 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOGIGEN: Logic-Driven Generation of Verifiable Agentic Tasks
Feb 28, 2026The evolution of Large Language Models (LLMs) from static instruction-followers to autonomous agents necessitates operating within complex, stateful environments to achieve precise state-transition objectives. However, this paradigm is bottlenecked by data scarcity, as existing tool-centric reverse-synthesis pipelines fail to capture the rigorous logic of real-world applications. We introduce \textbf{LOGIGEN}, a logic-driven framework that synthesizes verifiable training data based on three core pillars: \textbf{Hard-Compiled Policy Grounding}, \textbf{Logic-Driven Forward Synthesis}, and \textbf{Deterministic State Verification}. Specifically, a Triple-Agent Orchestration is employed: the \textbf{Architect} compiles natural-language policy into database constraints to enforce hard rules; the \textbf{Set Designer} initializes boundary-adjacent states to trigger critical policy conflicts; and the \textbf{Explorer} searches this environment to discover causal solution paths. This framework yields a dataset of 20,000 complex tasks across 8 domains, where validity is strictly guaranteed by checking exact state equivalence. Furthermore, we propose a verification-based training protocol where Supervised Fine-Tuning (SFT) on verifiable trajectories establishes compliance with hard-compiled policy, while Reinforcement Learning (RL) guided by dense state-rewards refines long-horizon goal achievement. On $τ^2$-Bench, LOGIGEN-32B(RL) achieves a \textbf{79.5\% success rate}, substantially outperforming the base model (40.7\%). These results demonstrate that logic-driven synthesis combined with verification-based training effectively constructs the causally valid trajectories needed for next-generation agents.
QianfanHuijin Technical Report: A Novel Multi-Stage Training Paradigm for Finance Industrial LLMs
Dec 30, 2025Domain-specific enhancement of Large Language Models (LLMs) within the financial context has long been a focal point of industrial application. While previous models such as BloombergGPT and Baichuan-Finance primarily focused on knowledge enhancement, the deepening complexity of financial services has driven a growing demand for models that possess not only domain knowledge but also robust financial reasoning and agentic capabilities. In this paper, we present QianfanHuijin, a financial domain LLM, and propose a generalizable multi-stage training paradigm for industrial model enhancement. Our approach begins with Continual Pre-training (CPT) on financial corpora to consolidate the knowledge base. This is followed by a fine-grained Post-training pipeline designed with increasing specificity: starting with Financial SFT, progressing to Finance Reasoning RL and Finance Agentic RL, and culminating in General RL aligned with real-world business scenarios. Empirical results demonstrate that QianfanHuijin achieves superior performance across various authoritative financial benchmarks. Furthermore, ablation studies confirm that the targeted Reasoning RL and Agentic RL stages yield significant gains in their respective capabilities. These findings validate our motivation and suggest that this fine-grained, progressive post-training methodology is poised to become a mainstream paradigm for various industrial-enhanced LLMs.
Towards Faithful and Controllable Personalization via Critique-Post-Edit Reinforcement Learning
Oct 21, 2025Faithfully personalizing large language models (LLMs) to align with individual user preferences is a critical but challenging task. While supervised fine-tuning (SFT) quickly reaches a performance plateau, standard reinforcement learning from human feedback (RLHF) also struggles with the nuances of personalization. Scalar-based reward models are prone to reward hacking which leads to verbose and superficially personalized responses. To address these limitations, we propose Critique-Post-Edit, a robust reinforcement learning framework that enables more faithful and controllable personalization. Our framework integrates two key components: (1) a Personalized Generative Reward Model (GRM) that provides multi-dimensional scores and textual critiques to resist reward hacking, and (2) a Critique-Post-Edit mechanism where the policy model revises its own outputs based on these critiques for more targeted and efficient learning. Under a rigorous length-controlled evaluation, our method substantially outperforms standard PPO on personalization benchmarks. Personalized Qwen2.5-7B achieves an average 11\% win-rate improvement, and personalized Qwen2.5-14B model surpasses the performance of GPT-4.1. These results demonstrate a practical path to faithful, efficient, and controllable personalization.
MiCoTA: Bridging the Learnability Gap with Intermediate CoT and Teacher Assistants
Jul 02, 2025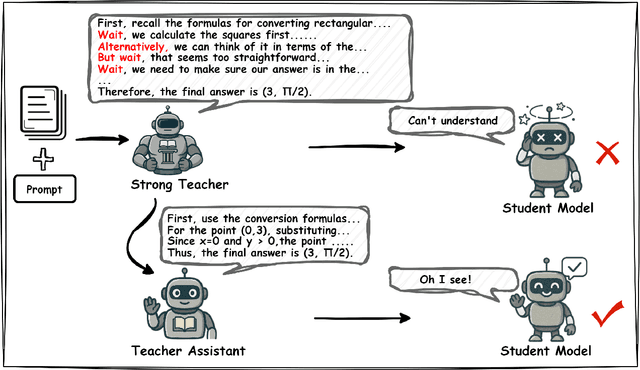
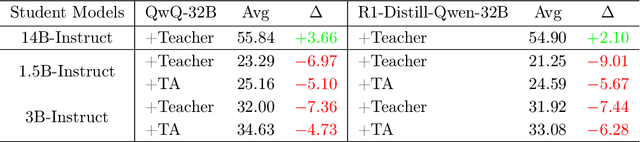
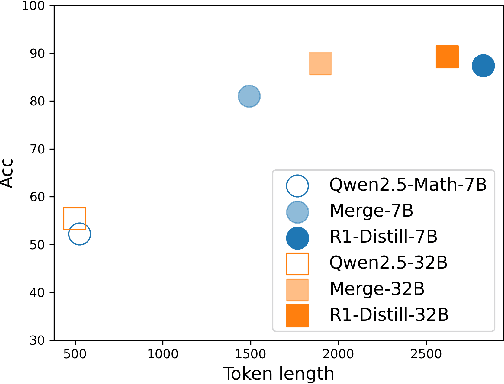
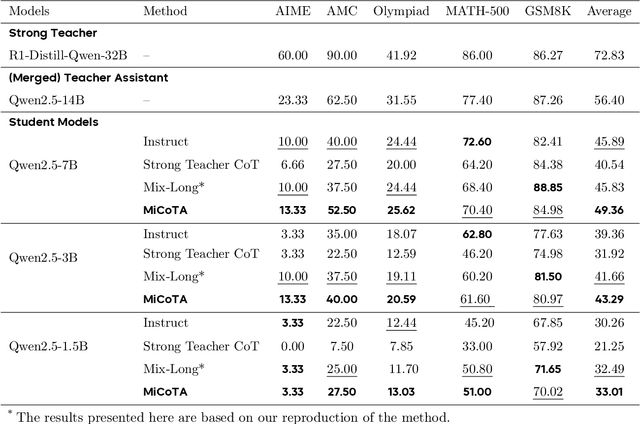
Large language models (LLMs) excel at reasoning tasks requiring long thought sequences for planning, reflection, and refinement. However, their substantial model size and high computational demands are impractical for widespread deployment. Yet, small language models (SLMs) often struggle to learn long-form CoT reasoning due to their limited capacity, a phenomenon we refer to as the "SLMs Learnability Gap". To address this, we introduce \textbf{Mi}d-\textbf{Co}T \textbf{T}eacher \textbf{A}ssistant Distillation (MiCoTAl), a framework for improving long CoT distillation for SLMs. MiCoTA employs intermediate-sized models as teacher assistants and utilizes intermediate-length CoT sequences to bridge both the capacity and reasoning length gaps. Our experiments on downstream tasks demonstrate that although SLMs distilled from large teachers can perform poorly, by applying MiCoTA, they achieve significant improvements in reasoning performance. Specifically, Qwen2.5-7B-Instruct and Qwen2.5-3B-Instruct achieve an improvement of 3.47 and 3.93 respectively on average score on AIME2024, AMC, Olympiad, MATH-500 and GSM8K benchmarks. To better understand the mechanism behind MiCoTA, we perform a quantitative experiment demonstrating that our method produces data more closely aligned with base SLM distributions. Our insights pave the way for future research into long-CoT data distillation for SLMs.
PersonaFeedback: A Large-scale Human-annotated Benchmark For Personalization
Jun 15, 2025With the rapid improvement in the general capabilities of LLMs, LLM personalization, i.e., how to build LLM systems that can generate personalized responses or services that are tailored to distinct user personas, has become an increasingly important research and engineering problem. However, unlike many new challenging benchmarks being released for evaluating the general/reasoning capabilities, the lack of high-quality benchmarks for evaluating LLM personalization greatly hinders progress in this field. To address this, we introduce PersonaFeedback, a new benchmark that directly evaluates LLMs' ability to provide personalized responses given pre-defined user personas and queries. Unlike existing benchmarks that require models to infer implicit user personas from historical interactions, PersonaFeedback decouples persona inference from personalization, focusing on evaluating the model's ability to generate responses tailored to explicit personas. PersonaFeedback consists of 8298 human-annotated test cases, which are categorized into easy, medium, and hard tiers based on the contextual complexity of the user personas and the difficulty in distinguishing subtle differences between two personalized responses. We conduct comprehensive evaluations across a wide range of models. The empirical results reveal that even state-of-the-art LLMs that can solve complex real-world reasoning tasks could fall short on the hard tier of PersonaFeedback where even human evaluators may find the distinctions challenging. Furthermore, we conduct an in-depth analysis of failure modes across various types of systems, demonstrating that the current retrieval-augmented framework should not be seen as a de facto solution for personalization tasks. All benchmark data, annotation protocols, and the evaluation pipeline will be publicly available to facilitate future research on LLM personalization.
Evaluating LLMs at Evaluating Temporal Generalization
May 14, 2024The rapid advancement of Large Language Models (LLMs) highlights the urgent need for evolving evaluation methodologies that keep pace with improvements in language comprehension and information processing. However, traditional benchmarks, which are often static, fail to capture the continually changing information landscape, leading to a disparity between the perceived and actual effectiveness of LLMs in ever-changing real-world scenarios. Furthermore, these benchmarks do not adequately measure the models' capabilities over a broader temporal range or their adaptability over time. We examine current LLMs in terms of temporal generalization and bias, revealing that various temporal biases emerge in both language likelihood and prognostic prediction. This serves as a caution for LLM practitioners to pay closer attention to mitigating temporal biases. Also, we propose an evaluation framework Freshbench for dynamically generating benchmarks from the most recent real-world prognostication prediction. Our code is available at https://github.com/FreedomIntelligence/FreshBench. The dataset will be released soon.
MLLM-Bench, Evaluating Multi-modal LLMs using GPT-4V
Nov 23, 2023


In the pursuit of Artificial General Intelligence (AGI), the integration of vision in language models has marked a significant milestone. The advent of vision-language models (MLLMs) like GPT-4V have expanded AI applications, aligning with the multi-modal capabilities of the human brain. However, evaluating the efficacy of MLLMs poses a substantial challenge due to the subjective nature of tasks that lack definitive answers. Existing automatic evaluation methodologies on multi-modal large language models rely on objective queries that have standard answers, inadequately addressing the nuances of creative and associative multi-modal tasks. To address this, we introduce MLLM-Bench, an innovative benchmark inspired by Vicuna, spanning a diverse array of scenarios, including Perception, Understanding, Applying, Analyzing, Evaluating, and Creation along with the ethical consideration. MLLM-Bench is designed to reflect user experience more accurately and provide a more holistic assessment of model performance. Comparative evaluations indicate a significant performance gap between existing open-source models and GPT-4V. We posit that MLLM-Bench will catalyze progress in the open-source community towards developing user-centric vision-language models that meet a broad spectrum of real-world applications. See online leaderboard in \url{https://mllm-bench.llmzoo.com}.
XCMRC: Evaluating Cross-lingual Machine Reading Comprehension
Aug 15, 2019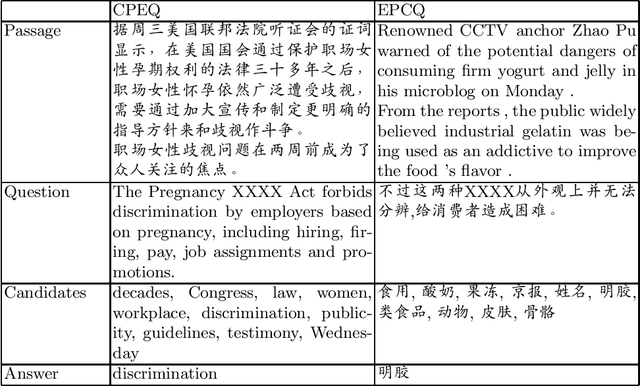
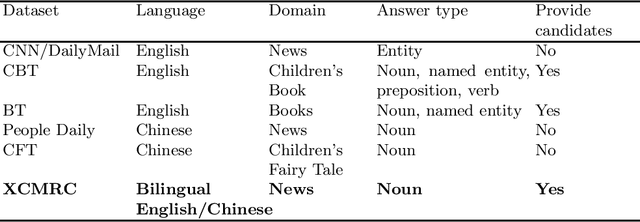
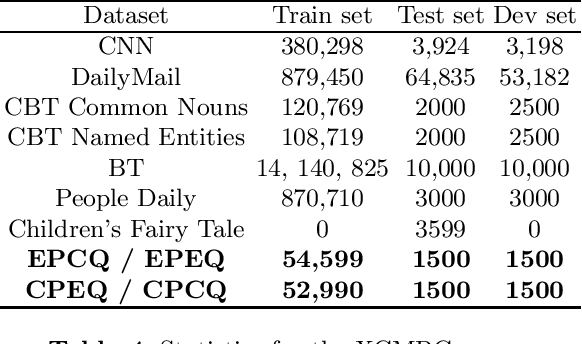
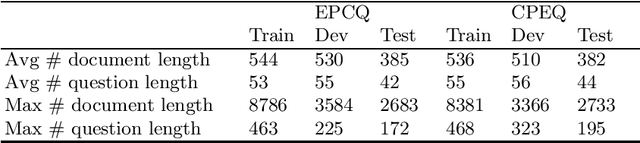
We present XCMRC, the first public cross-lingual language understanding (XLU) benchmark which aims to test machines on their cross-lingual reading comprehension ability. To be specific, XCMRC is a Cross-lingual Cloze-style Machine Reading Comprehension task which requires the reader to fill in a missing word (we additionally provide ten noun candidates) in a sentence written in target language (English / Chinese) by reading a given passage written in source language (Chinese / English). Chinese and English are rich-resource language pairs, in order to study low-resource cross-lingual machine reading comprehension (XMRC), besides defining the common XCMRC task which has no restrictions on use of external language resources, we also define the pseudo low-resource XCMRC task by limiting the language resources to be used. In addition, we provide two baselines for common XCMRC task and two for pseudo XCMRC task respectively. We also provide an upper bound baseline for both tasks. We found that for common XCMRC task, translation-based method and multilingual sentence encoder-based method can obtain reasonable performance but still have much room for improvement. As for pseudo low-resource XCMRC task, due to strict restrictions on the use of language resources, our two approaches are far below the upper bound so there are many challenges ahead.
Emotion Action Detection and Emotion Inference: the Task and Dataset
Mar 16, 2019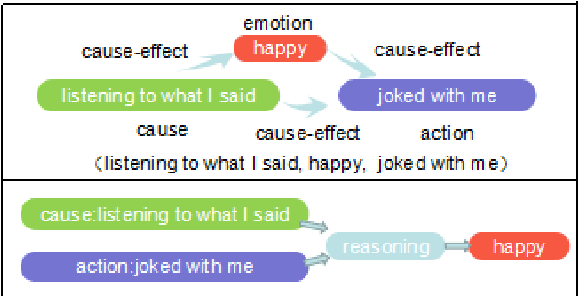



Many Natural Language Processing works on emotion analysis only focus on simple emotion classification without exploring the potentials of putting emotion into "event context", and ignore the analysis of emotion-related events. One main reason is the lack of this kind of corpus. Here we present Cause-Emotion-Action Corpus, which manually annotates not only emotion, but also cause events and action events. We propose two new tasks based on the data-set: emotion causality and emotion inference. The first task is to extract a triple (cause, emotion, action). The second task is to infer the probable emotion. We are currently releasing the data-set with 10,603 samples and 15,892 events, basic statistic analysis and baseline on both emotion causality and emotion inference tasks. Baseline performance demonstrates that there is much room for both tasks to be improved.