 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated Clipping
Oct 25, 2025Recently, GRPO-based reinforcement learning has shown remarkable progress in optimizing flow-matching models, effectively improving their alignment with task-specific rewards. Within these frameworks, the policy update relies on importance-ratio clipping to constrain overconfident positive and negative gradients. However, in practice, we observe a systematic shift in the importance-ratio distribution-its mean falls below 1 and its variance differs substantially across timesteps. This left-shifted and inconsistent distribution prevents positive-advantage samples from entering the clipped region, causing the mechanism to fail in constraining overconfident positive updates. As a result, the policy model inevitably enters an implicit over-optimization stage-while the proxy reward continues to increase, essential metrics such as image quality and text-prompt alignment deteriorate sharply, ultimately making the learned policy impractical for real-world use. To address this issue, we introduce GRPO-Guard, a simple yet effective enhancement to existing GRPO frameworks. Our method incorporates ratio normalization, which restores a balanced and step-consistent importance ratio, ensuring that PPO clipping properly constrains harmful updates across denoising timesteps. In addition, a gradient reweighting strategy equalizes policy gradients over noise conditions, preventing excessive updates from particular timestep regions. Together, these designs act as a regulated clipping mechanism, stabilizing optimization and substantially mitigating implicit over-optimization without relying on heavy KL regularization. Extensive experiments on multiple diffusion backbones (e.g., SD3.5M, Flux.1-dev) and diverse proxy tasks demonstrate that GRPO-Guard significantly reduces over-optimization while maintaining or even improving generation quality.
DreamVTON: Customizing 3D Virtual Try-on with Personalized Diffusion Models
Jul 23, 2024



Image-based 3D Virtual Try-ON (VTON) aims to sculpt the 3D human according to person and clothes images, which is data-efficient (i.e., getting rid of expensive 3D data) but challenging. Recent text-to-3D methods achieve remarkable improvement in high-fidelity 3D human generation, demonstrating its potential for 3D virtual try-on. Inspired by the impressive success of personalized diffusion models (e.g., Dreambooth and LoRA) for 2D VTON, it is straightforward to achieve 3D VTON by integrating the personalization technique into the diffusion-based text-to-3D framework. However, employing the personalized module in a pre-trained diffusion model (e.g., StableDiffusion (SD)) would degrade the model's capability for multi-view or multi-domain synthesis, which is detrimental to the geometry and texture optimization guided by Score Distillation Sampling (SDS) loss. In this work, we propose a novel customizing 3D human try-on model, named \textbf{DreamVTON}, to separately optimize the geometry and texture of the 3D human. Specifically, a personalized SD with multi-concept LoRA is proposed to provide the generative prior about the specific person and clothes, while a Densepose-guided ControlNet is exploited to guarantee consistent prior about body pose across various camera views. Besides, to avoid the inconsistent multi-view priors from the personalized SD dominating the optimization, DreamVTON introduces a template-based optimization mechanism, which employs mask templates for geometry shape learning and normal/RGB templates for geometry/texture details learning. Furthermore, for the geometry optimization phase, DreamVTON integrates a normal-style LoRA into personalized SD to enhance normal map generative prior, facilitating smooth geometry modeling.
GUESS:GradUally Enriching SyntheSis for Text-Driven Human Motion Generation
Jan 06, 2024In this paper, we propose a novel cascaded diffusion-based generative framework for text-driven human motion synthesis, which exploits a strategy named GradUally Enriching SyntheSis (GUESS as its abbreviation). The strategy sets up generation objectives by grouping body joints of detailed skeletons in close semantic proximity together and then replacing each of such joint group with a single body-part node. Such an operation recursively abstracts a human pose to coarser and coarser skeletons at multiple granularity levels. With gradually increasing the abstraction level, human motion becomes more and more concise and stable, significantly benefiting the cross-modal motion synthesis task. The whole text-driven human motion synthesis problem is then divided into multiple abstraction levels and solved with a multi-stage generation framework with a cascaded latent diffusion model: an initial generator first generates the coarsest human motion guess from a given text description; then, a series of successive generators gradually enrich the motion details based on the textual description and the previous synthesized results. Notably, we further integrate GUESS with the proposed dynamic multi-condition fusion mechanism to dynamically balance the cooperative effects of the given textual condition and synthesized coarse motion prompt in different generation stages. Extensive experiments on large-scale datasets verify that GUESS outperforms existing state-of-the-art methods by large margins in terms of accuracy, realisticness, and diversity. Code is available at https://github.com/Xuehao-Gao/GUESS.
Towards Detailed Text-to-Motion Synthesis via Basic-to-Advanced Hierarchical Diffusion Model
Dec 18, 2023



Text-guided motion synthesis aims to generate 3D human motion that not only precisely reflects the textual description but reveals the motion details as much as possible. Pioneering methods explore the diffusion model for text-to-motion synthesis and obtain significant superiority. However, these methods conduct diffusion processes either on the raw data distribution or the low-dimensional latent space, which typically suffer from the problem of modality inconsistency or detail-scarce. To tackle this problem, we propose a novel Basic-to-Advanced Hierarchical Diffusion Model, named B2A-HDM, to collaboratively exploit low-dimensional and high-dimensional diffusion models for high quality detailed motion synthesis. Specifically, the basic diffusion model in low-dimensional latent space provides the intermediate denoising result that to be consistent with the textual description, while the advanced diffusion model in high-dimensional latent space focuses on the following detail-enhancing denoising process. Besides, we introduce a multi-denoiser framework for the advanced diffusion model to ease the learning of high-dimensional model and fully explore the generative potential of the diffusion model. Quantitative and qualitative experiment results on two text-to-motion benchmarks (HumanML3D and KIT-ML) demonstrate that B2A-HDM can outperform existing state-of-the-art methods in terms of fidelity, modality consistency, and diversity.
WarpDiffusion: Efficient Diffusion Model for High-Fidelity Virtual Try-on
Dec 06, 2023



Image-based Virtual Try-On (VITON) aims to transfer an in-shop garment image onto a target person. While existing methods focus on warping the garment to fit the body pose, they often overlook the synthesis quality around the garment-skin boundary and realistic effects like wrinkles and shadows on the warped garments. These limitations greatly reduce the realism of the generated results and hinder the practical application of VITON techniques. Leveraging the notable success of diffusion-based models in cross-modal image synthesis, some recent diffusion-based methods have ventured to tackle this issue. However, they tend to either consume a significant amount of training resources or struggle to achieve realistic try-on effects and retain garment details. For efficient and high-fidelity VITON, we propose WarpDiffusion, which bridges the warping-based and diffusion-based paradigms via a novel informative and local garment feature attention mechanism. Specifically, WarpDiffusion incorporates local texture attention to reduce resource consumption and uses a novel auto-mask module that effectively retains only the critical areas of the warped garment while disregarding unrealistic or erroneous portions. Notably, WarpDiffusion can be integrated as a plug-and-play component into existing VITON methodologies, elevating their synthesis quality. Extensive experiments on high-resolution VITON benchmarks and an in-the-wild test set demonstrate the superiority of WarpDiffusion, surpassing state-of-the-art methods both qualitatively and quantitatively.
Fashion Matrix: Editing Photos by Just Talking
Jul 25, 2023



The utilization of Large Language Models (LLMs) for the construction of AI systems has garnered significant attention across diverse fields. The extension of LLMs to the domain of fashion holds substantial commercial potential but also inherent challenges due to the intricate semantic interactions in fashion-related generation. To address this issue, we developed a hierarchical AI system called Fashion Matrix dedicated to editing photos by just talking. This system facilitates diverse prompt-driven tasks, encompassing garment or accessory replacement, recoloring, addition, and removal. Specifically, Fashion Matrix employs LLM as its foundational support and engages in iterative interactions with users. It employs a range of Semantic Segmentation Models (e.g., Grounded-SAM, MattingAnything, etc.) to delineate the specific editing masks based on user instructions. Subsequently, Visual Foundation Models (e.g., Stable Diffusion, ControlNet, etc.) are leveraged to generate edited images from text prompts and masks, thereby facilitating the automation of fashion editing processes. Experiments demonstrate the outstanding ability of Fashion Matrix to explores the collaborative potential of functionally diverse pre-trained models in the domain of fashion editing.
GP-VTON: Towards General Purpose Virtual Try-on via Collaborative Local-Flow Global-Parsing Learning
Mar 24, 2023Image-based Virtual Try-ON aims to transfer an in-shop garment onto a specific person. Existing methods employ a global warping module to model the anisotropic deformation for different garment parts, which fails to preserve the semantic information of different parts when receiving challenging inputs (e.g, intricate human poses, difficult garments). Moreover, most of them directly warp the input garment to align with the boundary of the preserved region, which usually requires texture squeezing to meet the boundary shape constraint and thus leads to texture distortion. The above inferior performance hinders existing methods from real-world applications. To address these problems and take a step towards real-world virtual try-on, we propose a General-Purpose Virtual Try-ON framework, named GP-VTON, by developing an innovative Local-Flow Global-Parsing (LFGP) warping module and a Dynamic Gradient Truncation (DGT) training strategy. Specifically, compared with the previous global warping mechanism, LFGP employs local flows to warp garments parts individually, and assembles the local warped results via the global garment parsing, resulting in reasonable warped parts and a semantic-correct intact garment even with challenging inputs.On the other hand, our DGT training strategy dynamically truncates the gradient in the overlap area and the warped garment is no more required to meet the boundary constraint, which effectively avoids the texture squeezing problem. Furthermore, our GP-VTON can be easily extended to multi-category scenario and jointly trained by using data from different garment categories. Extensive experiments on two high-resolution benchmarks demonstrate our superiority over the existing state-of-the-art methods.
Towards Hard-pose Virtual Try-on via 3D-aware Global Correspondence Learning
Nov 25, 2022



In this paper, we target image-based person-to-person virtual try-on in the presence of diverse poses and large viewpoint variations. Existing methods are restricted in this setting as they estimate garment warping flows mainly based on 2D poses and appearance, which omits the geometric prior of the 3D human body shape. Moreover, current garment warping methods are confined to localized regions, which makes them ineffective in capturing long-range dependencies and results in inferior flows with artifacts. To tackle these issues, we present 3D-aware global correspondences, which are reliable flows that jointly encode global semantic correlations, local deformations, and geometric priors of 3D human bodies. Particularly, given an image pair depicting the source and target person, (a) we first obtain their pose-aware and high-level representations via two encoders, and introduce a coarse-to-fine decoder with multiple refinement modules to predict the pixel-wise global correspondence. (b) 3D parametric human models inferred from images are incorporated as priors to regularize the correspondence refinement process so that our flows can be 3D-aware and better handle variations of pose and viewpoint. (c) Finally, an adversarial generator takes the garment warped by the 3D-aware flow, and the image of the target person as inputs, to synthesize the photo-realistic try-on result. Extensive experiments on public benchmarks and our HardPose test set demonstrate the superiority of our method against the SOTA try-on approaches.
ARMANI: Part-level Garment-Text Alignment for Unified Cross-Modal Fashion Design
Aug 11, 2022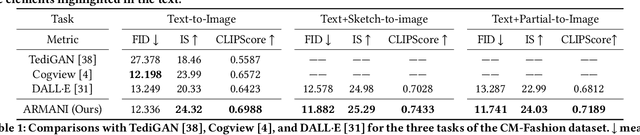

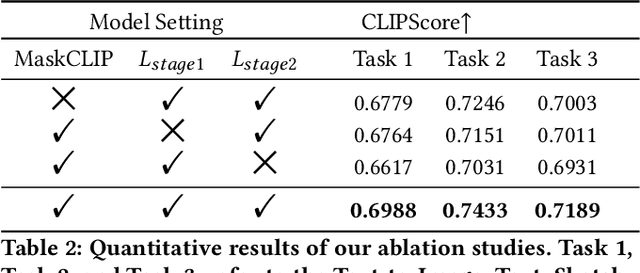
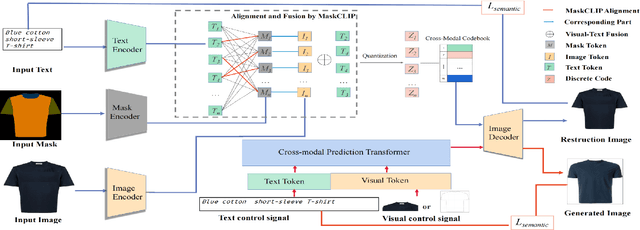
Cross-modal fashion image synthesis has emerged as one of the most promising directions in the generation domain due to the vast untapped potential of incorporating multiple modalities and the wide range of fashion image applications. To facilitate accurate generation, cross-modal synthesis methods typically rely on Contrastive Language-Image Pre-training (CLIP) to align textual and garment information. In this work, we argue that simply aligning texture and garment information is not sufficient to capture the semantics of the visual information and therefore propose MaskCLIP. MaskCLIP decomposes the garments into semantic parts, ensuring fine-grained and semantically accurate alignment between the visual and text information. Building on MaskCLIP, we propose ARMANI, a unified cross-modal fashion designer with part-level garment-text alignment. ARMANI discretizes an image into uniform tokens based on a learned cross-modal codebook in its first stage and uses a Transformer to model the distribution of image tokens for a real image given the tokens of the control signals in its second stage. Contrary to prior approaches that also rely on two-stage paradigms, ARMANI introduces textual tokens into the codebook, making it possible for the model to utilize fine-grain semantic information to generate more realistic images. Further, by introducing a cross-modal Transformer, ARMANI is versatile and can accomplish image synthesis from various control signals, such as pure text, sketch images, and partial images. Extensive experiments conducted on our newly collected cross-modal fashion dataset demonstrate that ARMANI generates photo-realistic images in diverse synthesis tasks and outperforms existing state-of-the-art cross-modal image synthesis approaches.Our code is available at https://github.com/Harvey594/ARMANI.
PASTA-GAN++: A Versatile Framework for High-Resolution Unpaired Virtual Try-on
Jul 27, 2022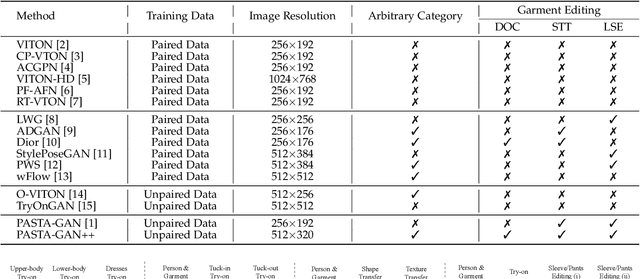

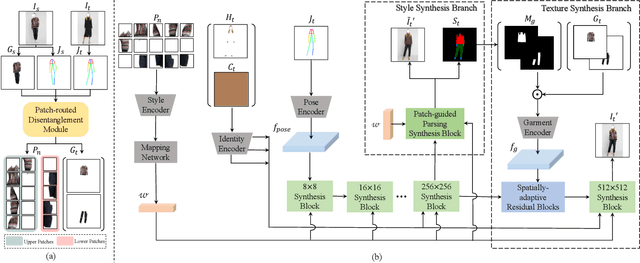

Image-based virtual try-on is one of the most promising applications of human-centric image generation due to its tremendous real-world potential. In this work, we take a step forwards to explore versatile virtual try-on solutions, which we argue should possess three main properties, namely, they should support unsupervised training, arbitrary garment categories, and controllable garment editing. To this end, we propose a characteristic-preserving end-to-end network, the PAtch-routed SpaTially-Adaptive GAN++ (PASTA-GAN++), to achieve a versatile system for high-resolution unpaired virtual try-on. Specifically, our PASTA-GAN++ consists of an innovative patch-routed disentanglement module to decouple the intact garment into normalized patches, which is capable of retaining garment style information while eliminating the garment spatial information, thus alleviating the overfitting issue during unsupervised training. Furthermore, PASTA-GAN++ introduces a patch-based garment representation and a patch-guided parsing synthesis block, allowing it to handle arbitrary garment categories and support local garment editing. Finally, to obtain try-on results with realistic texture details, PASTA-GAN++ incorporates a novel spatially-adaptive residual module to inject the coarse warped garment feature into the generator. Extensive experiments on our newly collected UnPaired virtual Try-on (UPT) dataset demonstrate the superiority of PASTA-GAN++ over existing SOTAs and its ability for controllable garment editing.