 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching LLMs to Learn Tool Trialing and Execution through Environment Interaction
Jan 19, 2026Equipping Large Language Models (LLMs) with external tools enables them to solve complex real-world problems. However, the robustness of existing methods remains a critical challenge when confronting novel or evolving tools. Existing trajectory-centric paradigms primarily rely on memorizing static solution paths during training, which limits the ability of LLMs to generalize tool usage to newly introduced or previously unseen tools. In this paper, we propose ToolMaster, a framework that shifts tool use from imitating golden tool-calling trajectories to actively learning tool usage through interaction with the environment. To optimize LLMs for tool planning and invocation, ToolMaster adopts a trial-and-execution paradigm, which trains LLMs to first imitate teacher-generated trajectories containing explicit tool trials and self-correction, followed by reinforcement learning to coordinate the trial and execution phases jointly. This process enables agents to autonomously explore correct tool usage by actively interacting with environments and forming experiential knowledge that benefits tool execution. Experimental results demonstrate that ToolMaster significantly outperforms existing baselines in terms of generalization and robustness across unseen or unfamiliar tools. All code and data are available at https://github.com/NEUIR/ToolMaster.
Long-Chain Reasoning Distillation via Adaptive Prefix Alignment
Jan 15, 2026Large Language Models (LLMs) have demonstrated remarkable reasoning capabilities, particularly in solving complex mathematical problems. Recent studies show that distilling long reasoning trajectories can effectively enhance the reasoning performance of small-scale student models. However, teacher-generated reasoning trajectories are often excessively long and structurally complex, making them difficult for student models to learn. This mismatch leads to a gap between the provided supervision signal and the learning capacity of the student model. To address this challenge, we propose Prefix-ALIGNment distillation (P-ALIGN), a framework that fully exploits teacher CoTs for distillation through adaptive prefix alignment. Specifically, P-ALIGN adaptively truncates teacher-generated reasoning trajectories by determining whether the remaining suffix is concise and sufficient to guide the student model. Then, P-ALIGN leverages the teacher-generated prefix to supervise the student model, encouraging effective prefix alignment. Experiments on multiple mathematical reasoning benchmarks demonstrate that P-ALIGN outperforms all baselines by over 3%. Further analysis indicates that the prefixes constructed by P-ALIGN provide more effective supervision signals, while avoiding the negative impact of redundant and uncertain reasoning components. All code is available at https://github.com/NEUIR/P-ALIGN.
Taxon: Hierarchical Tax Code Prediction with Semantically Aligned LLM Expert Guidance
Jan 13, 2026Tax code prediction is a crucial yet underexplored task in automating invoicing and compliance management for large-scale e-commerce platforms. Each product must be accurately mapped to a node within a multi-level taxonomic hierarchy defined by national standards, where errors lead to financial inconsistencies and regulatory risks. This paper presents Taxon, a semantically aligned and expert-guided framework for hierarchical tax code prediction. Taxon integrates (i) a feature-gating mixture-of-experts architecture that adaptively routes multi-modal features across taxonomy levels, and (ii) a semantic consistency model distilled from large language models acting as domain experts to verify alignment between product titles and official tax definitions. To address noisy supervision in real business records, we design a multi-source training pipeline that combines curated tax databases, invoice validation logs, and merchant registration data to provide both structural and semantic supervision. Extensive experiments on the proprietary TaxCode dataset and public benchmarks demonstrate that Taxon achieves state-of-the-art performance, outperforming strong baselines. Further, an additional full hierarchical paths reconstruction procedure significantly improves structural consistency, yielding the highest overall F1 scores. Taxon has been deployed in production within Alibaba's tax service system, handling an average of over 500,000 tax code queries per day and reaching peak volumes above five million requests during business event with improved accuracy, interpretability, and robustness.
Towards Human-Like Grading: A Unified LLM-Enhanced Framework for Subjective Question Evaluation
Oct 09, 2025Automatic grading of subjective questions remains a significant challenge in examination assessment due to the diversity in question formats and the open-ended nature of student responses. Existing works primarily focus on a specific type of subjective question and lack the generality to support comprehensive exams that contain diverse question types. In this paper, we propose a unified Large Language Model (LLM)-enhanced auto-grading framework that provides human-like evaluation for all types of subjective questions across various domains. Our framework integrates four complementary modules to holistically evaluate student answers. In addition to a basic text matching module that provides a foundational assessment of content similarity, we leverage the powerful reasoning and generative capabilities of LLMs to: (1) compare key knowledge points extracted from both student and reference answers, (2) generate a pseudo-question from the student answer to assess its relevance to the original question, and (3) simulate human evaluation by identifying content-related and non-content strengths and weaknesses. Extensive experiments on both general-purpose and domain-specific datasets show that our framework consistently outperforms traditional and LLM-based baselines across multiple grading metrics. Moreover, the proposed system has been successfully deployed in real-world training and certification exams at a major e-commerce enterprise.
SEAL: Structure and Element Aware Learning to Improve Long Structured Document Retrieval
Aug 28, 2025In long structured document retrieval, existing methods typically fine-tune pre-trained language models (PLMs) using contrastive learning on datasets lacking explicit structural information. This practice suffers from two critical issues: 1) current methods fail to leverage structural features and element-level semantics effectively, and 2) the lack of datasets containing structural metadata. To bridge these gaps, we propose \our, a novel contrastive learning framework. It leverages structure-aware learning to preserve semantic hierarchies and masked element alignment for fine-grained semantic discrimination. Furthermore, we release \dataset, a long structured document retrieval dataset with rich structural annotations. Extensive experiments on both released and industrial datasets across various modern PLMs, along with online A/B testing, demonstrate consistent performance improvements, boosting NDCG@10 from 73.96\% to 77.84\% on BGE-M3. The resources are available at https://github.com/xinhaoH/SEAL.
Enhancing the Patent Matching Capability of Large Language Models via the Memory Graph
Apr 21, 2025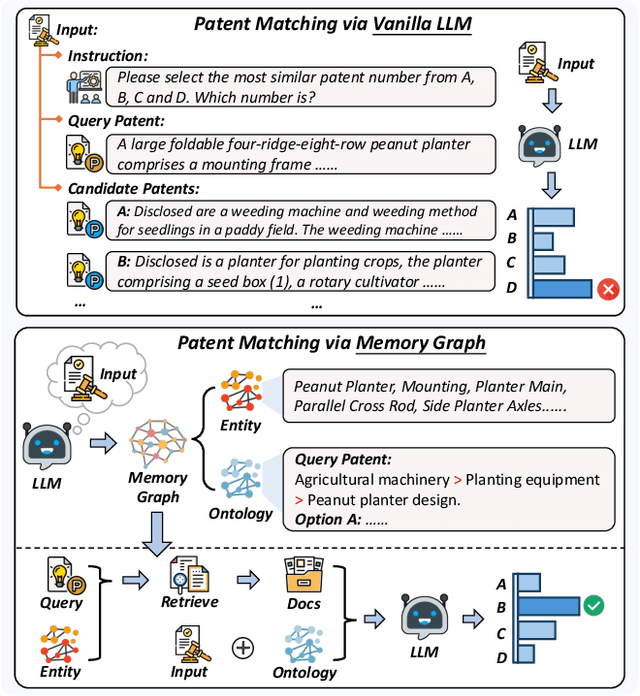

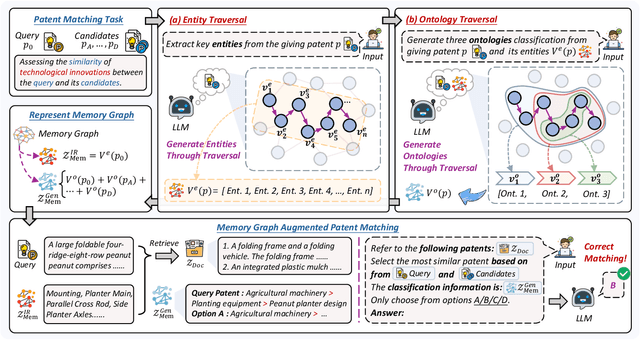
Intellectual Property (IP) management involves strategically protecting and utilizing intellectual assets to enhance organizational innovation, competitiveness, and value creation. Patent matching is a crucial task in intellectual property management, which facilitates the organization and utilization of patents. Existing models often rely on the emergent capabilities of Large Language Models (LLMs) and leverage them to identify related patents directly. However, these methods usually depend on matching keywords and overlook the hierarchical classification and categorical relationships of patents. In this paper, we propose MemGraph, a method that augments the patent matching capabilities of LLMs by incorporating a memory graph derived from their parametric memory. Specifically, MemGraph prompts LLMs to traverse their memory to identify relevant entities within patents, followed by attributing these entities to corresponding ontologies. After traversing the memory graph, we utilize extracted entities and ontologies to improve the capability of LLM in comprehending the semantics of patents. Experimental results on the PatentMatch dataset demonstrate the effectiveness of MemGraph, achieving a 17.68% performance improvement over baseline LLMs. The further analysis highlights the generalization ability of MemGraph across various LLMs, both in-domain and out-of-domain, and its capacity to enhance the internal reasoning processes of LLMs during patent matching. All data and codes are available at https://github.com/NEUIR/MemGraph.
Addressing Information Loss and Interaction Collapse: A Dual Enhanced Attention Framework for Feature Interaction
Mar 14, 2025The Transformer has proven to be a significant approach in feature interaction for CTR prediction, achieving considerable success in previous works. However, it also presents potential challenges in handling feature interactions. Firstly, Transformers may encounter information loss when capturing feature interactions. By relying on inner products to represent pairwise relationships, they compress raw interaction information, which can result in a degradation of fidelity. Secondly, due to the long-tail features distribution, feature fields with low information-abundance embeddings constrain the information abundance of other fields, leading to collapsed embedding matrices. To tackle these issues, we propose a Dual Attention Framework for Enhanced Feature Interaction, known as Dual Enhanced Attention. This framework integrates two attention mechanisms: the Combo-ID attention mechanism and the collapse-avoiding attention mechanism. The Combo-ID attention mechanism directly retains feature interaction pairs to mitigate information loss, while the collapse-avoiding attention mechanism adaptively filters out low information-abundance interaction pairs to prevent interaction collapse. Extensive experiments conducted on industrial datasets have shown the effectiveness of Dual Enhanced Attention.
Hierarchical Causal Transformer with Heterogeneous Information for Expandable Sequential Recommendation
Mar 04, 2025



Sequential recommendation systems leveraging transformer architectures have demonstrated exceptional capabilities in capturing user behavior patterns. At the core of these systems lies the critical challenge of constructing effective item representations. Traditional approaches employ feature fusion through simple concatenation or basic neural architectures to create uniform representation sequences. However, these conventional methods fail to address the intrinsic diversity of item attributes, thereby constraining the transformer's capacity to discern fine-grained patterns and hindering model extensibility. Although recent research has begun incorporating user-related heterogeneous features into item sequences, the equally crucial item-side heterogeneous feature continue to be neglected. To bridge this methodological gap, we present HeterRec - an innovative framework featuring two novel components: the Heterogeneous Token Flattening Layer (HTFL) and Hierarchical Causal Transformer (HCT). HTFL pioneers a sophisticated tokenization mechanism that decomposes items into multi-dimensional token sets and structures them into heterogeneous sequences, enabling scalable performance enhancement through model expansion. The HCT architecture further enhances pattern discovery through token-level and item-level attention mechanisms. furthermore, we develop a Listwise Multi-step Prediction (LMP) objective function to optimize learning process. Rigorous validation, including real-world industrial platforms, confirms HeterRec's state-of-the-art performance in both effective and efficiency.
Efficient Long Sequential Low-rank Adaptive Attention for Click-through rate Prediction
Mar 04, 2025In the context of burgeoning user historical behavior data, Accurate click-through rate(CTR) prediction requires effective modeling of lengthy user behavior sequences. As the volume of such data keeps swelling, the focus of research has shifted towards developing effective long-term behavior modeling methods to capture latent user interests. Nevertheless, the complexity introduced by large scale data brings about computational hurdles. There is a pressing need to strike a balance between achieving high model performance and meeting the strict response time requirements of online services. While existing retrieval-based methods (e.g., similarity filtering or attention approximation) achieve practical runtime efficiency, they inherently compromise information fidelity through aggressive sequence truncation or attention sparsification. This paper presents a novel attention mechanism. It overcomes the shortcomings of existing methods while ensuring computational efficiency. This mechanism learn compressed representation of sequence with length $L$ via low-rank projection matrices (rank $r \ll L$), reducing attention complexity from $O(L)$ to $O(r)$. It also integrates a uniquely designed loss function to preserve nonlinearity of attention. In the inference stage, the mechanism adopts matrix absorption and prestorage strategies. These strategies enable it to effectively satisfy online constraints. Comprehensive offline and online experiments demonstrate that the proposed method outperforms current state-of-the-art solutions.
Think Thrice Before You Act: Progressive Thought Refinement in Large Language Models
Oct 17, 2024



Recent advancements in large language models (LLMs) have demonstrated that progressive refinement, rather than providing a single answer, results in more accurate and thoughtful outputs. However, existing methods often rely heavily on supervision signals to evaluate previous responses, making it difficult to assess output quality in more open-ended scenarios effectively. Additionally, these methods are typically designed for specific tasks, which limits their generalization to new domains. To address these limitations, we propose Progressive Thought Refinement (PTR), a framework that enables LLMs to refine their responses progressively. PTR operates in two phases: (1) Thought data construction stage: We propose a weak and strong model collaborative selection strategy to build a high-quality progressive refinement dataset to ensure logical consistency from thought to answers, and the answers are gradually refined in each round. (2) Thought-Mask Fine-Tuning Phase: We design a training structure to mask the "thought" and adjust loss weights to encourage LLMs to refine prior thought, teaching them to implicitly understand "how to improve" rather than "what is correct." Experimental results show that PTR significantly enhances LLM performance across ten diverse tasks (avg. from 49.6% to 53.5%) without task-specific fine-tuning. Notably, in more open-ended tasks, LLMs also demonstrate substantial improvements in the quality of responses beyond mere accuracy, suggesting that PTR truly teaches LLMs to self-improve over time.