 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeART: Attention Replacement Technique to Improve Factuality in LLMs
Apr 07, 2026Hallucination in large language models (LLMs) continues to be a significant issue, particularly in tasks like question answering, where models often generate plausible yet incorrect or irrelevant information. Although various methods have been proposed to mitigate hallucinations, the relationship between attention patterns and hallucinations has not been fully explored. In this paper, we analyze the distribution of attention scores across each layer and attention head of LLMs, revealing a common and intriguing phenomenon: shallow layers of LLMs primarily rely on uniform attention patterns, where the model distributes its attention evenly across the entire sequence. This uniform attention pattern can lead to hallucinations, as the model fails to focus on the most relevant information. To mitigate this issue, we propose a training-free method called Attention Replacement Technique (ART), which replaces these uniform attention patterns in the shallow layers with local attention patterns. This change directs the model to focus more on the relevant contexts, thus reducing hallucinations. Through extensive experiments, ART demonstrates significant reductions in hallucinations across multiple LLM architectures, proving its effectiveness and generalizability without requiring fine-tuning or additional training data.
RELATE: A Reinforcement Learning-Enhanced LLM Framework for Advertising Text Generation
Feb 12, 2026In online advertising, advertising text plays a critical role in attracting user engagement and driving advertiser value. Existing industrial systems typically follow a two-stage paradigm, where candidate texts are first generated and subsequently aligned with online performance metrics such as click-through rate(CTR). This separation often leads to misaligned optimization objectives and low funnel efficiency, limiting global optimality. To address these limitations, we propose RELATE, a reinforcement learning-based end-to-end framework that unifies generation and objective alignment within a single model. Instead of decoupling text generation from downstream metric alignment, RELATE integrates performance and compliance objectives directly into the generation process via policy learning. To better capture ultimate advertiser value beyond click-level signals, We incorporate conversion-oriented metrics into the objective and jointly model them with compliance constraints as multi-dimensional rewards, enabling the model to generate high-quality ad texts that improve conversion performance under policy constraints. Extensive experiments on large-scale industrial datasets demonstrate that RELATE consistently outperforms baselines. Furthermore, online deployment on a production advertising platform yields statistically significant improvements in click-through conversion rate(CTCVR) under strict policy constraints, validating the robustness and real-world effectiveness of the proposed framework.
FlashThink: An Early Exit Method For Efficient Reasoning
May 20, 2025Large Language Models (LLMs) have shown impressive performance in reasoning tasks. However, LLMs tend to generate excessively long reasoning content, leading to significant computational overhead. Our observations indicate that even on simple problems, LLMs tend to produce unnecessarily lengthy reasoning content, which is against intuitive expectations. Preliminary experiments show that at a certain point during the generation process, the model is already capable of producing the correct solution without completing the full reasoning content. Therefore, we consider that the reasoning process of the model can be exited early to achieve the purpose of efficient reasoning. We introduce a verification model that identifies the exact moment when the model can stop reasoning and still provide the correct answer. Comprehensive experiments on four different benchmarks demonstrate that our proposed method, FlashThink, effectively shortens the reasoning content while preserving the model accuracy. For the Deepseek-R1 and QwQ-32B models, we reduced the length of reasoning content by 77.04% and 77.47%, respectively, without reducing the accuracy.
RLAP: A Reinforcement Learning Enhanced Adaptive Planning Framework for Multi-step NLP Task Solving
May 17, 2025Multi-step planning has been widely employed to enhance the performance of large language models (LLMs) on downstream natural language processing (NLP) tasks, which decomposes the original task into multiple subtasks and guide LLMs to solve them sequentially without additional training. When addressing task instances, existing methods either preset the order of steps or attempt multiple paths at each step. However, these methods overlook instances' linguistic features and rely on the intrinsic planning capabilities of LLMs to evaluate intermediate feedback and then select subtasks, resulting in suboptimal outcomes. To better solve multi-step NLP tasks with LLMs, in this paper we propose a Reinforcement Learning enhanced Adaptive Planning framework (RLAP). In our framework, we model an NLP task as a Markov decision process (MDP) and employ an LLM directly into the environment. In particular, a lightweight Actor model is trained to estimate Q-values for natural language sequences consisting of states and actions through reinforcement learning. Therefore, during sequential planning, the linguistic features of each sequence in the MDP can be taken into account, and the Actor model interacts with the LLM to determine the optimal order of subtasks for each task instance. We apply RLAP on three different types of NLP tasks and conduct extensive experiments on multiple datasets to verify RLAP's effectiveness and robustness.
Mitigating Out-of-Entity Errors in Named Entity Recognition: A Sentence-Level Strategy
Dec 11, 2024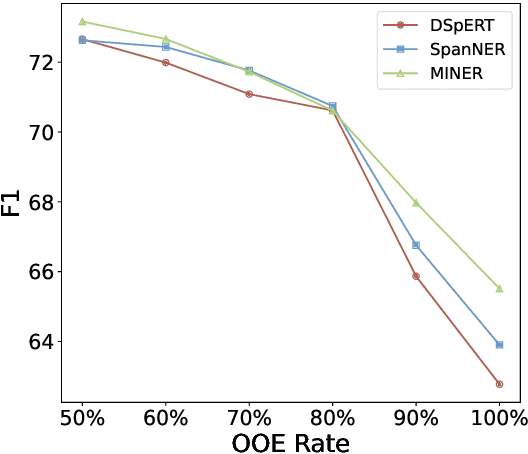
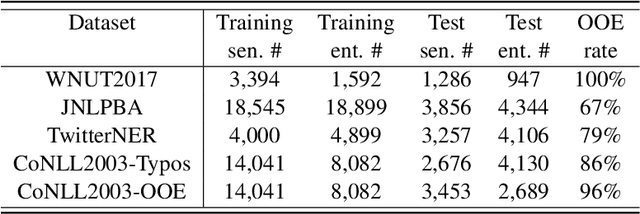
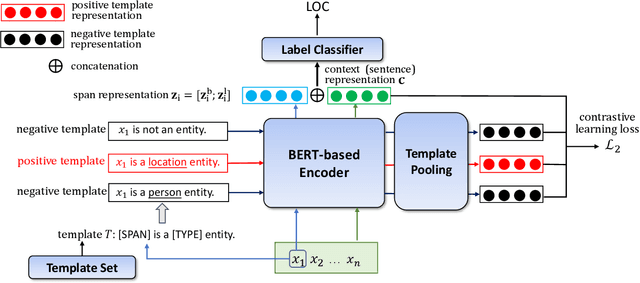
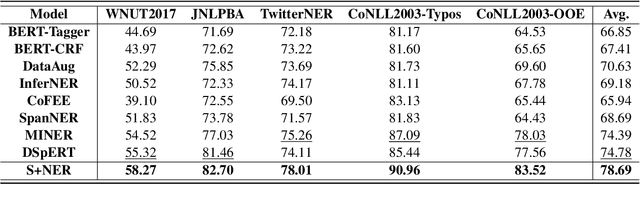
Many previous models of named entity recognition (NER) suffer from the problem of Out-of-Entity (OOE), i.e., the tokens in the entity mentions of the test samples have not appeared in the training samples, which hinders the achievement of satisfactory performance. To improve OOE-NER performance, in this paper, we propose a new framework, namely S+NER, which fully leverages sentence-level information. Our S+NER achieves better OOE-NER performance mainly due to the following two particular designs. 1) It first exploits the pre-trained language model's capability of understanding the target entity's sentence-level context with a template set. 2) Then, it refines the sentence-level representation based on the positive and negative templates, through a contrastive learning strategy and template pooling method, to obtain better NER results. Our extensive experiments on five benchmark datasets have demonstrated that, our S+NER outperforms some state-of-the-art OOE-NER models.
SED: Self-Evaluation Decoding Enhances Large Language Models for Better Generation
May 26, 2024Existing Large Language Models (LLMs) generate text through unidirectional autoregressive decoding methods to respond to various user queries. These methods tend to consider token selection in a simple sequential manner, making it easy to fall into suboptimal options when encountering uncertain tokens, referred to as chaotic points in our work. Many chaotic points exist in texts generated by LLMs, and they often significantly affect the quality of subsequently generated tokens, which can interfere with LLMs' generation. This paper proposes Self-Evaluation Decoding, SED, a decoding method for enhancing model generation. Analogous to the human decision-making process, SED integrates speculation and evaluation steps into the decoding process, allowing LLMs to make more careful decisions and thus optimize token selection at chaotic points. Experimental results across various tasks using different LLMs demonstrate SED's effectiveness.
ToNER: Type-oriented Named Entity Recognition with Generative Language Model
Apr 14, 2024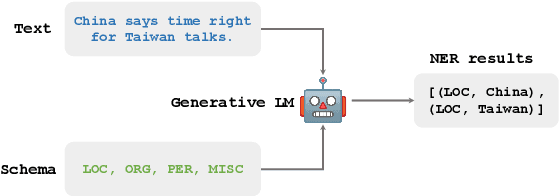

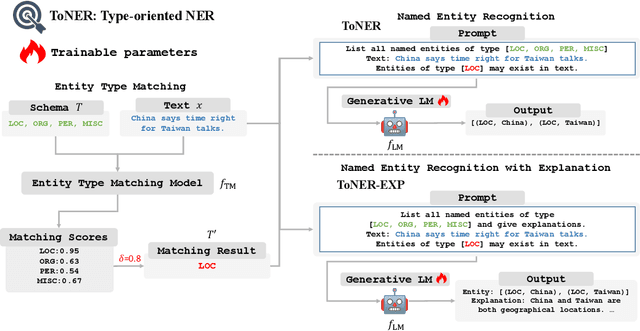

In recent years, the fine-tuned generative models have been proven more powerful than the previous tagging-based or span-based models on named entity recognition (NER) task. It has also been found that the information related to entities, such as entity types, can prompt a model to achieve NER better. However, it is not easy to determine the entity types indeed existing in the given sentence in advance, and inputting too many potential entity types would distract the model inevitably. To exploit entity types' merit on promoting NER task, in this paper we propose a novel NER framework, namely ToNER based on a generative model. In ToNER, a type matching model is proposed at first to identify the entity types most likely to appear in the sentence. Then, we append a multiple binary classification task to fine-tune the generative model's encoder, so as to generate the refined representation of the input sentence. Moreover, we add an auxiliary task for the model to discover the entity types which further fine-tunes the model to output more accurate results. Our extensive experiments on some NER benchmarks verify the effectiveness of our proposed strategies in ToNER that are oriented towards entity types' exploitation.