 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Coordination as a Bridge: A Neuro-Symbolic Architecture for Reliable Autonomous Driving Scene Understanding
May 06, 2026Reliable autonomous driving requires scene understanding that is semantically consistent across heterogeneous sensors and verifiable at the reasoning stage. However, many recent LLM-driven driving systems attach the language model as a post-processor and force it to reason over redundant or conflicting perception outputs, which can amplify hallucinated entities and unsafe conclusions. This paper proposes InfoCoordiBridge, a BEV-centric neuro-symbolic architecture that inserts an explicit coordination bridge between perception and language reasoning. InfoCoordiBridge comprises (i) a unified multi-agent perception layer that outputs typed structured facts together with modality-focused synopses, (ii) an ICA module that aligns and fuses multi-source outputs into a single SceneSummary, and (iii) an SSRE module that performs SceneSummary-grounded reasoning with verification. Experiments on nuScenes and Waymo show that ICA preserves competitive 3D detection accuracy while substantially improving fusion consistency, reducing redundancy to below 1% and achieving about 98% attribute agreement. On NuScenes-QA and a template-aligned Waymo-QA benchmark, SSRE improves factual grounding and reduces hallucinated entity mentions compared with representative VLM and agentic baselines. Overall, by coordinating multi-sensor outputs into a single conflict-aware SceneSummary before prompting, InfoCoordiBridge prevents redundant and cross-modally inconsistent perception evidence from propagating into high-level reasoning.
The Past Is Not Past: Memory-Enhanced Dynamic Reward Shaping
Apr 13, 2026Despite the success of reinforcement learning for large language models, a common failure mode is reduced sampling diversity, where the policy repeatedly generates similar erroneous behaviors. Classical entropy regularization encourages randomness under the current policy, but does not explicitly discourage recurrent failure patterns across rollouts. We propose MEDS, a Memory-Enhanced Dynamic reward Shaping framework that incorporates historical behavioral signals into reward design. By storing and leveraging intermediate model representations, we capture features of past rollouts and use density-based clustering to identify frequently recurring error patterns. Rollouts assigned to more prevalent error clusters are penalized more heavily, encouraging broader exploration while reducing repeated mistakes. Across five datasets and three base models, MEDS consistently improves average performance over existing baselines, achieving gains of up to 4.13 pass@1 points and 4.37 pass@128 points. Additional analyses using both LLM-based annotations and quantitative diversity metrics show that MEDS increases behavioral diversity during sampling.
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
BandPO: Bridging Trust Regions and Ratio Clipping via Probability-Aware Bounds for LLM Reinforcement Learning
Mar 05, 2026Proximal constraints are fundamental to the stability of the Large Language Model reinforcement learning. While the canonical clipping mechanism in PPO serves as an efficient surrogate for trust regions, we identify a critical bottleneck: fixed bounds strictly constrain the upward update margin of low-probability actions, disproportionately suppressing high-advantage tail strategies and inducing rapid entropy collapse. To address this, we introduce Band-constrained Policy Optimization (BandPO). BandPO replaces canonical clipping with Band, a unified theoretical operator that projects trust regions defined by f-divergences into dynamic, probability-aware clipping intervals. Theoretical analysis confirms that Band effectively resolves this exploration bottleneck. We formulate this mapping as a convex optimization problem, guaranteeing a globally optimal numerical solution while deriving closed-form solutions for specific divergences. Extensive experiments across diverse models and datasets demonstrate that BandPO consistently outperforms canonical clipping and Clip-Higher, while robustly mitigating entropy collapse.
MELLA: Bridging Linguistic Capability and Cultural Groundedness for Low-Resource Language MLLMs
Aug 07, 2025Multimodal Large Language Models (MLLMs) have shown remarkable performance in high-resource languages. However, their effectiveness diminishes significantly in the contexts of low-resource languages. Current multilingual enhancement methods are often limited to text modality or rely solely on machine translation. While such approaches help models acquire basic linguistic capabilities and produce "thin descriptions", they neglect the importance of multimodal informativeness and cultural groundedness, both of which are crucial for serving low-resource language users effectively. To bridge this gap, in this study, we identify two significant objectives for a truly effective MLLM in low-resource language settings, namely 1) linguistic capability and 2) cultural groundedness, placing special emphasis on cultural awareness. To achieve these dual objectives, we propose a dual-source strategy that guides the collection of data tailored to each goal, sourcing native web alt-text for culture and MLLM-generated captions for linguistics. As a concrete implementation, we introduce MELLA, a multimodal, multilingual dataset. Experiment results show that after fine-tuning on MELLA, there is a general performance improvement for the eight languages on various MLLM backbones, with models producing "thick descriptions". We verify that the performance gains are from both cultural knowledge enhancement and linguistic capability enhancement. Our dataset can be found at https://opendatalab.com/applyMultilingualCorpus.
Does Your 3D Encoder Really Work? When Pretrain-SFT from 2D VLMs Meets 3D VLMs
Jun 06, 2025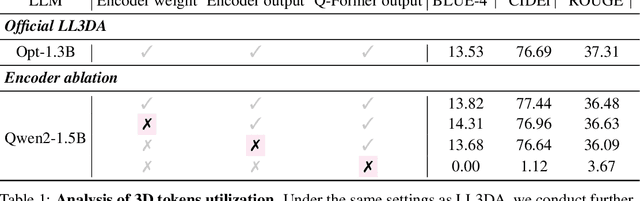
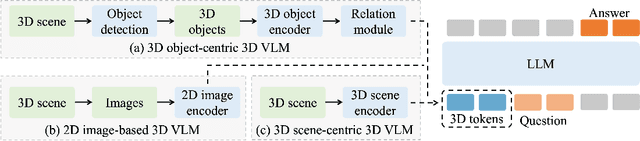

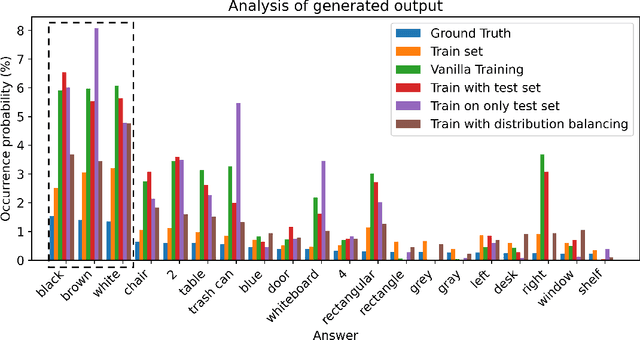
Remarkable progress in 2D Vision-Language Models (VLMs) has spurred interest in extending them to 3D settings for tasks like 3D Question Answering, Dense Captioning, and Visual Grounding. Unlike 2D VLMs that typically process images through an image encoder, 3D scenes, with their intricate spatial structures, allow for diverse model architectures. Based on their encoder design, this paper categorizes recent 3D VLMs into 3D object-centric, 2D image-based, and 3D scene-centric approaches. Despite the architectural similarity of 3D scene-centric VLMs to their 2D counterparts, they have exhibited comparatively lower performance compared with the latest 3D object-centric and 2D image-based approaches. To understand this gap, we conduct an in-depth analysis, revealing that 3D scene-centric VLMs show limited reliance on the 3D scene encoder, and the pre-train stage appears less effective than in 2D VLMs. Furthermore, we observe that data scaling benefits are less pronounced on larger datasets. Our investigation suggests that while these models possess cross-modal alignment capabilities, they tend to over-rely on linguistic cues and overfit to frequent answer distributions, thereby diminishing the effective utilization of the 3D encoder. To address these limitations and encourage genuine 3D scene understanding, we introduce a novel 3D Relevance Discrimination QA dataset designed to disrupt shortcut learning and improve 3D understanding. Our findings highlight the need for advanced evaluation and improved strategies for better 3D understanding in 3D VLMs.
News Reporter: A Multi-lingual LLM Framework for Broadcast T.V News
Oct 10, 2024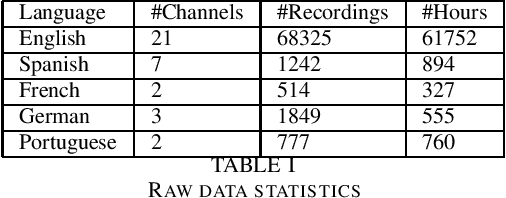


Large Language Models (LLMs) have fast become an essential tools to many conversational chatbots due to their ability to provide coherent answers for varied queries. Datasets used to train these LLMs are often a mix of generic and synthetic samples, thus lacking the verification needed to provide correct and verifiable answers for T.V. News. We collect and share a large collection of QA pairs extracted from transcripts of news recordings from various news-channels across the United States. Resultant QA pairs are then used to fine-tune an off-the-shelf LLM model. Our model surpasses base models of similar size on several open LLM benchmarks. We further integrate and propose a RAG method to improve contextualization of our answers and also point it to a verifiable news recording.
DreamVTON: Customizing 3D Virtual Try-on with Personalized Diffusion Models
Jul 23, 2024



Image-based 3D Virtual Try-ON (VTON) aims to sculpt the 3D human according to person and clothes images, which is data-efficient (i.e., getting rid of expensive 3D data) but challenging. Recent text-to-3D methods achieve remarkable improvement in high-fidelity 3D human generation, demonstrating its potential for 3D virtual try-on. Inspired by the impressive success of personalized diffusion models (e.g., Dreambooth and LoRA) for 2D VTON, it is straightforward to achieve 3D VTON by integrating the personalization technique into the diffusion-based text-to-3D framework. However, employing the personalized module in a pre-trained diffusion model (e.g., StableDiffusion (SD)) would degrade the model's capability for multi-view or multi-domain synthesis, which is detrimental to the geometry and texture optimization guided by Score Distillation Sampling (SDS) loss. In this work, we propose a novel customizing 3D human try-on model, named \textbf{DreamVTON}, to separately optimize the geometry and texture of the 3D human. Specifically, a personalized SD with multi-concept LoRA is proposed to provide the generative prior about the specific person and clothes, while a Densepose-guided ControlNet is exploited to guarantee consistent prior about body pose across various camera views. Besides, to avoid the inconsistent multi-view priors from the personalized SD dominating the optimization, DreamVTON introduces a template-based optimization mechanism, which employs mask templates for geometry shape learning and normal/RGB templates for geometry/texture details learning. Furthermore, for the geometry optimization phase, DreamVTON integrates a normal-style LoRA into personalized SD to enhance normal map generative prior, facilitating smooth geometry modeling.
Evaluating LLMs at Evaluating Temporal Generalization
May 14, 2024The rapid advancement of Large Language Models (LLMs) highlights the urgent need for evolving evaluation methodologies that keep pace with improvements in language comprehension and information processing. However, traditional benchmarks, which are often static, fail to capture the continually changing information landscape, leading to a disparity between the perceived and actual effectiveness of LLMs in ever-changing real-world scenarios. Furthermore, these benchmarks do not adequately measure the models' capabilities over a broader temporal range or their adaptability over time. We examine current LLMs in terms of temporal generalization and bias, revealing that various temporal biases emerge in both language likelihood and prognostic prediction. This serves as a caution for LLM practitioners to pay closer attention to mitigating temporal biases. Also, we propose an evaluation framework Freshbench for dynamically generating benchmarks from the most recent real-world prognostication prediction. Our code is available at https://github.com/FreedomIntelligence/FreshBench. The dataset will be released soon.