 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIVE: Scaling Diversity in Agentic Task Synthesis for Generalizable Tool Use
Mar 10, 2026Recent work synthesizes agentic tasks for post-training tool-using LLMs, yet robust generalization under shifts in tasks and toolsets remains an open challenge. We trace this brittleness to insufficient diversity in synthesized tasks. Scaling diversity is difficult because training requires tasks to remain executable and verifiable, while generalization demands coverage of diverse tool types, toolset combinations, and heterogeneous tool-use patterns. We propose DIVE, an evidence-driven recipe that inverts synthesis order, executing diverse, real-world tools first and reverse-deriving tasks strictly entailed by the resulting traces, thereby providing grounding by construction. DIVE scales structural diversity along two controllable axes, tool-pool coverage and per-task toolset variety, and an Evidence Collection--Task Derivation loop further induces rich multi-step tool-use patterns across 373 tools in five domains. Training Qwen3-8B on DIVE data (48k SFT + 3.2k RL) improves by +22 average points across 9 OOD benchmarks and outperforms the strongest 8B baseline by +68. Remarkably, controlled scaling analysis reveals that diversity scaling consistently outperforms quantity scaling for OOD generalization, even with 4x less data.
HER: Human-like Reasoning and Reinforcement Learning for LLM Role-playing
Jan 29, 2026LLM role-playing, i.e., using LLMs to simulate specific personas, has emerged as a key capability in various applications, such as companionship, content creation, and digital games. While current models effectively capture character tones and knowledge, simulating the inner thoughts behind their behaviors remains a challenge. Towards cognitive simulation in LLM role-play, previous efforts mainly suffer from two deficiencies: data with high-quality reasoning traces, and reliable reward signals aligned with human preferences. In this paper, we propose HER, a unified framework for cognitive-level persona simulation. HER introduces dual-layer thinking, which distinguishes characters' first-person thinking from LLMs' third-person thinking. To bridge these gaps, we curate reasoning-augmented role-playing data via reverse engineering and construct human-aligned principles and reward models. Leveraging these resources, we train \method models based on Qwen3-32B via supervised and reinforcement learning. Extensive experiments validate the effectiveness of our approach. Notably, our models significantly outperform the Qwen3-32B baseline, achieving a 30.26 improvement on the CoSER benchmark and a 14.97 gain on the Minimax Role-Play Bench. Our datasets, principles, and models will be released to facilitate future research.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
Think Thrice Before You Act: Progressive Thought Refinement in Large Language Models
Oct 17, 2024



Recent advancements in large language models (LLMs) have demonstrated that progressive refinement, rather than providing a single answer, results in more accurate and thoughtful outputs. However, existing methods often rely heavily on supervision signals to evaluate previous responses, making it difficult to assess output quality in more open-ended scenarios effectively. Additionally, these methods are typically designed for specific tasks, which limits their generalization to new domains. To address these limitations, we propose Progressive Thought Refinement (PTR), a framework that enables LLMs to refine their responses progressively. PTR operates in two phases: (1) Thought data construction stage: We propose a weak and strong model collaborative selection strategy to build a high-quality progressive refinement dataset to ensure logical consistency from thought to answers, and the answers are gradually refined in each round. (2) Thought-Mask Fine-Tuning Phase: We design a training structure to mask the "thought" and adjust loss weights to encourage LLMs to refine prior thought, teaching them to implicitly understand "how to improve" rather than "what is correct." Experimental results show that PTR significantly enhances LLM performance across ten diverse tasks (avg. from 49.6% to 53.5%) without task-specific fine-tuning. Notably, in more open-ended tasks, LLMs also demonstrate substantial improvements in the quality of responses beyond mere accuracy, suggesting that PTR truly teaches LLMs to self-improve over time.
SED: Self-Evaluation Decoding Enhances Large Language Models for Better Generation
May 26, 2024Existing Large Language Models (LLMs) generate text through unidirectional autoregressive decoding methods to respond to various user queries. These methods tend to consider token selection in a simple sequential manner, making it easy to fall into suboptimal options when encountering uncertain tokens, referred to as chaotic points in our work. Many chaotic points exist in texts generated by LLMs, and they often significantly affect the quality of subsequently generated tokens, which can interfere with LLMs' generation. This paper proposes Self-Evaluation Decoding, SED, a decoding method for enhancing model generation. Analogous to the human decision-making process, SED integrates speculation and evaluation steps into the decoding process, allowing LLMs to make more careful decisions and thus optimize token selection at chaotic points. Experimental results across various tasks using different LLMs demonstrate SED's effectiveness.
Enhancing Confidence Expression in Large Language Models Through Learning from Past Experience
Apr 16, 2024



Large Language Models (LLMs) have exhibited remarkable performance across various downstream tasks, but they may generate inaccurate or false information with a confident tone. One of the possible solutions is to empower the LLM confidence expression capability, in which the confidence expressed can be well-aligned with the true probability of the generated answer being correct. However, leveraging the intrinsic ability of LLMs or the signals from the output logits of answers proves challenging in accurately capturing the response uncertainty in LLMs. Therefore, drawing inspiration from cognitive diagnostics, we propose a method of Learning from Past experience (LePe) to enhance the capability for confidence expression. Specifically, we first identify three key problems: (1) How to capture the inherent confidence of the LLM? (2) How to teach the LLM to express confidence? (3) How to evaluate the confidence expression of the LLM? Then we devise three stages in LePe to deal with these problems. Besides, to accurately capture the confidence of an LLM when constructing the training data, we design a complete pipeline including question preparation and answer sampling. We also conduct experiments using the Llama family of LLMs to verify the effectiveness of our proposed method on four datasets.
Large Language Model Can Continue Evolving From Mistakes
Apr 11, 2024



Large Language Models (LLMs) demonstrate impressive performance in various downstream tasks. However, they may still generate incorrect responses in certain scenarios due to the knowledge deficiencies and the flawed pre-training data. Continual Learning (CL) is a commonly used method to address this issue. Traditional CL is task-oriented, using novel or factually accurate data to retrain LLMs from scratch. However, this method requires more task-related training data and incurs expensive training costs. To address this challenge, we propose the Continue Evolving from Mistakes (CEM) method, inspired by the 'summarize mistakes' learning skill, to achieve iterative refinement of LLMs. Specifically, the incorrect responses of LLMs indicate knowledge deficiencies related to the questions. Therefore, we collect corpora with these knowledge from multiple data sources and follow it up with iterative supplementary training for continuous, targeted knowledge updating and supplementation. Meanwhile, we developed two strategies to construct supplementary training sets to enhance the LLM's understanding of the corpus and prevent catastrophic forgetting. We conducted extensive experiments to validate the effectiveness of this CL method. In the best case, our method resulted in a 17.00\% improvement in the accuracy of the LLM.
Emotion Action Detection and Emotion Inference: the Task and Dataset
Mar 16, 2019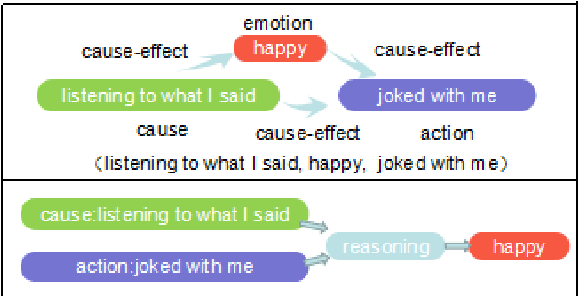



Many Natural Language Processing works on emotion analysis only focus on simple emotion classification without exploring the potentials of putting emotion into "event context", and ignore the analysis of emotion-related events. One main reason is the lack of this kind of corpus. Here we present Cause-Emotion-Action Corpus, which manually annotates not only emotion, but also cause events and action events. We propose two new tasks based on the data-set: emotion causality and emotion inference. The first task is to extract a triple (cause, emotion, action). The second task is to infer the probable emotion. We are currently releasing the data-set with 10,603 samples and 15,892 events, basic statistic analysis and baseline on both emotion causality and emotion inference tasks. Baseline performance demonstrates that there is much room for both tasks to be improved.