 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailBound: Jailbreaking Internal Safety Boundaries of Vision-Language Models
May 26, 2025Vision-Language Models (VLMs) exhibit impressive performance, yet the integration of powerful vision encoders has significantly broadened their attack surface, rendering them increasingly susceptible to jailbreak attacks. However, lacking well-defined attack objectives, existing jailbreak methods often struggle with gradient-based strategies prone to local optima and lacking precise directional guidance, and typically decouple visual and textual modalities, thereby limiting their effectiveness by neglecting crucial cross-modal interactions. Inspired by the Eliciting Latent Knowledge (ELK) framework, we posit that VLMs encode safety-relevant information within their internal fusion-layer representations, revealing an implicit safety decision boundary in the latent space. This motivates exploiting boundary to steer model behavior. Accordingly, we propose JailBound, a novel latent space jailbreak framework comprising two stages: (1) Safety Boundary Probing, which addresses the guidance issue by approximating decision boundary within fusion layer's latent space, thereby identifying optimal perturbation directions towards the target region; and (2) Safety Boundary Crossing, which overcomes the limitations of decoupled approaches by jointly optimizing adversarial perturbations across both image and text inputs. This latter stage employs an innovative mechanism to steer the model's internal state towards policy-violating outputs while maintaining cross-modal semantic consistency. Extensive experiments on six diverse VLMs demonstrate JailBound's efficacy, achieves 94.32% white-box and 67.28% black-box attack success averagely, which are 6.17% and 21.13% higher than SOTA methods, respectively. Our findings expose a overlooked safety risk in VLMs and highlight the urgent need for more robust defenses. Warning: This paper contains potentially sensitive, harmful and offensive content.
SafeVid: Toward Safety Aligned Video Large Multimodal Models
May 17, 2025As Video Large Multimodal Models (VLMMs) rapidly advance, their inherent complexity introduces significant safety challenges, particularly the issue of mismatched generalization where static safety alignments fail to transfer to dynamic video contexts. We introduce SafeVid, a framework designed to instill video-specific safety principles in VLMMs. SafeVid uniquely transfers robust textual safety alignment capabilities to the video domain by employing detailed textual video descriptions as an interpretive bridge, facilitating LLM-based rule-driven safety reasoning. This is achieved through a closed-loop system comprising: 1) generation of SafeVid-350K, a novel 350,000-pair video-specific safety preference dataset; 2) targeted alignment of VLMMs using Direct Preference Optimization (DPO); and 3) comprehensive evaluation via our new SafeVidBench benchmark. Alignment with SafeVid-350K significantly enhances VLMM safety, with models like LLaVA-NeXT-Video demonstrating substantial improvements (e.g., up to 42.39%) on SafeVidBench. SafeVid provides critical resources and a structured approach, demonstrating that leveraging textual descriptions as a conduit for safety reasoning markedly improves the safety alignment of VLMMs. We have made SafeVid-350K dataset (https://huggingface.co/datasets/yxwang/SafeVid-350K) publicly available.
U-GIFT: Uncertainty-Guided Firewall for Toxic Speech in Few-Shot Scenario
Jan 01, 2025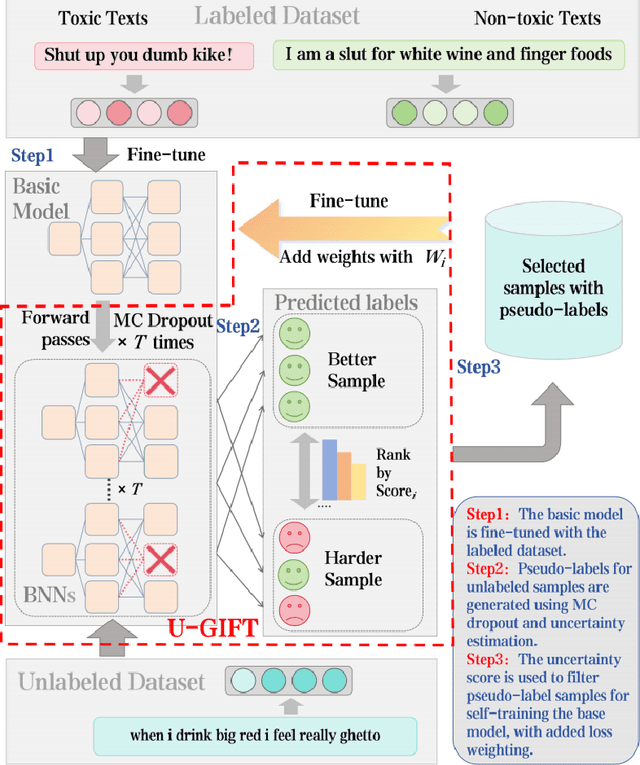
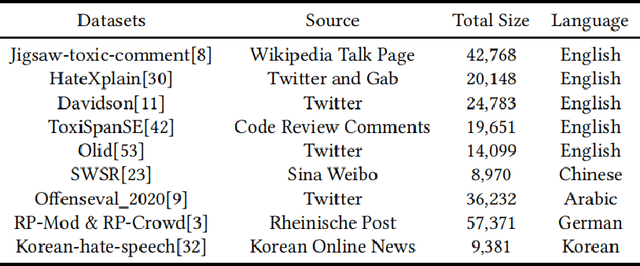
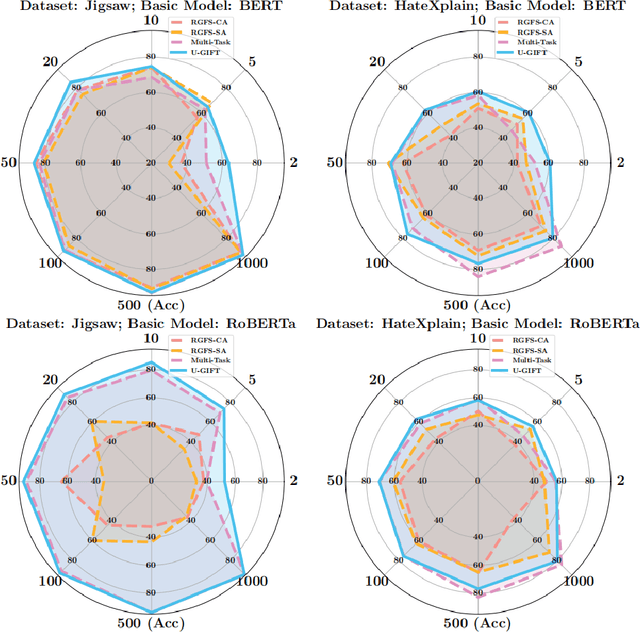
With the widespread use of social media, user-generated content has surged on online platforms. When such content includes hateful, abusive, offensive, or cyberbullying behavior, it is classified as toxic speech, posing a significant threat to the online ecosystem's integrity and safety. While manual content moderation is still prevalent, the overwhelming volume of content and the psychological strain on human moderators underscore the need for automated toxic speech detection. Previously proposed detection methods often rely on large annotated datasets; however, acquiring such datasets is both costly and challenging in practice. To address this issue, we propose an uncertainty-guided firewall for toxic speech in few-shot scenarios, U-GIFT, that utilizes self-training to enhance detection performance even when labeled data is limited. Specifically, U-GIFT combines active learning with Bayesian Neural Networks (BNNs) to automatically identify high-quality samples from unlabeled data, prioritizing the selection of pseudo-labels with higher confidence for training based on uncertainty estimates derived from model predictions. Extensive experiments demonstrate that U-GIFT significantly outperforms competitive baselines in few-shot detection scenarios. In the 5-shot setting, it achieves a 14.92\% performance improvement over the basic model. Importantly, U-GIFT is user-friendly and adaptable to various pre-trained language models (PLMs). It also exhibits robust performance in scenarios with sample imbalance and cross-domain settings, while showcasing strong generalization across various language applications. We believe that U-GIFT provides an efficient solution for few-shot toxic speech detection, offering substantial support for automated content moderation in cyberspace, thereby acting as a firewall to promote advancements in cybersecurity.
EFX Allocations Exist for Binary Valuations
Aug 10, 2023We study the fair division problem and the existence of allocations satisfying the fairness criterion envy-freeness up to any item (EFX). The existence of EFX allocations is a major open problem in the fair division literature. We consider binary valuations where the marginal gain of the value by receiving an extra item is either $0$ or $1$. Babaioff et al. [2021] proved that EFX allocations always exist for binary and submodular valuations. In this paper, by using completely different techniques, we extend this existence result to general binary valuations that are not necessarily submodular, and we present a polynomial time algorithm for computing an EFX allocation.
MOPRD: A multidisciplinary open peer review dataset
Dec 09, 2022Open peer review is a growing trend in academic publications. Public access to peer review data can benefit both the academic and publishing communities. It also serves as a great support to studies on review comment generation and further to the realization of automated scholarly paper review. However, most of the existing peer review datasets do not provide data that cover the whole peer review process. Apart from this, their data are not diversified enough as they are mainly collected from the field of computer science. These two drawbacks of the currently available peer review datasets need to be addressed to unlock more opportunities for related studies. In response to this problem, we construct MOPRD, a multidisciplinary open peer review dataset. This dataset consists of paper metadata, multiple version manuscripts, review comments, meta-reviews, author's rebuttal letters, and editorial decisions. Moreover, we design a modular guided review comment generation method based on MOPRD. Experiments show that our method delivers better performance indicated by both automatic metrics and human evaluation. We also explore other potential applications of MOPRD, including meta-review generation, editorial decision prediction, author rebuttal generation, and scientometric analysis. MOPRD is a strong endorsement for further studies in peer review-related research and other applications.
Detecting and analyzing missing citations to published scientific entities
Oct 18, 2022Proper citation is of great importance in academic writing for it enables knowledge accumulation and maintains academic integrity. However, citing properly is not an easy task. For published scientific entities, the ever-growing academic publications and over-familiarity of terms easily lead to missing citations. To deal with this situation, we design a special method Citation Recommendation for Published Scientific Entity (CRPSE) based on the cooccurrences between published scientific entities and in-text citations in the same sentences from previous researchers. Experimental outcomes show the effectiveness of our method in recommending the source papers for published scientific entities. We further conduct a statistical analysis on missing citations among papers published in prestigious computer science conferences in 2020. In the 12,278 papers collected, 475 published scientific entities of computer science and mathematics are found to have missing citations. Many entities mentioned without citations are found to be well-accepted research results. On a median basis, the papers proposing these published scientific entities with missing citations were published 8 years ago, which can be considered the time frame for a published scientific entity to develop into a well-accepted concept. For published scientific entities, we appeal for accurate and full citation of their source papers as required by academic standards.
* Please cite the version of Scientometrics
Automated scholarly paper review: Possibility and challenges
Nov 15, 2021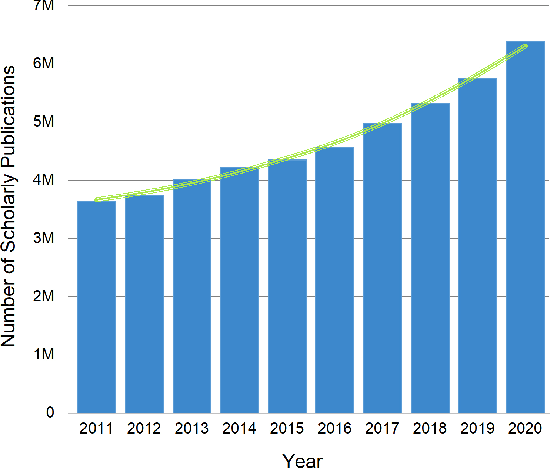
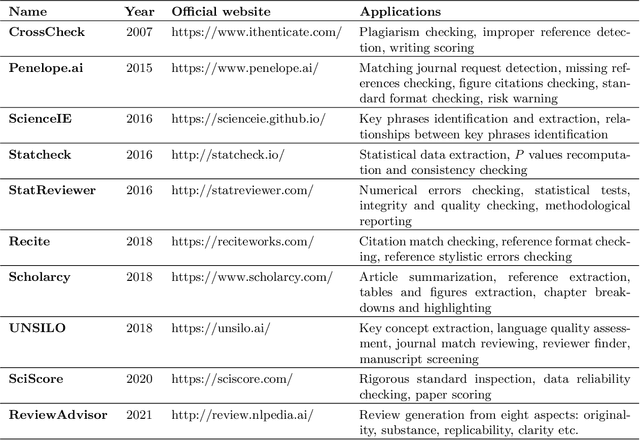
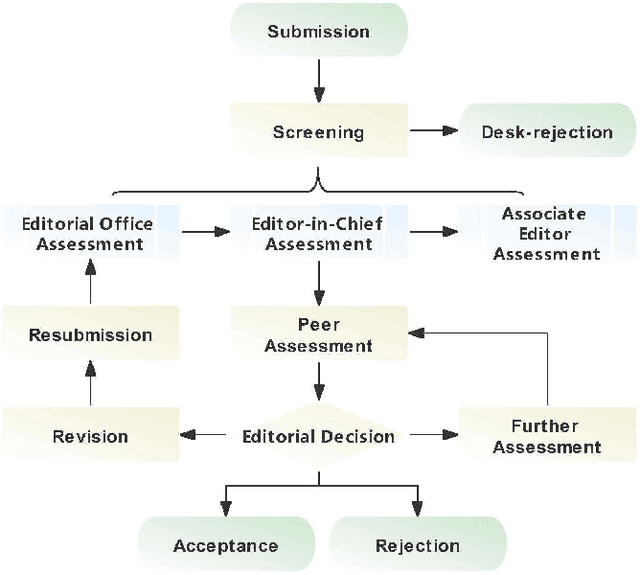

Peer review is a widely accepted mechanism for research evaluation, playing a pivotal role in scholarly publishing. However, criticisms have long been leveled on this mechanism, mostly because of its inefficiency and subjectivity. Recent years have seen the application of artificial intelligence (AI) in assisting the peer review process. Nonetheless, with the involvement of humans, such limitations remain inevitable. In this review paper, we propose the concept of automated scholarly paper review (ASPR) and review the relevant literature and technologies to discuss the possibility of achieving a full-scale computerized review process. We further look into the challenges in ASPR with the existing technologies. On the basis of the review and discussion, we conclude that there are already corresponding research and technologies at each stage of ASPR. This verifies that ASPR can be realized in the long term as the relevant technologies continue to develop. The major difficulties in its realization lie in imperfect document parsing and representation, inadequate data, defected human-computer interaction and flawed deep logical reasoning. In the foreseeable future, ASPR and peer review will coexist in a reinforcing manner before ASPR is able to fully undertake the reviewing workload from humans.