 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeSeriesScientist: A General-Purpose AI Agent for Time Series Analysis
Oct 02, 2025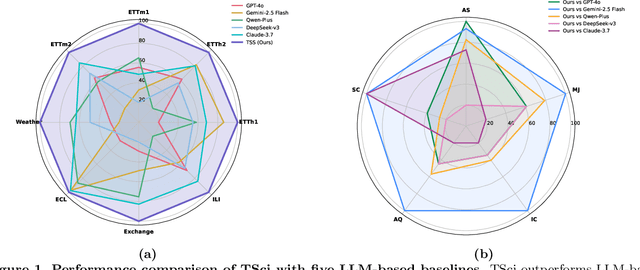
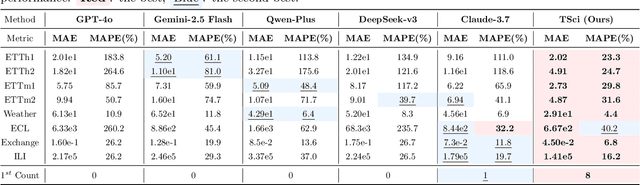
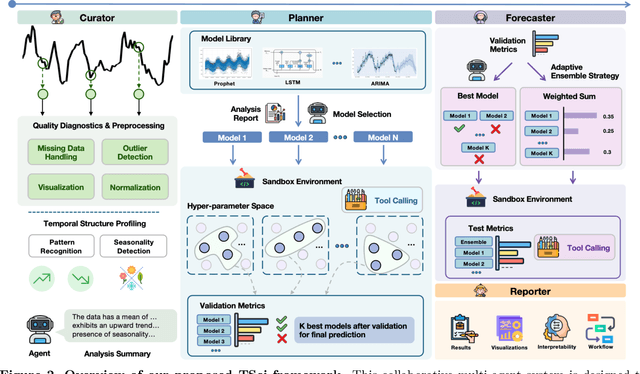
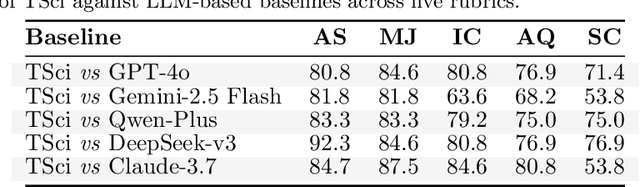
Time series forecasting is central to decision-making in domains as diverse as energy, finance, climate, and public health. In practice, forecasters face thousands of short, noisy series that vary in frequency, quality, and horizon, where the dominant cost lies not in model fitting, but in the labor-intensive preprocessing, validation, and ensembling required to obtain reliable predictions. Prevailing statistical and deep learning models are tailored to specific datasets or domains and generalize poorly. A general, domain-agnostic framework that minimizes human intervention is urgently in demand. In this paper, we introduce TimeSeriesScientist (TSci), the first LLM-driven agentic framework for general time series forecasting. The framework comprises four specialized agents: Curator performs LLM-guided diagnostics augmented by external tools that reason over data statistics to choose targeted preprocessing; Planner narrows the hypothesis space of model choice by leveraging multi-modal diagnostics and self-planning over the input; Forecaster performs model fitting and validation and, based on the results, adaptively selects the best model configuration as well as ensemble strategy to make final predictions; and Reporter synthesizes the whole process into a comprehensive, transparent report. With transparent natural-language rationales and comprehensive reports, TSci transforms the forecasting workflow into a white-box system that is both interpretable and extensible across tasks. Empirical results on eight established benchmarks demonstrate that TSci consistently outperforms both statistical and LLM-based baselines, reducing forecast error by an average of 10.4% and 38.2%, respectively. Moreover, TSci produces a clear and rigorous report that makes the forecasting workflow more transparent and interpretable.
CDS: Data Synthesis Method Guided by Cognitive Diagnosis Theory
Jan 13, 2025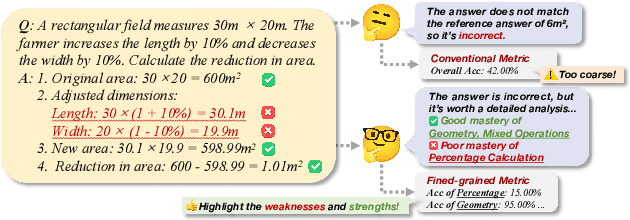
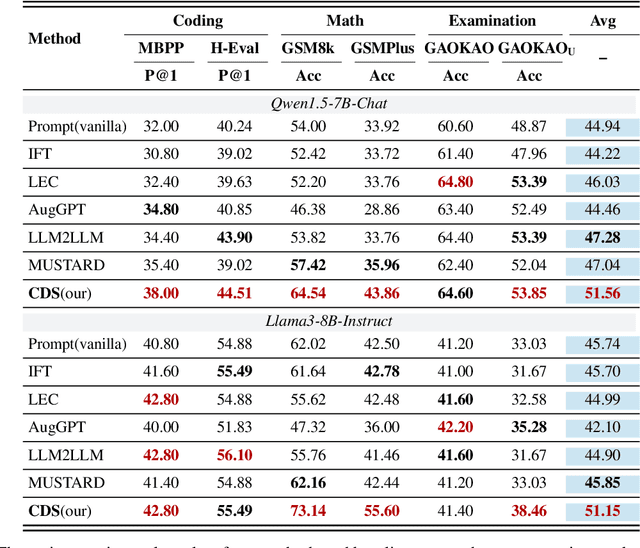
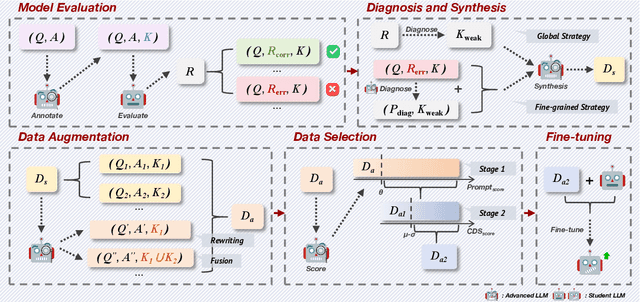
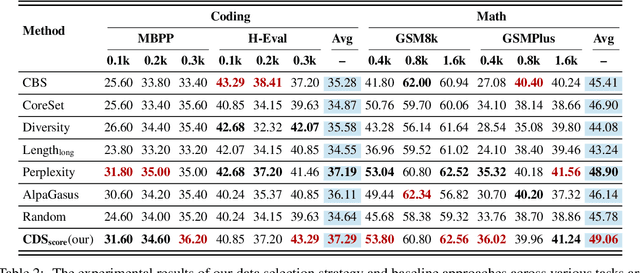
Large Language Models (LLMs) have demonstrated outstanding capabilities across various domains, but the increasing complexity of new challenges demands enhanced performance and adaptability. Traditional benchmarks, although comprehensive, often lack the granularity needed for detailed capability analysis. This study introduces the Cognitive Diagnostic Synthesis (CDS) method, which employs Cognitive Diagnosis Theory (CDT) for precise evaluation and targeted enhancement of LLMs. By decomposing complex tasks into discrete knowledge points, CDS accurately identifies and synthesizes data targeting model weaknesses, thereby enhancing the model's performance. This framework proposes a comprehensive pipeline driven by knowledge point evaluation, synthesis, data augmentation, and filtering, which significantly improves the model's mathematical and coding capabilities, achieving up to an 11.12% improvement in optimal scenarios.
Think Thrice Before You Act: Progressive Thought Refinement in Large Language Models
Oct 17, 2024



Recent advancements in large language models (LLMs) have demonstrated that progressive refinement, rather than providing a single answer, results in more accurate and thoughtful outputs. However, existing methods often rely heavily on supervision signals to evaluate previous responses, making it difficult to assess output quality in more open-ended scenarios effectively. Additionally, these methods are typically designed for specific tasks, which limits their generalization to new domains. To address these limitations, we propose Progressive Thought Refinement (PTR), a framework that enables LLMs to refine their responses progressively. PTR operates in two phases: (1) Thought data construction stage: We propose a weak and strong model collaborative selection strategy to build a high-quality progressive refinement dataset to ensure logical consistency from thought to answers, and the answers are gradually refined in each round. (2) Thought-Mask Fine-Tuning Phase: We design a training structure to mask the "thought" and adjust loss weights to encourage LLMs to refine prior thought, teaching them to implicitly understand "how to improve" rather than "what is correct." Experimental results show that PTR significantly enhances LLM performance across ten diverse tasks (avg. from 49.6% to 53.5%) without task-specific fine-tuning. Notably, in more open-ended tasks, LLMs also demonstrate substantial improvements in the quality of responses beyond mere accuracy, suggesting that PTR truly teaches LLMs to self-improve over time.
SED: Self-Evaluation Decoding Enhances Large Language Models for Better Generation
May 26, 2024Existing Large Language Models (LLMs) generate text through unidirectional autoregressive decoding methods to respond to various user queries. These methods tend to consider token selection in a simple sequential manner, making it easy to fall into suboptimal options when encountering uncertain tokens, referred to as chaotic points in our work. Many chaotic points exist in texts generated by LLMs, and they often significantly affect the quality of subsequently generated tokens, which can interfere with LLMs' generation. This paper proposes Self-Evaluation Decoding, SED, a decoding method for enhancing model generation. Analogous to the human decision-making process, SED integrates speculation and evaluation steps into the decoding process, allowing LLMs to make more careful decisions and thus optimize token selection at chaotic points. Experimental results across various tasks using different LLMs demonstrate SED's effectiveness.
Large Language Model Can Continue Evolving From Mistakes
Apr 11, 2024



Large Language Models (LLMs) demonstrate impressive performance in various downstream tasks. However, they may still generate incorrect responses in certain scenarios due to the knowledge deficiencies and the flawed pre-training data. Continual Learning (CL) is a commonly used method to address this issue. Traditional CL is task-oriented, using novel or factually accurate data to retrain LLMs from scratch. However, this method requires more task-related training data and incurs expensive training costs. To address this challenge, we propose the Continue Evolving from Mistakes (CEM) method, inspired by the 'summarize mistakes' learning skill, to achieve iterative refinement of LLMs. Specifically, the incorrect responses of LLMs indicate knowledge deficiencies related to the questions. Therefore, we collect corpora with these knowledge from multiple data sources and follow it up with iterative supplementary training for continuous, targeted knowledge updating and supplementation. Meanwhile, we developed two strategies to construct supplementary training sets to enhance the LLM's understanding of the corpus and prevent catastrophic forgetting. We conducted extensive experiments to validate the effectiveness of this CL method. In the best case, our method resulted in a 17.00\% improvement in the accuracy of the LLM.