 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Negative Samples Are Equal: LLMs Learn Better from Plausible Reasoning
Feb 03, 2026Learning from negative samples holds great promise for improving Large Language Model (LLM) reasoning capability, yet existing methods treat all incorrect responses as equally informative, overlooking the crucial role of sample quality. To address this, we propose Plausible Negative Samples (PNS), a method that synthesizes high-quality negative samples exhibiting expected format and structural coherence while ultimately yielding incorrect answers. PNS trains a dedicated model via reverse reinforcement learning (RL) guided by a composite reward combining format compliance, accuracy inversion, reward model assessment, and chain-of-thought evaluation, generating responses nearly indistinguishable from correct solutions. We further validate PNS as a plug-and-play data source for preference optimization across three backbone models on seven mathematical reasoning benchmarks. Results demonstrate that PNS consistently outperforms other negative sample synthesis methods, achieving an average improvement of 2.03% over RL-trained models.
Structured Reasoning for Large Language Models
Jan 12, 2026Large language models (LLMs) achieve strong performance by generating long chains of thought, but longer traces always introduce redundant or ineffective reasoning steps. One typical behavior is that they often perform unnecessary verification and revisions even if they have reached the correct answers. This limitation stems from the unstructured nature of reasoning trajectories and the lack of targeted supervision for critical reasoning abilities. To address this, we propose Structured Reasoning (SCR), a framework that decouples reasoning trajectories into explicit, evaluable, and trainable components. We mainly implement SCR using a Generate-Verify-Revise paradigm. Specifically, we construct structured training data and apply Dynamic Termination Supervision to guide the model in deciding when to terminate reasoning. To avoid interference between learning signals for different reasoning abilities, we adopt a progressive two-stage reinforcement learning strategy: the first stage targets initial generation and self-verification, and the second stage focuses on revision. Extensive experiments on three backbone models show that SCR substantially improves reasoning efficiency and self-verification. Besides, compared with existing reasoning paradigms, it reduces output token length by up to 50%.
HINT: Helping Ineffective Rollouts Navigate Towards Effectiveness
Oct 10, 2025Reinforcement Learning (RL) has become a key driver for enhancing the long chain-of-thought (CoT) reasoning capabilities of Large Language Models (LLMs). However, prevalent methods like GRPO often fail when task difficulty exceeds the model's capacity, leading to reward sparsity and inefficient training. While prior work attempts to mitigate this using off-policy data, such as mixing RL with Supervised Fine-Tuning (SFT) or using hints, they often misguide policy updates In this work, we identify a core issue underlying these failures, which we term low training affinity. This condition arises from a large distributional mismatch between external guidance and the model's policy. To diagnose this, we introduce Affinity, the first quantitative metric for monitoring exploration efficiency and training stability. To improve Affinity, we propose HINT: Helping Ineffective rollouts Navigate Towards effectiveness, an adaptive hinting framework. Instead of providing direct answers, HINT supplies heuristic hints that guide the model to discover solutions on its own, preserving its autonomous reasoning capabilities. Extensive experiments on mathematical reasoning tasks show that HINT consistently outperforms existing methods, achieving state-of-the-art results with models of various scales, while also demonstrating significantly more stable learning and greater data efficiency.Code is available on Github.
CoCoB: Adaptive Collaborative Combinatorial Bandits for Online Recommendation
May 05, 2025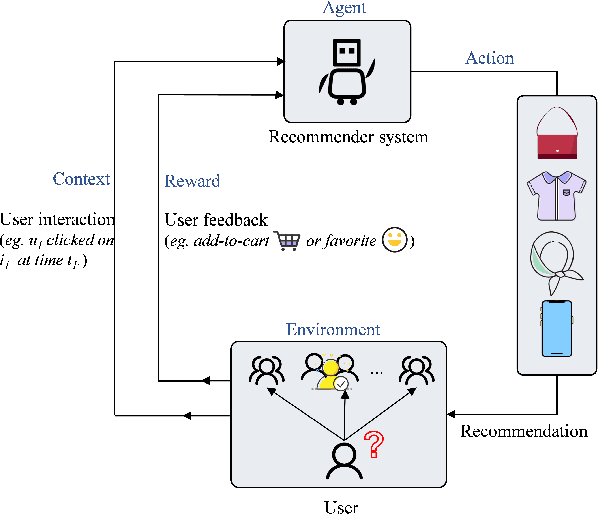

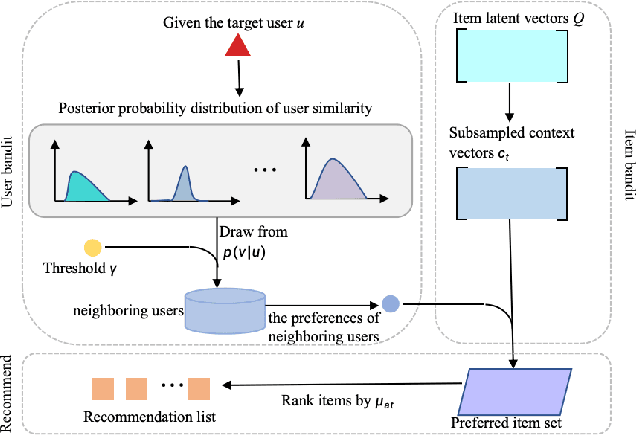

Clustering bandits have gained significant attention in recommender systems by leveraging collaborative information from neighboring users to better capture target user preferences. However, these methods often lack a clear definition of similar users and face challenges when users with unique preferences lack appropriate neighbors. In such cases, relying on divergent preferences of misidentified neighbors can degrade recommendation quality. To address these limitations, this paper proposes an adaptive Collaborative Combinatorial Bandits algorithm (CoCoB). CoCoB employs an innovative two-sided bandit architecture, applying bandit principles to both the user and item sides. The user-bandit employs an enhanced Bayesian model to explore user similarity, identifying neighbors based on a similarity probability threshold. The item-bandit treats items as arms, generating diverse recommendations informed by the user-bandit's output. CoCoB dynamically adapts, leveraging neighbor preferences when available or focusing solely on the target user otherwise. Regret analysis under a linear contextual bandit setting and experiments on three real-world datasets demonstrate CoCoB's effectiveness, achieving an average 2.4% improvement in F1 score over state-of-the-art methods.
CDS: Data Synthesis Method Guided by Cognitive Diagnosis Theory
Jan 13, 2025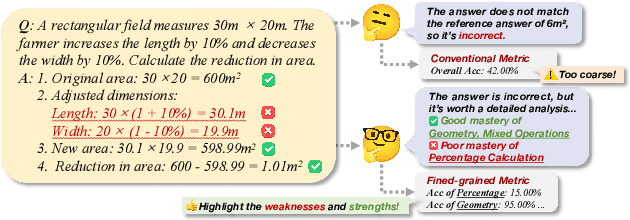
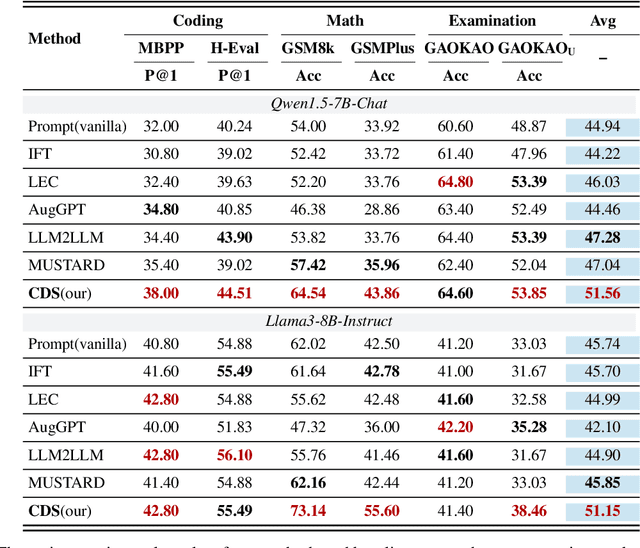
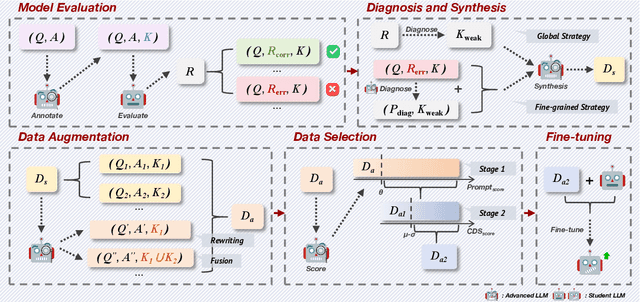
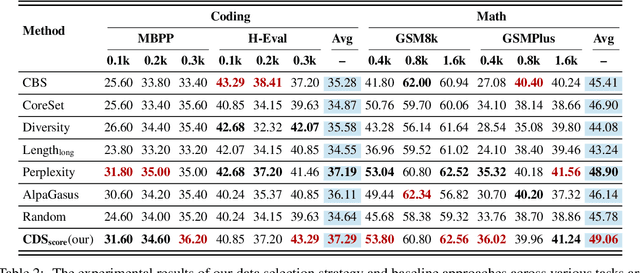
Large Language Models (LLMs) have demonstrated outstanding capabilities across various domains, but the increasing complexity of new challenges demands enhanced performance and adaptability. Traditional benchmarks, although comprehensive, often lack the granularity needed for detailed capability analysis. This study introduces the Cognitive Diagnostic Synthesis (CDS) method, which employs Cognitive Diagnosis Theory (CDT) for precise evaluation and targeted enhancement of LLMs. By decomposing complex tasks into discrete knowledge points, CDS accurately identifies and synthesizes data targeting model weaknesses, thereby enhancing the model's performance. This framework proposes a comprehensive pipeline driven by knowledge point evaluation, synthesis, data augmentation, and filtering, which significantly improves the model's mathematical and coding capabilities, achieving up to an 11.12% improvement in optimal scenarios.
Think Thrice Before You Act: Progressive Thought Refinement in Large Language Models
Oct 17, 2024



Recent advancements in large language models (LLMs) have demonstrated that progressive refinement, rather than providing a single answer, results in more accurate and thoughtful outputs. However, existing methods often rely heavily on supervision signals to evaluate previous responses, making it difficult to assess output quality in more open-ended scenarios effectively. Additionally, these methods are typically designed for specific tasks, which limits their generalization to new domains. To address these limitations, we propose Progressive Thought Refinement (PTR), a framework that enables LLMs to refine their responses progressively. PTR operates in two phases: (1) Thought data construction stage: We propose a weak and strong model collaborative selection strategy to build a high-quality progressive refinement dataset to ensure logical consistency from thought to answers, and the answers are gradually refined in each round. (2) Thought-Mask Fine-Tuning Phase: We design a training structure to mask the "thought" and adjust loss weights to encourage LLMs to refine prior thought, teaching them to implicitly understand "how to improve" rather than "what is correct." Experimental results show that PTR significantly enhances LLM performance across ten diverse tasks (avg. from 49.6% to 53.5%) without task-specific fine-tuning. Notably, in more open-ended tasks, LLMs also demonstrate substantial improvements in the quality of responses beyond mere accuracy, suggesting that PTR truly teaches LLMs to self-improve over time.