 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAREAgent: Clinical Agent with Structured Reasoning and Tool-Integrated for Order Generation
May 31, 2026Clinical order generation serves as a critical bridge between clinical decision-making and real-world practice, translating medical decisions into concrete and executable orders. Existing agents mainly focus on coarse-grained decisions and overlook the fine-grained, executable information required for clinical orders. To address this gap, we propose CAREAgent, an agent for clinical order generation. To support its training, we introduce a two-stage agentic reasoning data construction method. First, we design an agent framework that constructs verifiable reasoning trajectories aligned with realistic clinical tool usage. Second, we filter reasoning trajectories by format compliance, order validity, and clinical plausibility. Building on the constructed data, the model is first trained via supervised fine-tuning to acquire fundamental reasoning formats and medical knowledge, and is subsequently optimized through reinforcement learning with multi-dimensional reward functions to enhance complex clinical reasoning capabilities. Experiments on multiple benchmarks demonstrate the effectiveness of CAREAgent. On ClinicalBench (unseen during training), CAREAgent improves the F1 score by 5.05%, 2.09%, and 0.86% over the single-agent, multi-agent, and agentic reasoning methods, respectively.
CRAFT: Time Series Forecasting with Cross-Future Behavior Awareness
May 20, 2025The past decades witness the significant advancements in time series forecasting (TSF) across various real-world domains, including e-commerce and disease spread prediction. However, TSF is usually constrained by the uncertainty dilemma of predicting future data with limited past observations. To settle this question, we explore the use of Cross-Future Behavior (CFB) in TSF, which occurs before the current time but takes effect in the future. We leverage CFB features and propose the CRoss-Future Behavior Awareness based Time Series Forecasting method (CRAFT). The core idea of CRAFT is to utilize the trend of cross-future behavior to mine the trend of time series data to be predicted. Specifically, to settle the sparse and partial flaws of cross-future behavior, CRAFT employs the Koopman Predictor Module to extract the key trend and the Internal Trend Mining Module to supplement the unknown area of the cross-future behavior matrix. Then, we introduce the External Trend Guide Module with a hierarchical structure to acquire more representative trends from higher levels. Finally, we apply the demand-constrained loss to calibrate the distribution deviation of prediction results. We conduct experiments on real-world dataset. Experiments on both offline large-scale dataset and online A/B test demonstrate the effectiveness of CRAFT. Our dataset and code is available at https://github.com/CRAFTinTSF/CRAFT.
How many preprints have actually been printed and why: a case study of computer science preprints on arXiv
Aug 03, 2023Preprints play an increasingly critical role in academic communities. There are many reasons driving researchers to post their manuscripts to preprint servers before formal submission to journals or conferences, but the use of preprints has also sparked considerable controversy, especially surrounding the claim of priority. In this paper, a case study of computer science preprints submitted to arXiv from 2008 to 2017 is conducted to quantify how many preprints have eventually been printed in peer-reviewed venues. Among those published manuscripts, some are published under different titles and without an update to their preprints on arXiv. In the case of these manuscripts, the traditional fuzzy matching method is incapable of mapping the preprint to the final published version. In view of this issue, we introduce a semantics-based mapping method with the employment of Bidirectional Encoder Representations from Transformers (BERT). With this new mapping method and a plurality of data sources, we find that 66% of all sampled preprints are published under unchanged titles and 11% are published under different titles and with other modifications. A further analysis was then performed to investigate why these preprints but not others were accepted for publication. Our comparison reveals that in the field of computer science, published preprints feature adequate revisions, multiple authorship, detailed abstract and introduction, extensive and authoritative references and available source code.
* Please cite the version of Scientometrics
Detecting and analyzing missing citations to published scientific entities
Oct 18, 2022Proper citation is of great importance in academic writing for it enables knowledge accumulation and maintains academic integrity. However, citing properly is not an easy task. For published scientific entities, the ever-growing academic publications and over-familiarity of terms easily lead to missing citations. To deal with this situation, we design a special method Citation Recommendation for Published Scientific Entity (CRPSE) based on the cooccurrences between published scientific entities and in-text citations in the same sentences from previous researchers. Experimental outcomes show the effectiveness of our method in recommending the source papers for published scientific entities. We further conduct a statistical analysis on missing citations among papers published in prestigious computer science conferences in 2020. In the 12,278 papers collected, 475 published scientific entities of computer science and mathematics are found to have missing citations. Many entities mentioned without citations are found to be well-accepted research results. On a median basis, the papers proposing these published scientific entities with missing citations were published 8 years ago, which can be considered the time frame for a published scientific entity to develop into a well-accepted concept. For published scientific entities, we appeal for accurate and full citation of their source papers as required by academic standards.
* Please cite the version of Scientometrics
Automatic Analysis of Available Source Code of Top Artificial Intelligence Conference Papers
Sep 28, 2022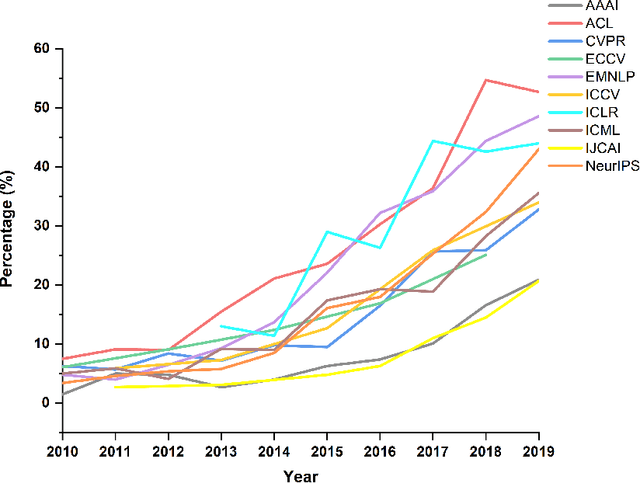
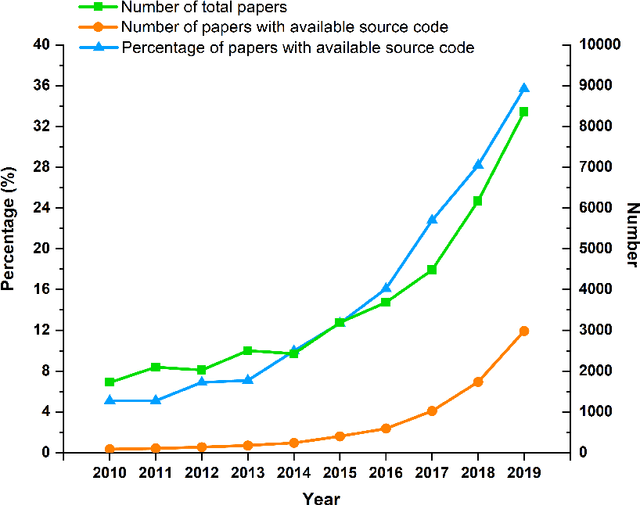


Source code is essential for researchers to reproduce the methods and replicate the results of artificial intelligence (AI) papers. Some organizations and researchers manually collect AI papers with available source code to contribute to the AI community. However, manual collection is a labor-intensive and time-consuming task. To address this issue, we propose a method to automatically identify papers with available source code and extract their source code repository URLs. With this method, we find that 20.5% of regular papers of 10 top AI conferences published from 2010 to 2019 are identified as papers with available source code and that 8.1% of these source code repositories are no longer accessible. We also create the XMU NLP Lab README Dataset, the largest dataset of labeled README files for source code document research. Through this dataset, we have discovered that quite a few README files have no installation instructions or usage tutorials provided. Further, a large-scale comprehensive statistical analysis is made for a general picture of the source code of AI conference papers. The proposed solution can also go beyond AI conference papers to analyze other scientific papers from both journals and conferences to shed light on more domains.
* Please cite the version of IJSEKE
Modeling Price Elasticity for Occupancy Prediction in Hotel Dynamic Pricing
Aug 11, 2022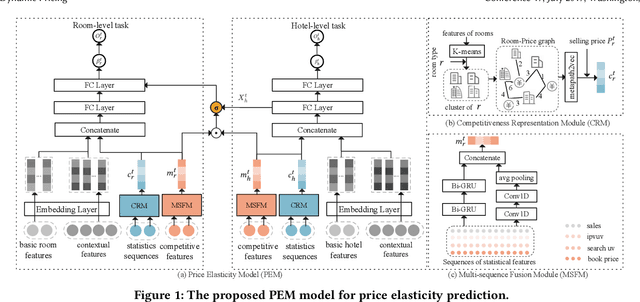
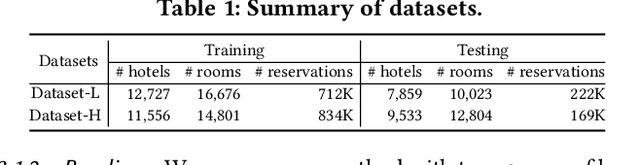
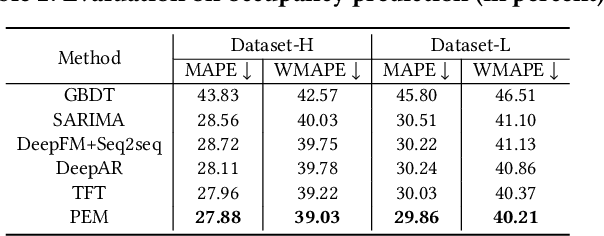

Demand estimation plays an important role in dynamic pricing where the optimal price can be obtained via maximizing the revenue based on the demand curve. In online hotel booking platform, the demand or occupancy of rooms varies across room-types and changes over time, and thus it is challenging to get an accurate occupancy estimate. In this paper, we propose a novel hotel demand function that explicitly models the price elasticity of demand for occupancy prediction, and design a price elasticity prediction model to learn the dynamic price elasticity coefficient from a variety of affecting factors. Our model is composed of carefully designed elasticity learning modules to alleviate the endogeneity problem, and trained in a multi-task framework to tackle the data sparseness. We conduct comprehensive experiments on real-world datasets and validate the superiority of our method over the state-of-the-art baselines for both occupancy prediction and dynamic pricing.
Itinerary-aware Personalized Deep Matching at Fliggy
Aug 05, 2021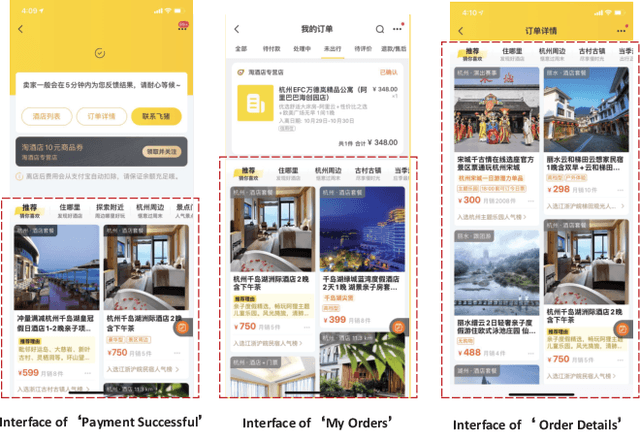
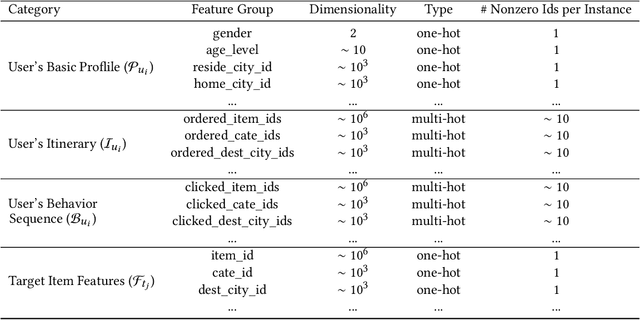
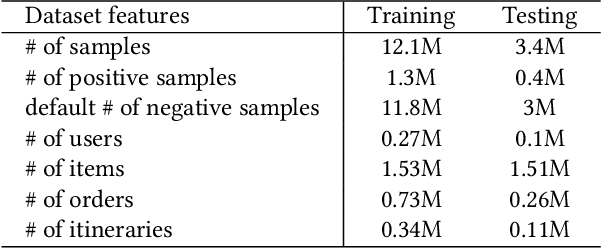
Matching items for a user from a travel item pool of large cardinality have been the most important technology for increasing the business at Fliggy, one of the most popular online travel platforms (OTPs) in China. There are three major challenges facing OTPs: sparsity, diversity, and implicitness. In this paper, we present a novel Fliggy ITinerary-aware deep matching NETwork (FitNET) to address these three challenges. FitNET is designed based on the popular deep matching network, which has been successfully employed in many industrial recommendation systems, due to its effectiveness. The concept itinerary is firstly proposed under the context of recommendation systems for OTPs, which is defined as the list of unconsumed orders of a user. All orders in a user itinerary are learned as a whole, based on which the implicit travel intention of each user can be more accurately inferred. To alleviate the sparsity problem, users' profiles are incorporated into FitNET. Meanwhile, a series of itinerary-aware attention mechanisms that capture the vital interactions between user's itinerary and other input categories are carefully designed. These mechanisms are very helpful in inferring a user's travel intention or preference, and handling the diversity in a user's need. Further, two training objectives, i.e., prediction accuracy of user's travel intention and prediction accuracy of user's click behavior, are utilized by FitNET, so that these two objectives can be optimized simultaneously. An offline experiment on Fliggy production dataset with over 0.27 million users and 1.55 million travel items, and an online A/B test both show that FitNET effectively learns users' travel intentions, preferences, and diverse needs, based on their itineraries and gains superior performance compared with state-of-the-art methods. FitNET now has been successfully deployed at Fliggy, serving major online traffic.