 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithfulFaces: Pose-Faithful Facial Identity Preservation for Text-to-Video Generation
May 06, 2026Identity-preserving text-to-video generation (IPT2V) empowers users to produce diverse and imaginative videos with consistent human facial identity. Despite recent progress, existing methods often suffer from significant identity distortion under large facial pose variations or facial occlusions. In this paper, we propose \textit{FaithfulFaces}, a pose-faithful facial identity preservation learning framework to improve IPT2V in complex dynamic scenes. The key of FaithfulFaces is a pose-shared identity aligner that refines and aligns facial poses across distinct views via a pose-shared dictionary and a pose variation-identity invariance constraint. By mapping single-view inputs into a global facial pose representation with explicit Euler angle embeddings, FaithfulFaces provides a pose-faithful facial prior that guides generative foundations toward robust identity-preserving generation. In particular, we develop a specialized pipeline to curate a high-quality video dataset featuring substantial facial pose diversity. Extensive experiments demonstrate that FaithfulFaces achieves state-of-the-art performance, maintaining superior identity consistency and structural clarity even as pose changes and occlusions occur.
POSE: Phased One-Step Adversarial Equilibrium for Video Diffusion Models
Aug 28, 2025



The field of video diffusion generation faces critical bottlenecks in sampling efficiency, especially for large-scale models and long sequences. Existing video acceleration methods adopt image-based techniques but suffer from fundamental limitations: they neither model the temporal coherence of video frames nor provide single-step distillation for large-scale video models. To bridge this gap, we propose POSE (Phased One-Step Equilibrium), a distillation framework that reduces the sampling steps of large-scale video diffusion models, enabling the generation of high-quality videos in a single step. POSE employs a carefully designed two-phase process to distill video models:(i) stability priming: a warm-up mechanism to stabilize adversarial distillation that adapts the high-quality trajectory of the one-step generator from high to low signal-to-noise ratio regimes, optimizing the video quality of single-step mappings near the endpoints of flow trajectories. (ii) unified adversarial equilibrium: a flexible self-adversarial distillation mechanism that promotes stable single-step adversarial training towards a Nash equilibrium within the Gaussian noise space, generating realistic single-step videos close to real videos. For conditional video generation, we propose (iii) conditional adversarial consistency, a method to improve both semantic consistency and frame consistency between conditional frames and generated frames. Comprehensive experiments demonstrate that POSE outperforms other acceleration methods on VBench-I2V by average 7.15% in semantic alignment, temporal conference and frame quality, reducing the latency of the pre-trained model by 100$\times$, from 1000 seconds to 10 seconds, while maintaining competitive performance.
UltraPose: Synthesizing Dense Pose with 1 Billion Points by Human-body Decoupling 3D Model
Oct 28, 2021

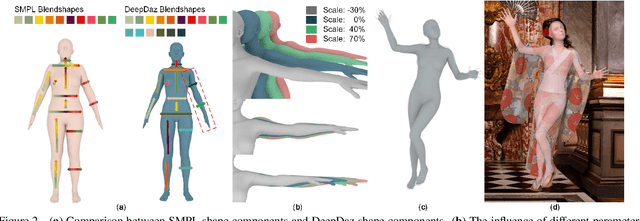
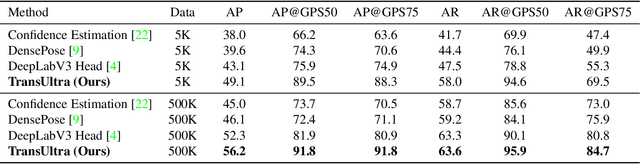
Recovering dense human poses from images plays a critical role in establishing an image-to-surface correspondence between RGB images and the 3D surface of the human body, serving the foundation of rich real-world applications, such as virtual humans, monocular-to-3d reconstruction. However, the popular DensePose-COCO dataset relies on a sophisticated manual annotation system, leading to severe limitations in acquiring the denser and more accurate annotated pose resources. In this work, we introduce a new 3D human-body model with a series of decoupled parameters that could freely control the generation of the body. Furthermore, we build a data generation system based on this decoupling 3D model, and construct an ultra dense synthetic benchmark UltraPose, containing around 1.3 billion corresponding points. Compared to the existing manually annotated DensePose-COCO dataset, the synthetic UltraPose has ultra dense image-to-surface correspondences without annotation cost and error. Our proposed UltraPose provides the largest benchmark and data resources for lifting the model capability in predicting more accurate dense poses. To promote future researches in this field, we also propose a transformer-based method to model the dense correspondence between 2D and 3D worlds. The proposed model trained on synthetic UltraPose can be applied to real-world scenarios, indicating the effectiveness of our benchmark and model.
* Accepted to ICCV 2021
M3D-VTON: A Monocular-to-3D Virtual Try-On Network
Aug 11, 2021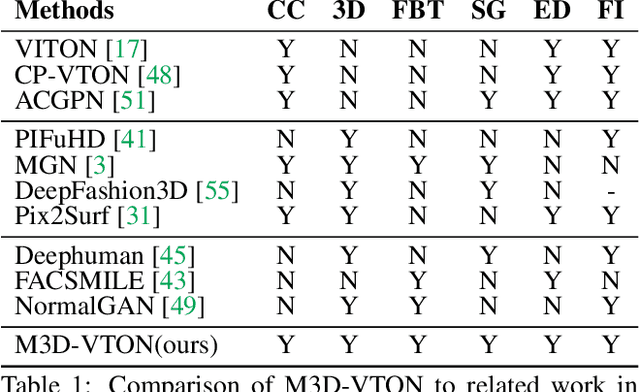
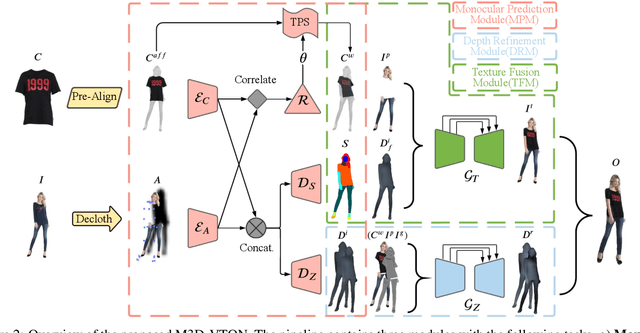
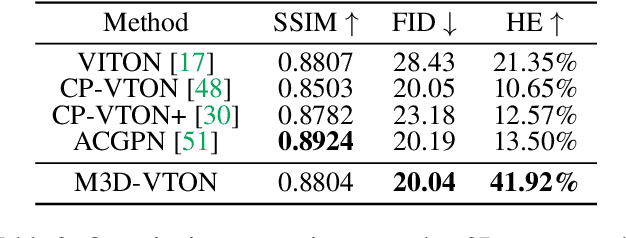
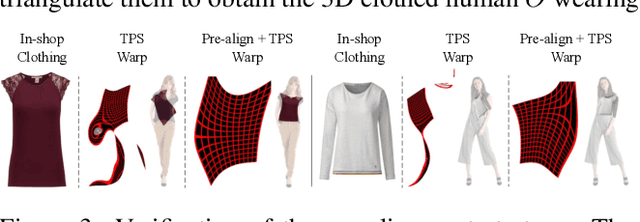
Virtual 3D try-on can provide an intuitive and realistic view for online shopping and has a huge potential commercial value. However, existing 3D virtual try-on methods mainly rely on annotated 3D human shapes and garment templates, which hinders their applications in practical scenarios. 2D virtual try-on approaches provide a faster alternative to manipulate clothed humans, but lack the rich and realistic 3D representation. In this paper, we propose a novel Monocular-to-3D Virtual Try-On Network (M3D-VTON) that builds on the merits of both 2D and 3D approaches. By integrating 2D information efficiently and learning a mapping that lifts the 2D representation to 3D, we make the first attempt to reconstruct a 3D try-on mesh only taking the target clothing and a person image as inputs. The proposed M3D-VTON includes three modules: 1) The Monocular Prediction Module (MPM) that estimates an initial full-body depth map and accomplishes 2D clothes-person alignment through a novel two-stage warping procedure; 2) The Depth Refinement Module (DRM) that refines the initial body depth to produce more detailed pleat and face characteristics; 3) The Texture Fusion Module (TFM) that fuses the warped clothing with the non-target body part to refine the results. We also construct a high-quality synthesized Monocular-to-3D virtual try-on dataset, in which each person image is associated with a front and a back depth map. Extensive experiments demonstrate that the proposed M3D-VTON can manipulate and reconstruct the 3D human body wearing the given clothing with compelling details and is more efficient than other 3D approaches.