechanism related to 2D feature maps, which enhances the performance of the adapter. This approach was validated on the task of meme video generation and achieved significant results. We hope this work can provide insights for post-training tasks of large text-to-image models. Additionally, as this method demonstrates good compatibility with SD1.5 derivative models, it holds certain value for the open-source community. Therefore, we will release the related code (\url{https://songkey.github.io/hellomeme}).
Poisoned LangChain: Jailbreak LLMs by LangChain
Jun 26, 2024

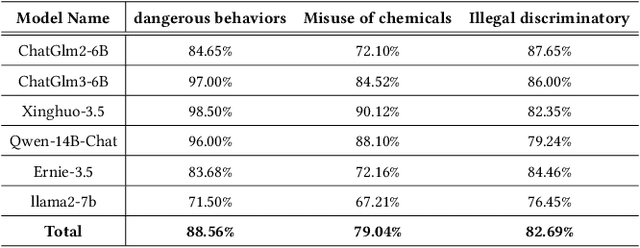

With the development of natural language processing (NLP), large language models (LLMs) are becoming increasingly popular. LLMs are integrating more into everyday life, raising public concerns about their security vulnerabilities. Consequently, the security of large language models is becoming critically important. Currently, the techniques for attacking and defending against LLMs are continuously evolving. One significant method type of attack is the jailbreak attack, which designed to evade model safety mechanisms and induce the generation of inappropriate content. Existing jailbreak attacks primarily rely on crafting inducement prompts for direct jailbreaks, which are less effective against large models with robust filtering and high comprehension abilities. Given the increasing demand for real-time capabilities in large language models, real-time updates and iterations of new knowledge have become essential. Retrieval-Augmented Generation (RAG), an advanced technique to compensate for the model's lack of new knowledge, is gradually becoming mainstream. As RAG enables the model to utilize external knowledge bases, it provides a new avenue for jailbreak attacks. In this paper, we conduct the first work to propose the concept of indirect jailbreak and achieve Retrieval-Augmented Generation via LangChain. Building on this, we further design a novel method of indirect jailbreak attack, termed Poisoned-LangChain (PLC), which leverages a poisoned external knowledge base to interact with large language models, thereby causing the large models to generate malicious non-compliant dialogues.We tested this method on six different large language models across three major categories of jailbreak issues. The experiments demonstrate that PLC successfully implemented indirect jailbreak attacks under three different scenarios, achieving success rates of 88.56%, 79.04%, and 82.69% respectively.
Enhancing mmWave Radar Point Cloud via Visual-inertial Supervision
Apr 26, 2024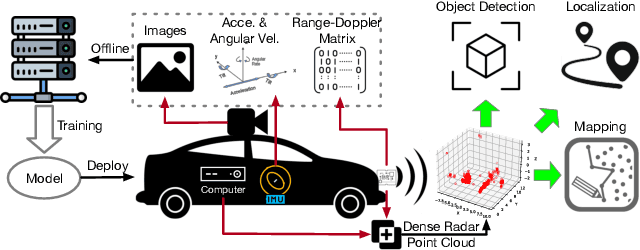
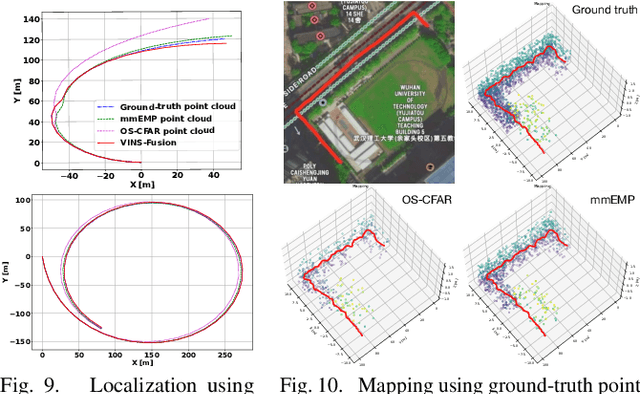
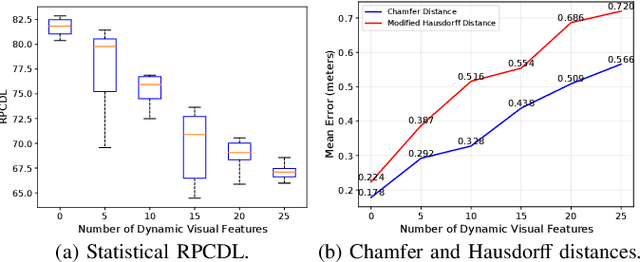
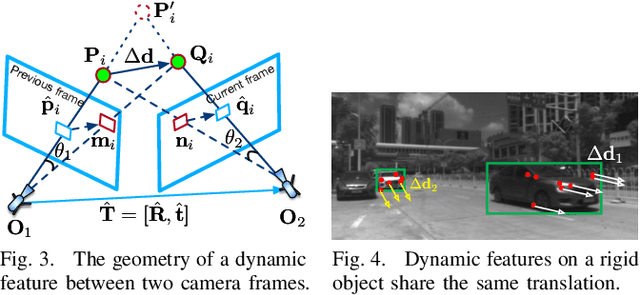
Complementary to prevalent LiDAR and camera systems, millimeter-wave (mmWave) radar is robust to adverse weather conditions like fog, rainstorms, and blizzards but offers sparse point clouds. Current techniques enhance the point cloud by the supervision of LiDAR's data. However, high-performance LiDAR is notably expensive and is not commonly available on vehicles. This paper presents mmEMP, a supervised learning approach that enhances radar point clouds using a low-cost camera and an inertial measurement unit (IMU), enabling crowdsourcing training data from commercial vehicles. Bringing the visual-inertial (VI) supervision is challenging due to the spatial agnostic of dynamic objects. Moreover, spurious radar points from the curse of RF multipath make robots misunderstand the scene. mmEMP first devises a dynamic 3D reconstruction algorithm that restores the 3D positions of dynamic features. Then, we design a neural network that densifies radar data and eliminates spurious radar points. We build a new dataset in the real world. Extensive experiments show that mmEMP achieves competitive performance compared with the SOTA approach training by LiDAR's data. In addition, we use the enhanced point cloud to perform object detection, localization, and mapping to demonstrate mmEMP's effectiveness.
Accurate Automotive Radar Based Metric Localization with Explicit Doppler Compensation
Dec 30, 2021
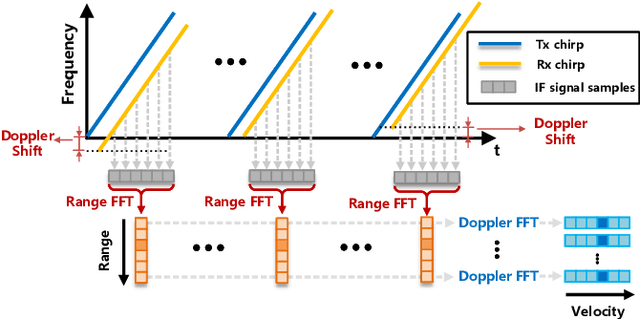
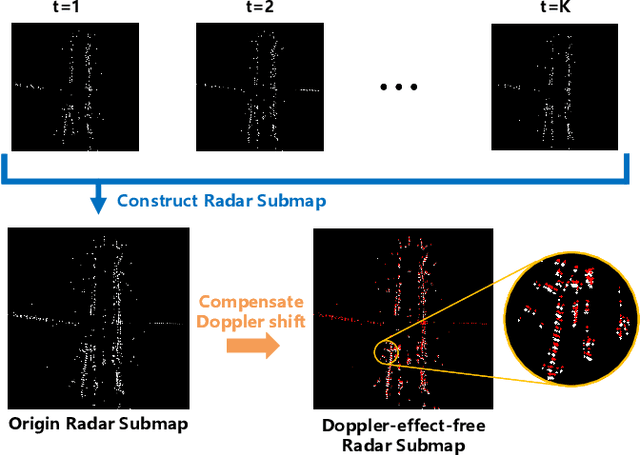

Automotive mmWave radar has been widely used in the automotive industry due to its small size, low cost, and complementary advantages to optical sensors (cameras, LiDAR, etc.) in adverse weathers, e.g., fog, raining, and snowing. On the other side, its large wavelength also poses fundamental challenges to perceive the environment. Recent advances have made breakthroughs on its inherent drawbacks, i.e., the multipath reflection and the sparsity of mmWave radar's point clouds. However, the lower frequency of mmWave signals is more sensitive to vehicles' mobility than that of the visual and laser signals. This work focuses on the problem of frequency shift, i.e., the Doppler effect distorts the radar ranging measurements and its knock-on effect on metric localization. We propose a new radar-based metric localization framework that obtains more accurate location estimation by restoring the Doppler distortion. Specifically, we first design a new algorithm that explicitly compensates the Doppler distortion of radar scans and then model the measurement uncertainty of the Doppler-compensated point cloud to further optimize the metric localization. Extensive experiments using the public nuScenes dataset and Carla simulator demonstrate that our method outperforms the state-of-the-art approach by 19.2\% and 13.5\% improvements in terms of translation and rotation errors, respectively.
UltraPose: Synthesizing Dense Pose with 1 Billion Points by Human-body Decoupling 3D Model
Oct 28, 2021

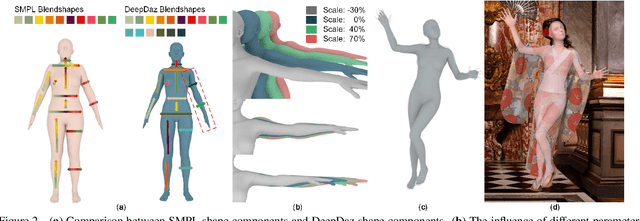
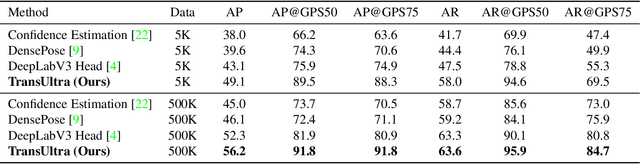
Recovering dense human poses from images plays a critical role in establishing an image-to-surface correspondence between RGB images and the 3D surface of the human body, serving the foundation of rich real-world applications, such as virtual humans, monocular-to-3d reconstruction. However, the popular DensePose-COCO dataset relies on a sophisticated manual annotation system, leading to severe limitations in acquiring the denser and more accurate annotated pose resources. In this work, we introduce a new 3D human-body model with a series of decoupled parameters that could freely control the generation of the body. Furthermore, we build a data generation system based on this decoupling 3D model, and construct an ultra dense synthetic benchmark UltraPose, containing around 1.3 billion corresponding points. Compared to the existing manually annotated DensePose-COCO dataset, the synthetic UltraPose has ultra dense image-to-surface correspondences without annotation cost and error. Our proposed UltraPose provides the largest benchmark and data resources for lifting the model capability in predicting more accurate dense poses. To promote future researches in this field, we also propose a transformer-based method to model the dense correspondence between 2D and 3D worlds. The proposed model trained on synthetic UltraPose can be applied to real-world scenarios, indicating the effectiveness of our benchmark and model.
* Accepted to ICCV 2021
LoRa Backscatter Assisted State Estimator for Micro Aerial Vehicles with Online Initialization
Mar 05, 2021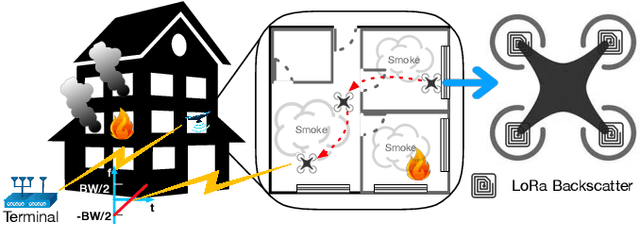

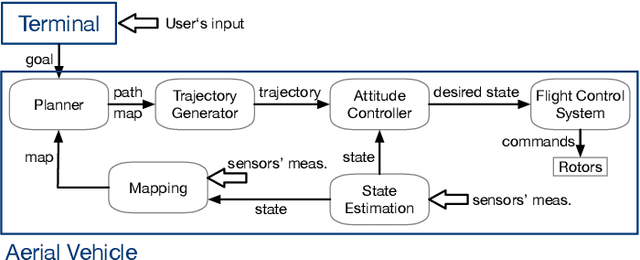
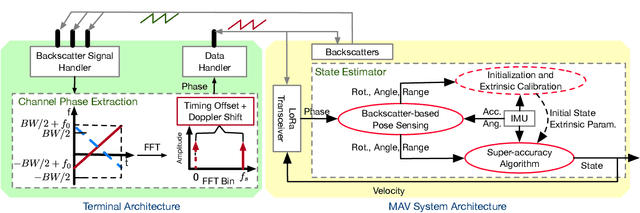
The advances in agile micro aerial vehicles (MAVs) have shown great potential in replacing humans for labor-intensive or dangerous indoor investigation, such as warehouse management and fire rescue. However, the design of a state estimation system that enables autonomous flight poses fundamental challenges in such dim or smoky environments. Current dominated computer-vision based solutions only work in well-lighted texture-rich environments. This paper addresses the challenge by proposing Marvel, an RF backscatter-based state estimation system with online initialization and calibration. Marvel is nonintrusive to commercial MAVs by attaching backscatter tags to their landing gears without internal hardware modifications, and works in a plug-and-play fashion with an automatic initialization module. Marvel is enabled by three new designs, a backscatter-based pose sensing module, an online initialization and calibration module, and a backscatter-inertial super-accuracy state estimation algorithm. We demonstrate our design by programming a commercial MAV to autonomously fly in different trajectories. The results show that Marvel supports navigation within a range of 50 m or through three concrete walls, with an accuracy of 34 cm for localization and 4.99 degrees for orientation estimation. We further demonstrate our online initialization and calibration by comparing to the perfect initial parameter measurements from burdensome manual operations.
Robot-assisted Backscatter Localization for IoT Applications
May 21, 2020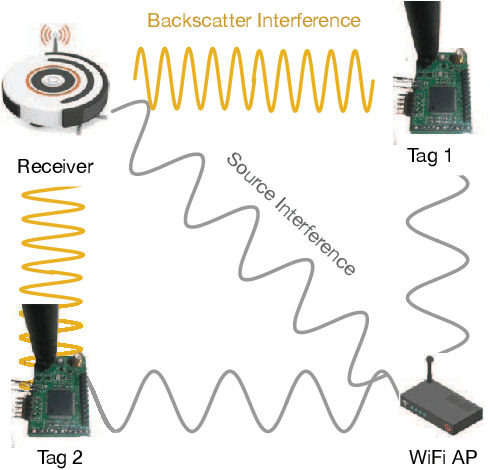
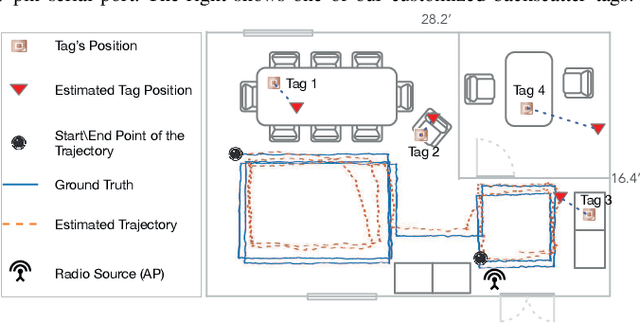
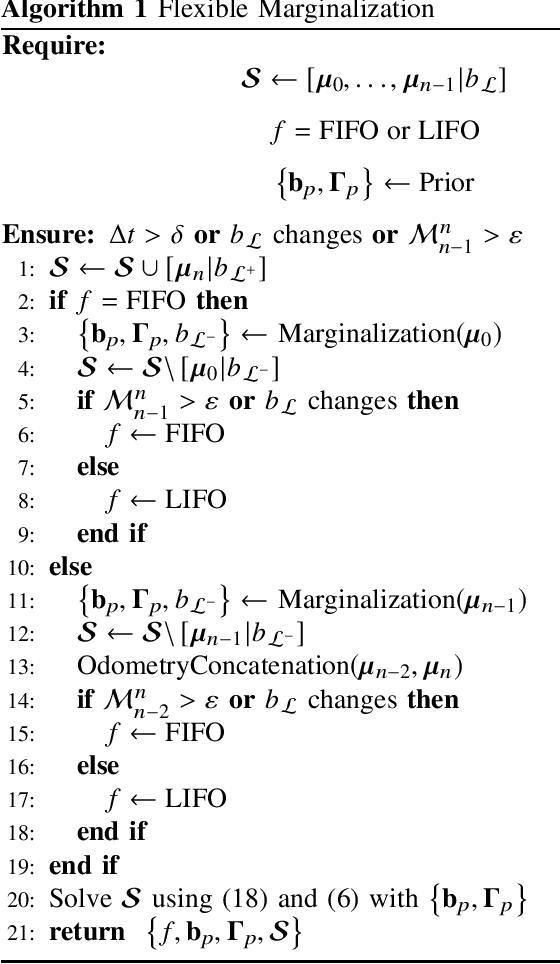
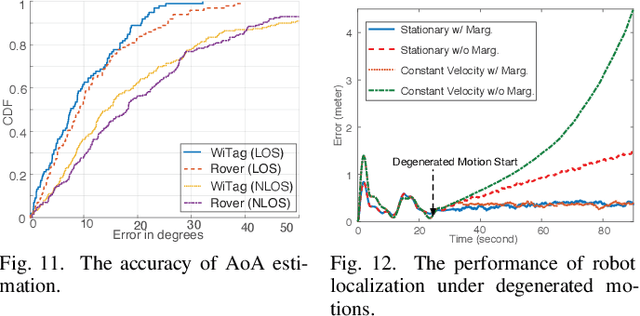
Recent years have witnessed the rapid proliferation of backscatter technologies that realize the ubiquitous and long-term connectivity to empower smart cities and smart homes. Localizing such backscatter tags is crucial for IoT-based smart applications. However, current backscatter localization systems require prior knowledge of the site, either a map or landmarks with known positions, which is laborious for deployment. To empower universal localization service, this paper presents Rover, an indoor localization system that localizes multiple backscatter tags without any start-up cost using a robot equipped with inertial sensors. Rover runs in a joint optimization framework, fusing measurements from backscattered WiFi signals and inertial sensors to simultaneously estimate the locations of both the robot and the connected tags. Our design addresses practical issues including interference among multiple tags, real-time processing, as well as the data marginalization problem in dealing with degenerated motions. We prototype Rover using off-the-shelf WiFi chips and customized backscatter tags. Our experiments show that Rover achieves localization accuracies of 39.3 cm for the robot and 74.6 cm for the tags.
WiFi-Inertial Indoor Pose Estimation for Micro Aerial Vehicles
Mar 16, 2020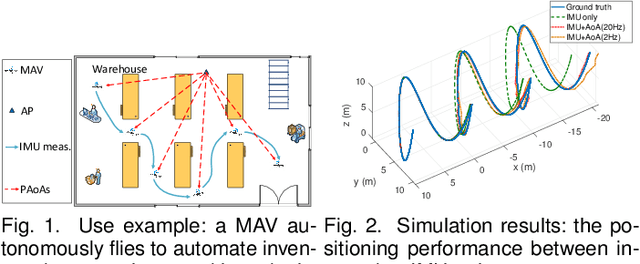
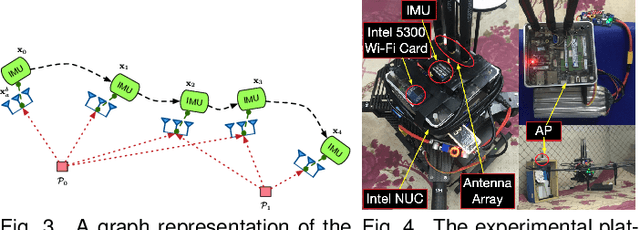
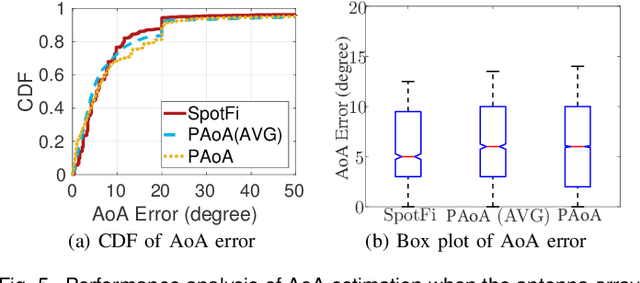

This paper presents an indoor pose estimation system for micro aerial vehicles (MAVs) with a single WiFi access point. Conventional approaches based on computer vision are limited by illumination conditions and environmental texture. Our system is free of visual limitations and instantly deployable, working upon existing WiFi infrastructure without any deployment cost. Our system consists of two coupled modules. First, we propose an angle-of-arrival (AoA) estimation algorithm to estimate MAV attitudes and disentangle the AoA for positioning. Second, we formulate a WiFi-inertial sensor fusion model that fuses the AoA and the odometry measured by inertial sensors to optimize MAV poses. Considering the practicality of MAVs, our system is designed to be real-time and initialization-free for the need of agile flight in unknown environments. The indoor experiments show that our system achieves the accuracy of pose estimation with the position error of $61.7$ cm and the attitude error of $0.92^\circ$.
RF Backscatter-based State Estimation for Micro Aerial Vehicles
Dec 19, 2019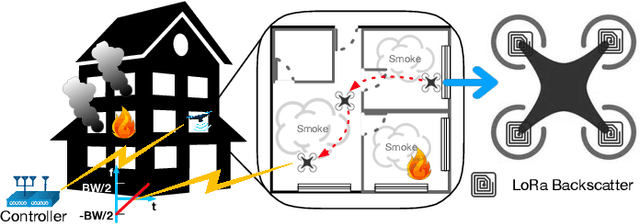
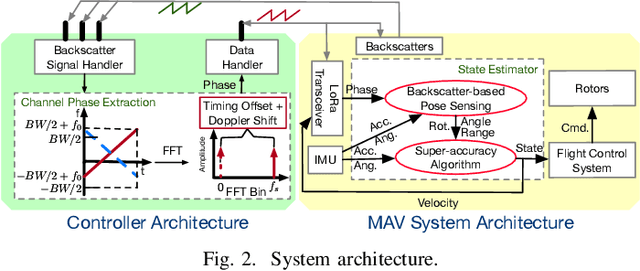
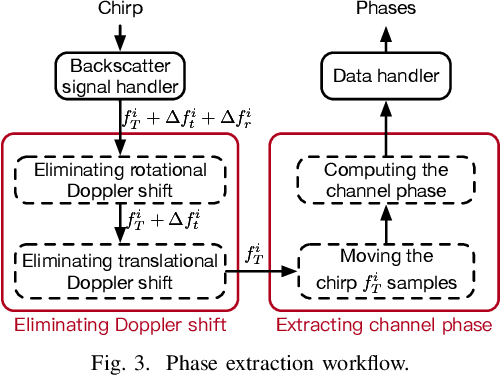
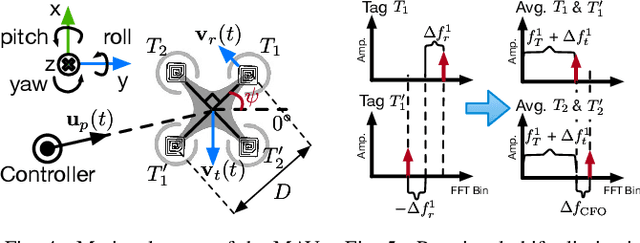
The advances in compact and agile micro aerial vehicles (MAVs) have shown great potential in replacing human for labor-intensive or dangerous indoor investigation, such as warehouse management and fire rescue. However, the design of a state estimation system that enables autonomous flight in such dim or smoky environments presents a conundrum: conventional GPS or computer vision based solutions only work in outdoors or well-lighted texture-rich environments. This paper takes the first step to overcome this hurdle by proposing Marvel, a lightweight RF backscatter-based state estimation system for MAVs in indoors. Marvel is nonintrusive to commercial MAVs by attaching backscatter tags to their landing gears without internal hardware modifications, and works in a plug-and-play fashion that does not require any infrastructure deployment, pre-trained signatures, or even without knowing the controller's location. The enabling techniques are a new backscatter-based pose sensing module and a novel backscatter-inertial super-accuracy state estimation algorithm. We demonstrate our design by programming a commercial-off-the-shelf MAV to autonomously fly in different trajectories. The results show that Marvel supports navigation within a range of $50$ m or through three concrete walls, with an accuracy of $34$ cm for localization and $4.99^\circ$ for orientation estimation, outperforming commercial GPS-based approaches in outdoors.
Localizing Backscatters by a Single Robot With Zero Start-up Cost
Aug 09, 2019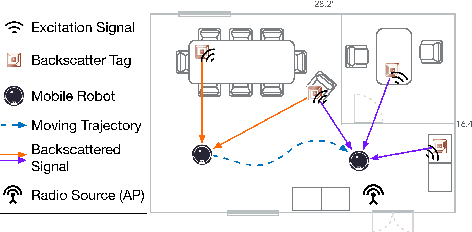

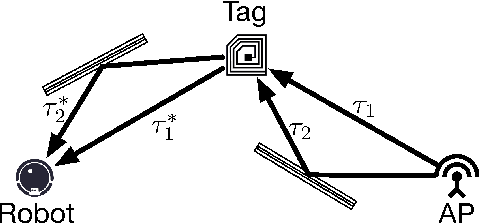
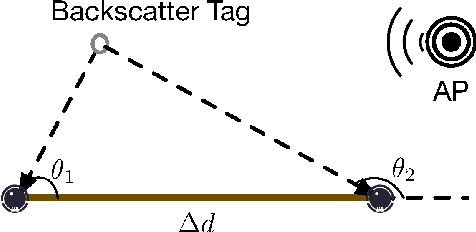
Recent years have witnessed the rapid proliferation of low-power backscatter technologies that realize the ubiquitous and long-term connectivity to empower smart cities and smart homes. Localizing such low-power backscatter tags is crucial for IoT-based smart services. However, current backscatter localization systems require prior knowledge of the site, either a map or landmarks with known positions, increasing the deployment cost. To empower universal localization service, this paper presents Rover, an indoor localization system that simultaneously localizes multiple backscatter tags with zero start-up cost using a robot equipped with inertial sensors. Rover runs in a joint optimization framework, fusing WiFi-based positioning measurements with inertial measurements to simultaneously estimate the locations of both the robot and the connected tags. Our design addresses practical issues such as the interference among multiple tags and the real-time processing for solving the SLAM problem. We prototype Rover using off-the-shelf WiFi chips and customized backscatter tags. Our experiments show that Rover achieves localization accuracies of 39.3 cm for the robot and 74.6 cm for the tags.