 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyCrowd: Instance-Isolated Identity-Pose Binding for Arbitrary Multi-Character Animation
Mar 16, 2026Controllable character animation has advanced rapidly in recent years, yet multi-character animation remains underexplored. As the number of characters grows, multi-character reference encoding becomes more susceptible to latent identity entanglement, resulting in identity bleeding and reduced controllability. Moreover, learning precise and spatio-temporally consistent correspondences between reference identities and driving pose sequences becomes increasingly challenging, often leading to identity-pose mis-binding and inconsistency in generated videos. To address these challenges, we propose AnyCrowd, a Diffusion Transformer (DiT)-based video generation framework capable of scaling to an arbitrary number of characters. Specifically, we first introduce an Instance-Isolated Latent Representation (IILR), which encodes character instances independently prior to DiT processing to prevent latent identity entanglement. Building on this disentangled representation, we further propose Tri-Stage Decoupled Attention (TSDA) to bind identities to driving poses by decomposing self-attention into: (i) instance-aware foreground attention, (ii) background-centric interaction, and (iii) global foreground-background coordination. Furthermore, to mitigate token ambiguity in overlapping regions, an Adaptive Gated Fusion (AGF) module is integrated within TSDA to predict identity-aware weights, effectively fusing competing token groups into identity-consistent representations...
SKeDA: A Generative Watermarking Framework for Text-to-video Diffusion Models
Feb 27, 2026The rise of text-to-video generation models has raised growing concerns over content authenticity, copyright protection, and malicious misuse. Watermarking serves as an effective mechanism for regulating such AI-generated content, where high fidelity and strong robustness are particularly critical. Recent generative image watermarking methods provide a promising foundation by leveraging watermark information and pseudo-random keys to control the initial sampling noise, enabling lossless embedding. However, directly extending these techniques to videos introduces two key limitations: Existing designs implicitly rely on strict alignment between video frames and frame-dependent pseudo-random binary sequences used for watermark encryption. Once this alignment is disrupted, subsequent watermark extraction becomes unreliable; and Video-specific distortions, such as inter-frame compression, significantly degrade watermark reliability. To address these issues, we propose SKeDA, a generative watermarking framework tailored for text-to-video diffusion models. SKeDA consists of two components: (1) Shuffle-Key-based Distribution-preserving Sampling (SKe) employs a single base pseudo-random binary sequence for watermark encryption and derives frame-level encryption sequences through permutation. This design transforms watermark extraction from synchronization-sensitive sequence decoding into permutation-tolerant set-level aggregation, substantially improving robustness against frame reordering and loss; and (2) Differential Attention (DA), which computes inter-frame differences and dynamically adjusts attention weights during extraction, enhancing robustness against temporal distortions. Extensive experiments demonstrate that SKeDA preserves high video generation quality and watermark robustness.
ERGO: Excess-Risk-Guided Optimization for High-Fidelity Monocular 3D Gaussian Splatting
Feb 10, 2026Generating 3D content from a single image remains a fundamentally challenging and ill-posed problem due to the inherent absence of geometric and textural information in occluded regions. While state-of-the-art generative models can synthesize auxiliary views to provide additional supervision, these views inevitably contain geometric inconsistencies and textural misalignments that propagate and amplify artifacts during 3D reconstruction. To effectively harness these imperfect supervisory signals, we propose an adaptive optimization framework guided by excess risk decomposition, termed ERGO. Specifically, ERGO decomposes the optimization losses in 3D Gaussian splatting into two components, i.e., excess risk that quantifies the suboptimality gap between current and optimal parameters, and Bayes error that models the irreducible noise inherent in synthesized views. This decomposition enables ERGO to dynamically estimate the view-specific excess risk and adaptively adjust loss weights during optimization. Furthermore, we introduce geometry-aware and texture-aware objectives that complement the excess-risk-derived weighting mechanism, establishing a synergistic global-local optimization paradigm. Consequently, ERGO demonstrates robustness against supervision noise while consistently enhancing both geometric fidelity and textural quality of the reconstructed 3D content. Extensive experiments on the Google Scanned Objects dataset and the OmniObject3D dataset demonstrate the superiority of ERGO over existing state-of-the-art methods.
Allocentric Perceiver: Disentangling Allocentric Reasoning from Egocentric Visual Priors via Frame Instantiation
Feb 05, 2026With the rising need for spatially grounded tasks such as Vision-Language Navigation/Action, allocentric perception capabilities in Vision-Language Models (VLMs) are receiving growing focus. However, VLMs remain brittle on allocentric spatial queries that require explicit perspective shifts, where the answer depends on reasoning in a target-centric frame rather than the observed camera view. Thus, we introduce Allocentric Perceiver, a training-free strategy that recovers metric 3D states from one or more images with off-the-shelf geometric experts, and then instantiates a query-conditioned allocentric reference frame aligned with the instruction's semantic intent. By deterministically transforming reconstructed geometry into the target frame and prompting the backbone VLM with structured, geometry-grounded representations, Allocentric Perceriver offloads mental rotation from implicit reasoning to explicit computation. We evaluate Allocentric Perciver across multiple backbone families on spatial reasoning benchmarks, observing consistent and substantial gains ($\sim$10%) on allocentric tasks while maintaining strong egocentric performance, and surpassing both spatial-perception-finetuned models and state-of-the-art open-source and proprietary models.
FreeText: Training-Free Text Rendering in Diffusion Transformers via Attention Localization and Spectral Glyph Injection
Jan 02, 2026Large-scale text-to-image (T2I) diffusion models excel at open-domain synthesis but still struggle with precise text rendering, especially for multi-line layouts, dense typography, and long-tailed scripts such as Chinese. Prior solutions typically require costly retraining or rigid external layout constraints, which can degrade aesthetics and limit flexibility. We propose \textbf{FreeText}, a training-free, plug-and-play framework that improves text rendering by exploiting intrinsic mechanisms of \emph{Diffusion Transformer (DiT)} models. \textbf{FreeText} decomposes the problem into \emph{where to write} and \emph{what to write}. For \emph{where to write}, we localize writing regions by reading token-wise spatial attribution from endogenous image-to-text attention, using sink-like tokens as stable spatial anchors and topology-aware refinement to produce high-confidence masks. For \emph{what to write}, we introduce Spectral-Modulated Glyph Injection (SGMI), which injects a noise-aligned glyph prior with frequency-domain band-pass modulation to strengthen glyph structure and suppress semantic leakage (rendering the concept instead of the word). Extensive experiments on Qwen-Image, FLUX.1-dev, and SD3 variants across longText-Benchmark, CVTG, and our CLT-Bench show consistent gains in text readability while largely preserving semantic alignment and aesthetic quality, with modest inference overhead.
AuthSig: Safeguarding Scanned Signatures Against Unauthorized Reuse in Paperless Workflows
Nov 12, 2025With the deepening trend of paperless workflows, signatures as a means of identity authentication are gradually shifting from traditional ink-on-paper to electronic formats.Despite the availability of dynamic pressure-sensitive and PKI-based digital signatures, static scanned signatures remain prevalent in practice due to their convenience. However, these static images, having almost lost their authentication attributes, cannot be reliably verified and are vulnerable to malicious copying and reuse. To address these issues, we propose AuthSig, a novel static electronic signature framework based on generative models and watermark, which binds authentication information to the signature image. Leveraging the human visual system's insensitivity to subtle style variations, AuthSig finely modulates style embeddings during generation to implicitly encode watermark bits-enforcing a One Signature, One Use policy.To overcome the scarcity of handwritten signature data and the limitations of traditional augmentation methods, we introduce a keypoint-driven data augmentation strategy that effectively enhances style diversity to support robust watermark embedding. Experimental results show that AuthSig achieves over 98% extraction accuracy under both digital-domain distortions and signature-specific degradations, and remains effective even in print-scan scenarios.
DreamVTON: Customizing 3D Virtual Try-on with Personalized Diffusion Models
Jul 23, 2024



Image-based 3D Virtual Try-ON (VTON) aims to sculpt the 3D human according to person and clothes images, which is data-efficient (i.e., getting rid of expensive 3D data) but challenging. Recent text-to-3D methods achieve remarkable improvement in high-fidelity 3D human generation, demonstrating its potential for 3D virtual try-on. Inspired by the impressive success of personalized diffusion models (e.g., Dreambooth and LoRA) for 2D VTON, it is straightforward to achieve 3D VTON by integrating the personalization technique into the diffusion-based text-to-3D framework. However, employing the personalized module in a pre-trained diffusion model (e.g., StableDiffusion (SD)) would degrade the model's capability for multi-view or multi-domain synthesis, which is detrimental to the geometry and texture optimization guided by Score Distillation Sampling (SDS) loss. In this work, we propose a novel customizing 3D human try-on model, named \textbf{DreamVTON}, to separately optimize the geometry and texture of the 3D human. Specifically, a personalized SD with multi-concept LoRA is proposed to provide the generative prior about the specific person and clothes, while a Densepose-guided ControlNet is exploited to guarantee consistent prior about body pose across various camera views. Besides, to avoid the inconsistent multi-view priors from the personalized SD dominating the optimization, DreamVTON introduces a template-based optimization mechanism, which employs mask templates for geometry shape learning and normal/RGB templates for geometry/texture details learning. Furthermore, for the geometry optimization phase, DreamVTON integrates a normal-style LoRA into personalized SD to enhance normal map generative prior, facilitating smooth geometry modeling.
DeAR: A Deep-learning-based Audio Re-recording Resilient Watermarking
Dec 13, 2022Audio watermarking is widely used for leaking source tracing. The robustness of the watermark determines the traceability of the algorithm. With the development of digital technology, audio re-recording (AR) has become an efficient and covert means to steal secrets. AR process could drastically destroy the watermark signal while preserving the original information. This puts forward a new requirement for audio watermarking at this stage, that is, to be robust to AR distortions. Unfortunately, none of the existing algorithms can effectively resist AR attacks due to the complexity of the AR process. To address this limitation, this paper proposes DeAR, a deep-learning-based audio re-recording resistant watermarking. Inspired by DNN-based image watermarking, we pioneer a deep learning framework for audio carriers, based on which the watermark signal can be effectively embedded and extracted. Meanwhile, in order to resist the AR attack, we delicately analyze the distortions that occurred in the AR process and design the corresponding distortion layer to cooperate with the proposed watermarking framework. Extensive experiments show that the proposed algorithm can resist not only common electronic channel distortions but also AR distortions. Under the premise of high-quality embedding (SNR=25.86dB), in the case of a common re-recording distance (20cm), the algorithm can effectively achieve an average bit recovery accuracy of 98.55%.
Tracing Text Provenance via Context-Aware Lexical Substitution
Dec 15, 2021
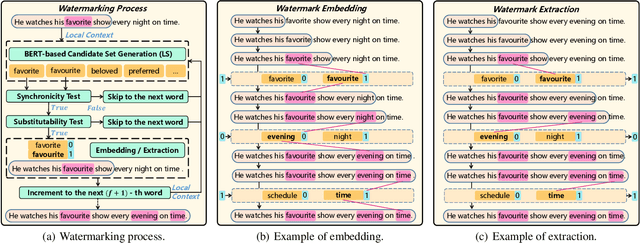
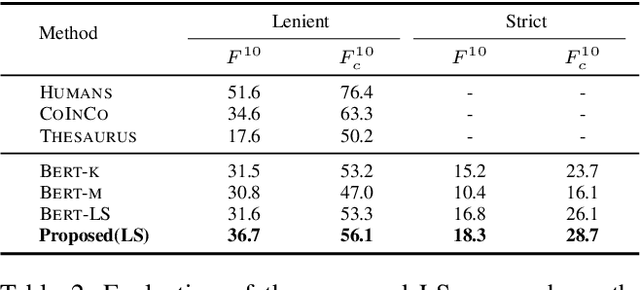
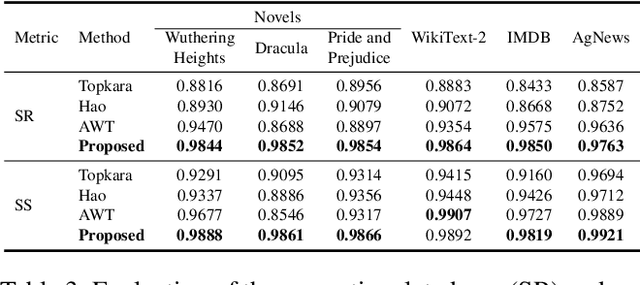
Text content created by humans or language models is often stolen or misused by adversaries. Tracing text provenance can help claim the ownership of text content or identify the malicious users who distribute misleading content like machine-generated fake news. There have been some attempts to achieve this, mainly based on watermarking techniques. Specifically, traditional text watermarking methods embed watermarks by slightly altering text format like line spacing and font, which, however, are fragile to cross-media transmissions like OCR. Considering this, natural language watermarking methods represent watermarks by replacing words in original sentences with synonyms from handcrafted lexical resources (e.g., WordNet), but they do not consider the substitution's impact on the overall sentence's meaning. Recently, a transformer-based network was proposed to embed watermarks by modifying the unobtrusive words (e.g., function words), which also impair the sentence's logical and semantic coherence. Besides, one well-trained network fails on other different types of text content. To address the limitations mentioned above, we propose a natural language watermarking scheme based on context-aware lexical substitution (LS). Specifically, we employ BERT to suggest LS candidates by inferring the semantic relatedness between the candidates and the original sentence. Based on this, a selection strategy in terms of synchronicity and substitutability is further designed to test whether a word is exactly suitable for carrying the watermark signal. Extensive experiments demonstrate that, under both objective and subjective metrics, our watermarking scheme can well preserve the semantic integrity of original sentences and has a better transferability than existing methods. Besides, the proposed LS approach outperforms the state-of-the-art approach on the Stanford Word Substitution Benchmark.
Exploring Structure Consistency for Deep Model Watermarking
Aug 05, 2021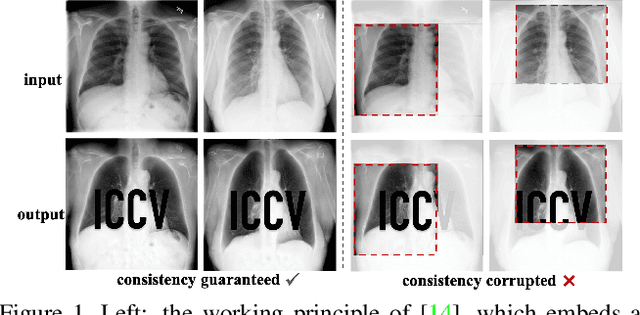
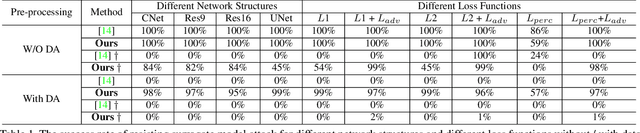

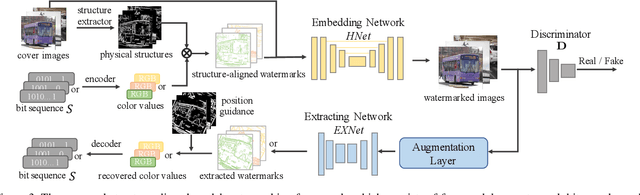
The intellectual property (IP) of Deep neural networks (DNNs) can be easily ``stolen'' by surrogate model attack. There has been significant progress in solutions to protect the IP of DNN models in classification tasks. However, little attention has been devoted to the protection of DNNs in image processing tasks. By utilizing consistent invisible spatial watermarks, one recent work first considered model watermarking for deep image processing networks and demonstrated its efficacy in many downstream tasks. Nevertheless, it highly depends on the hypothesis that the embedded watermarks in the network outputs are consistent. When the attacker uses some common data augmentation attacks (e.g., rotate, crop, and resize) during surrogate model training, it will totally fail because the underlying watermark consistency is destroyed. To mitigate this issue, we propose a new watermarking methodology, namely ``structure consistency'', based on which a new deep structure-aligned model watermarking algorithm is designed. Specifically, the embedded watermarks are designed to be aligned with physically consistent image structures, such as edges or semantic regions. Experiments demonstrate that our method is much more robust than the baseline method in resisting data augmentation attacks for model IP protection. Besides that, we further test the generalization ability and robustness of our method to a broader range of circumvention attacks.