 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Reasoning for Large Language Models
Jan 12, 2026Large language models (LLMs) achieve strong performance by generating long chains of thought, but longer traces always introduce redundant or ineffective reasoning steps. One typical behavior is that they often perform unnecessary verification and revisions even if they have reached the correct answers. This limitation stems from the unstructured nature of reasoning trajectories and the lack of targeted supervision for critical reasoning abilities. To address this, we propose Structured Reasoning (SCR), a framework that decouples reasoning trajectories into explicit, evaluable, and trainable components. We mainly implement SCR using a Generate-Verify-Revise paradigm. Specifically, we construct structured training data and apply Dynamic Termination Supervision to guide the model in deciding when to terminate reasoning. To avoid interference between learning signals for different reasoning abilities, we adopt a progressive two-stage reinforcement learning strategy: the first stage targets initial generation and self-verification, and the second stage focuses on revision. Extensive experiments on three backbone models show that SCR substantially improves reasoning efficiency and self-verification. Besides, compared with existing reasoning paradigms, it reduces output token length by up to 50%.
LSRIF: Logic-Structured Reinforcement Learning for Instruction Following
Jan 10, 2026Instruction-following is critical for large language models, but real-world instructions often contain logical structures such as sequential dependencies and conditional branching. Existing methods typically construct datasets with parallel constraints and optimize average rewards, ignoring logical dependencies and yielding noisy signals. We propose a logic-structured training framework LSRIF that explicitly models instruction logic. We first construct a dataset LSRInstruct with constraint structures such as parallel, sequential, and conditional types, and then design structure-aware rewarding method LSRIF including average aggregation for parallel structures, failure-penalty propagation for sequential structures, and selective rewards for conditional branches. Experiments show LSRIF brings significant improvements in instruction-following (in-domain and out-of-domain) and general reasoning. Analysis reveals that learning with explicit logic structures brings parameter updates in attention layers and sharpens token-level attention to constraints and logical operators.
ComLQ: Benchmarking Complex Logical Queries in Information Retrieval
Nov 15, 2025

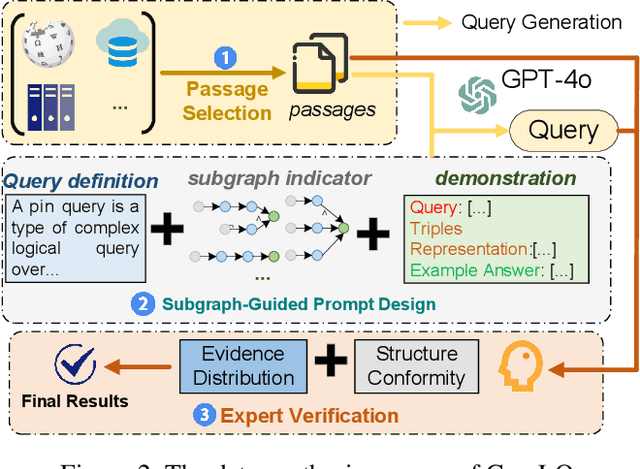

Information retrieval (IR) systems play a critical role in navigating information overload across various applications. Existing IR benchmarks primarily focus on simple queries that are semantically analogous to single- and multi-hop relations, overlooking \emph{complex logical queries} involving first-order logic operations such as conjunction ($\land$), disjunction ($\lor$), and negation ($\lnot$). Thus, these benchmarks can not be used to sufficiently evaluate the performance of IR models on complex queries in real-world scenarios. To address this problem, we propose a novel method leveraging large language models (LLMs) to construct a new IR dataset \textbf{ComLQ} for \textbf{Com}plex \textbf{L}ogical \textbf{Q}ueries, which comprises 2,909 queries and 11,251 candidate passages. A key challenge in constructing the dataset lies in capturing the underlying logical structures within unstructured text. Therefore, by designing the subgraph-guided prompt with the subgraph indicator, an LLM (such as GPT-4o) is guided to generate queries with specific logical structures based on selected passages. All query-passage pairs in ComLQ are ensured \emph{structure conformity} and \emph{evidence distribution} through expert annotation. To better evaluate whether retrievers can handle queries with negation, we further propose a new evaluation metric, \textbf{Log-Scaled Negation Consistency} (\textbf{LSNC@$K$}). As a supplement to standard relevance-based metrics (such as nDCG and mAP), LSNC@$K$ measures whether top-$K$ retrieved passages violate negation conditions in queries. Our experimental results under zero-shot settings demonstrate existing retrieval models' limited performance on complex logical queries, especially on queries with negation, exposing their inferior capabilities of modeling exclusion.
Instructions are all you need: Self-supervised Reinforcement Learning for Instruction Following
Oct 16, 2025Language models often struggle to follow multi-constraint instructions that are crucial for real-world applications. Existing reinforcement learning (RL) approaches suffer from dependency on external supervision and sparse reward signals from multi-constraint tasks. We propose a label-free self-supervised RL framework that eliminates dependency on external supervision by deriving reward signals directly from instructions and generating pseudo-labels for reward model training. Our approach introduces constraint decomposition strategies and efficient constraint-wise binary classification to address sparse reward challenges while maintaining computational efficiency. Experiments show that our approach generalizes well, achieving strong improvements across 3 in-domain and 5 out-of-domain datasets, including challenging agentic and multi-turn instruction following. The data and code are publicly available at https://github.com/Rainier-rq/verl-if
HINT: Helping Ineffective Rollouts Navigate Towards Effectiveness
Oct 10, 2025Reinforcement Learning (RL) has become a key driver for enhancing the long chain-of-thought (CoT) reasoning capabilities of Large Language Models (LLMs). However, prevalent methods like GRPO often fail when task difficulty exceeds the model's capacity, leading to reward sparsity and inefficient training. While prior work attempts to mitigate this using off-policy data, such as mixing RL with Supervised Fine-Tuning (SFT) or using hints, they often misguide policy updates In this work, we identify a core issue underlying these failures, which we term low training affinity. This condition arises from a large distributional mismatch between external guidance and the model's policy. To diagnose this, we introduce Affinity, the first quantitative metric for monitoring exploration efficiency and training stability. To improve Affinity, we propose HINT: Helping Ineffective rollouts Navigate Towards effectiveness, an adaptive hinting framework. Instead of providing direct answers, HINT supplies heuristic hints that guide the model to discover solutions on its own, preserving its autonomous reasoning capabilities. Extensive experiments on mathematical reasoning tasks show that HINT consistently outperforms existing methods, achieving state-of-the-art results with models of various scales, while also demonstrating significantly more stable learning and greater data efficiency.Code is available on Github.
CultureScope: A Dimensional Lens for Probing Cultural Understanding in LLMs
Sep 19, 2025As large language models (LLMs) are increasingly deployed in diverse cultural environments, evaluating their cultural understanding capability has become essential for ensuring trustworthy and culturally aligned applications. However, most existing benchmarks lack comprehensiveness and are challenging to scale and adapt across different cultural contexts, because their frameworks often lack guidance from well-established cultural theories and tend to rely on expert-driven manual annotations. To address these issues, we propose CultureScope, the most comprehensive evaluation framework to date for assessing cultural understanding in LLMs. Inspired by the cultural iceberg theory, we design a novel dimensional schema for cultural knowledge classification, comprising 3 layers and 140 dimensions, which guides the automated construction of culture-specific knowledge bases and corresponding evaluation datasets for any given languages and cultures. Experimental results demonstrate that our method can effectively evaluate cultural understanding. They also reveal that existing large language models lack comprehensive cultural competence, and merely incorporating multilingual data does not necessarily enhance cultural understanding. All code and data files are available at https://github.com/HoganZinger/Culture
GORACS: Group-level Optimal Transport-guided Coreset Selection for LLM-based Recommender Systems
Jun 04, 2025Although large language models (LLMs) have shown great potential in recommender systems, the prohibitive computational costs for fine-tuning LLMs on entire datasets hinder their successful deployment in real-world scenarios. To develop affordable and effective LLM-based recommender systems, we focus on the task of coreset selection which identifies a small subset of fine-tuning data to optimize the test loss, thereby facilitating efficient LLMs' fine-tuning. Although there exist some intuitive solutions of subset selection, including distribution-based and importance-based approaches, they often lead to suboptimal performance due to the misalignment with downstream fine-tuning objectives or weak generalization ability caused by individual-level sample selection. To overcome these challenges, we propose GORACS, which is a novel Group-level Optimal tRAnsport-guided Coreset Selection framework for LLM-based recommender systems. GORACS is designed based on two key principles for coreset selection: 1) selecting the subsets that minimize the test loss to align with fine-tuning objectives, and 2) enhancing model generalization through group-level data selection. Corresponding to these two principles, GORACS has two key components: 1) a Proxy Optimization Objective (POO) leveraging optimal transport and gradient information to bound the intractable test loss, thus reducing computational costs by avoiding repeated LLM retraining, and 2) a two-stage Initialization-Then-Refinement Algorithm (ITRA) for efficient group-level selection. Our extensive experiments across diverse recommendation datasets and tasks validate that GORACS significantly reduces fine-tuning costs of LLMs while achieving superior performance over the state-of-the-art baselines and full data training. The source code of GORACS are available at https://github.com/Mithas-114/GORACS.
Logical Consistency is Vital: Neural-Symbolic Information Retrieval for Negative-Constraint Queries
May 29, 2025

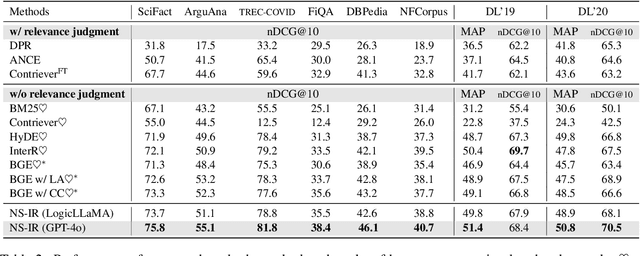
Information retrieval plays a crucial role in resource localization. Current dense retrievers retrieve the relevant documents within a corpus via embedding similarities, which compute similarities between dense vectors mainly depending on word co-occurrence between queries and documents, but overlook the real query intents. Thus, they often retrieve numerous irrelevant documents. Particularly in the scenarios of complex queries such as \emph{negative-constraint queries}, their retrieval performance could be catastrophic. To address the issue, we propose a neuro-symbolic information retrieval method, namely \textbf{NS-IR}, that leverages first-order logic (FOL) to optimize the embeddings of naive natural language by considering the \emph{logical consistency} between queries and documents. Specifically, we introduce two novel techniques, \emph{logic alignment} and \emph{connective constraint}, to rerank candidate documents, thereby enhancing retrieval relevance. Furthermore, we construct a new dataset \textbf{NegConstraint} including negative-constraint queries to evaluate our NS-IR's performance on such complex IR scenarios. Our extensive experiments demonstrate that NS-IR not only achieves superior zero-shot retrieval performance on web search and low-resource retrieval tasks, but also performs better on negative-constraint queries. Our scource code and dataset are available at https://github.com/xgl-git/NS-IR-main.
ChemHAS: Hierarchical Agent Stacking for Enhancing Chemistry Tools
May 27, 2025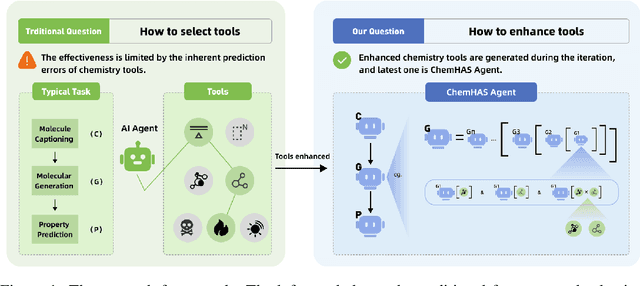
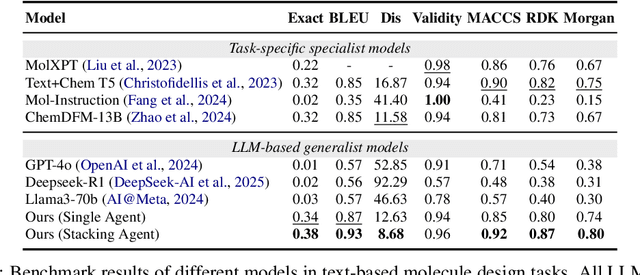
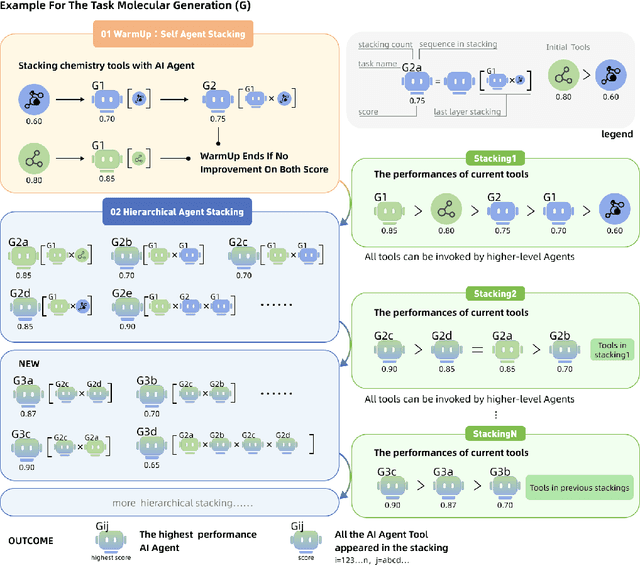
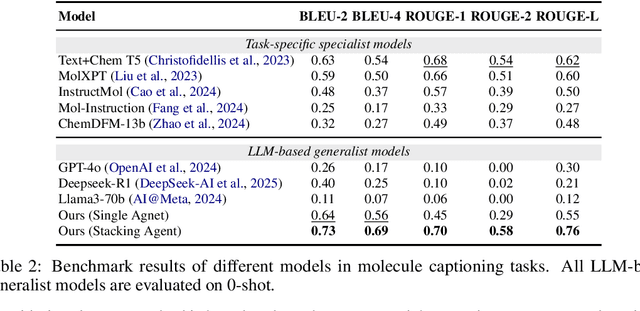
Large Language Model (LLM)-based agents have demonstrated the ability to improve performance in chemistry-related tasks by selecting appropriate tools. However, their effectiveness remains limited by the inherent prediction errors of chemistry tools. In this paper, we take a step further by exploring how LLMbased agents can, in turn, be leveraged to reduce prediction errors of the tools. To this end, we propose ChemHAS (Chemical Hierarchical Agent Stacking), a simple yet effective method that enhances chemistry tools through optimizing agent-stacking structures from limited data. ChemHAS achieves state-of-the-art performance across four fundamental chemistry tasks, demonstrating that our method can effectively compensate for prediction errors of the tools. Furthermore, we identify and characterize four distinct agent-stacking behaviors, potentially improving interpretability and revealing new possibilities for AI agent applications in scientific research. Our code and dataset are publicly available at https: //anonymous.4open.science/r/ChemHAS-01E4/README.md.
RLAP: A Reinforcement Learning Enhanced Adaptive Planning Framework for Multi-step NLP Task Solving
May 17, 2025Multi-step planning has been widely employed to enhance the performance of large language models (LLMs) on downstream natural language processing (NLP) tasks, which decomposes the original task into multiple subtasks and guide LLMs to solve them sequentially without additional training. When addressing task instances, existing methods either preset the order of steps or attempt multiple paths at each step. However, these methods overlook instances' linguistic features and rely on the intrinsic planning capabilities of LLMs to evaluate intermediate feedback and then select subtasks, resulting in suboptimal outcomes. To better solve multi-step NLP tasks with LLMs, in this paper we propose a Reinforcement Learning enhanced Adaptive Planning framework (RLAP). In our framework, we model an NLP task as a Markov decision process (MDP) and employ an LLM directly into the environment. In particular, a lightweight Actor model is trained to estimate Q-values for natural language sequences consisting of states and actions through reinforcement learning. Therefore, during sequential planning, the linguistic features of each sequence in the MDP can be taken into account, and the Actor model interacts with the LLM to determine the optimal order of subtasks for each task instance. We apply RLAP on three different types of NLP tasks and conduct extensive experiments on multiple datasets to verify RLAP's effectiveness and robustness.