 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and mitigating the risks of OpenClaw for non-technical users: A practical guide with Skill
Jun 09, 2026OpenClaw has rapidly emerged as a transformative artificial intelligence (AI) agent framework, and its ability to autonomously execute complex, multi-step tasks has attracted an ever-growing and diverse user base. However, this capability comes with significant risks. While existing research has made important strides in characterizing these threats, such work is predominantly directed at technically sophisticated audiences. It remains largely inaccessible to non-technical users. This demographic now makes up an increasingly large and underserved portion of the community, yet it is these very users who most urgently need practical and straightforward guidance. In response, we bridge this gap through a series of interconnected efforts designed to lower the risk barrier for non-technical OpenClaw users. First, we identify and categorize seven core risks that OpenClaw users may encounter in daily usage, explaining each in plain language so that non-technical users can readily grasp the nature and potential consequences of these threats. Second, for each identified risk, we distill a set of corresponding defensive strategies into clear and actionable operational steps that are easy to follow. Third, to make protection even easier, we provide a companion OpenClaw Skill that automates key security configurations, enabling users to safeguard their systems with minimal manual intervention. Through this work, we demonstrate that safeguarding against the risks of intelligent agents need not be the exclusive domain of security experts, and that non-technical users can meaningfully participate in reducing these risks through simple, practical actions.
FMMD: A multimodal open peer review dataset based on F1000Research
Feb 15, 2026Automated scholarly paper review (ASPR) has entered the coexistence phase with traditional peer review, where artificial intelligence (AI) systems are increasingly incorporated into real-world manuscript evaluation. In parallel, research on automated and AI-assisted peer review has proliferated. Despite this momentum, empirical progress remains constrained by several critical limitations in existing datasets. While reviewers routinely evaluate figures, tables, and complex layouts to assess scientific claims, most existing datasets remain overwhelmingly text-centric. This bias is reinforced by a narrow focus on data from computer science venues. Furthermore, these datasets lack precise alignment between reviewer comments and specific manuscript versions, obscuring the iterative relationship between peer review and manuscript evolution. In response, we introduce FMMD, a multimodal and multidisciplinary open peer review dataset curated from F1000Research. The dataset bridges the current gap by integrating manuscript-level visual and structural data with version-specific reviewer reports and editorial decisions. By providing explicit alignment between reviewer comments and the exact article iteration under review, FMMD enables fine-grained analysis of the peer review lifecycle across diverse scientific domains. FMMD supports tasks such as multimodal issue detection and multimodal review comment generation. It provides a comprehensive empirical resource for the development of peer review research.
Large language models for automated scholarly paper review: A survey
Jan 17, 2025Large language models (LLMs) have significantly impacted human society, influencing various domains. Among them, academia is not simply a domain affected by LLMs, but it is also the pivotal force in the development of LLMs. In academic publications, this phenomenon is represented during the incorporation of LLMs into the peer review mechanism for reviewing manuscripts. We proposed the concept of automated scholarly paper review (ASPR) in our previous paper. As the incorporation grows, it now enters the coexistence phase of ASPR and peer review, which is described in that paper. LLMs hold transformative potential for the full-scale implementation of ASPR, but they also pose new issues and challenges that need to be addressed. In this survey paper, we aim to provide a holistic view of ASPR in the era of LLMs. We begin with a survey to find out which LLMs are used to conduct ASPR. Then, we review what ASPR-related technological bottlenecks have been solved with the incorporation of LLM technology. After that, we move on to explore new methods, new datasets, new source code, and new online systems that come with LLMs for ASPR. Furthermore, we summarize the performance and issues of LLMs in ASPR, and investigate the attitudes and reactions of publishers and academia to ASPR. Lastly, we discuss the challenges associated with the development of LLMs for ASPR. We hope this survey can serve as an inspirational reference for the researchers and promote the progress of ASPR for its actual implementation.
How many preprints have actually been printed and why: a case study of computer science preprints on arXiv
Aug 03, 2023Preprints play an increasingly critical role in academic communities. There are many reasons driving researchers to post their manuscripts to preprint servers before formal submission to journals or conferences, but the use of preprints has also sparked considerable controversy, especially surrounding the claim of priority. In this paper, a case study of computer science preprints submitted to arXiv from 2008 to 2017 is conducted to quantify how many preprints have eventually been printed in peer-reviewed venues. Among those published manuscripts, some are published under different titles and without an update to their preprints on arXiv. In the case of these manuscripts, the traditional fuzzy matching method is incapable of mapping the preprint to the final published version. In view of this issue, we introduce a semantics-based mapping method with the employment of Bidirectional Encoder Representations from Transformers (BERT). With this new mapping method and a plurality of data sources, we find that 66% of all sampled preprints are published under unchanged titles and 11% are published under different titles and with other modifications. A further analysis was then performed to investigate why these preprints but not others were accepted for publication. Our comparison reveals that in the field of computer science, published preprints feature adequate revisions, multiple authorship, detailed abstract and introduction, extensive and authoritative references and available source code.
* Please cite the version of Scientometrics
MOPRD: A multidisciplinary open peer review dataset
Dec 09, 2022Open peer review is a growing trend in academic publications. Public access to peer review data can benefit both the academic and publishing communities. It also serves as a great support to studies on review comment generation and further to the realization of automated scholarly paper review. However, most of the existing peer review datasets do not provide data that cover the whole peer review process. Apart from this, their data are not diversified enough as they are mainly collected from the field of computer science. These two drawbacks of the currently available peer review datasets need to be addressed to unlock more opportunities for related studies. In response to this problem, we construct MOPRD, a multidisciplinary open peer review dataset. This dataset consists of paper metadata, multiple version manuscripts, review comments, meta-reviews, author's rebuttal letters, and editorial decisions. Moreover, we design a modular guided review comment generation method based on MOPRD. Experiments show that our method delivers better performance indicated by both automatic metrics and human evaluation. We also explore other potential applications of MOPRD, including meta-review generation, editorial decision prediction, author rebuttal generation, and scientometric analysis. MOPRD is a strong endorsement for further studies in peer review-related research and other applications.
Detecting and analyzing missing citations to published scientific entities
Oct 18, 2022Proper citation is of great importance in academic writing for it enables knowledge accumulation and maintains academic integrity. However, citing properly is not an easy task. For published scientific entities, the ever-growing academic publications and over-familiarity of terms easily lead to missing citations. To deal with this situation, we design a special method Citation Recommendation for Published Scientific Entity (CRPSE) based on the cooccurrences between published scientific entities and in-text citations in the same sentences from previous researchers. Experimental outcomes show the effectiveness of our method in recommending the source papers for published scientific entities. We further conduct a statistical analysis on missing citations among papers published in prestigious computer science conferences in 2020. In the 12,278 papers collected, 475 published scientific entities of computer science and mathematics are found to have missing citations. Many entities mentioned without citations are found to be well-accepted research results. On a median basis, the papers proposing these published scientific entities with missing citations were published 8 years ago, which can be considered the time frame for a published scientific entity to develop into a well-accepted concept. For published scientific entities, we appeal for accurate and full citation of their source papers as required by academic standards.
* Please cite the version of Scientometrics
Automatic Analysis of Available Source Code of Top Artificial Intelligence Conference Papers
Sep 28, 2022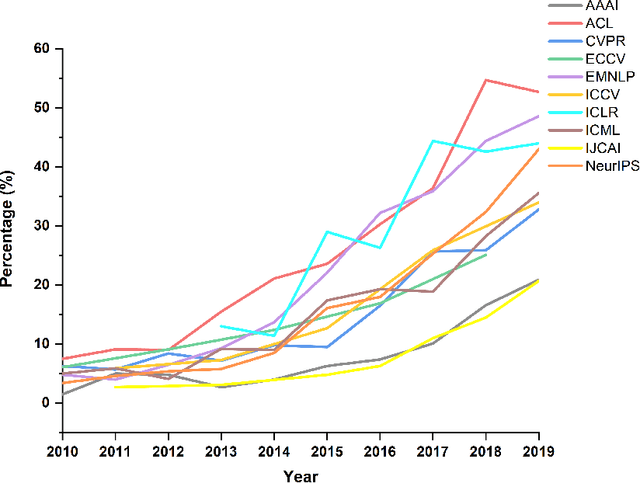
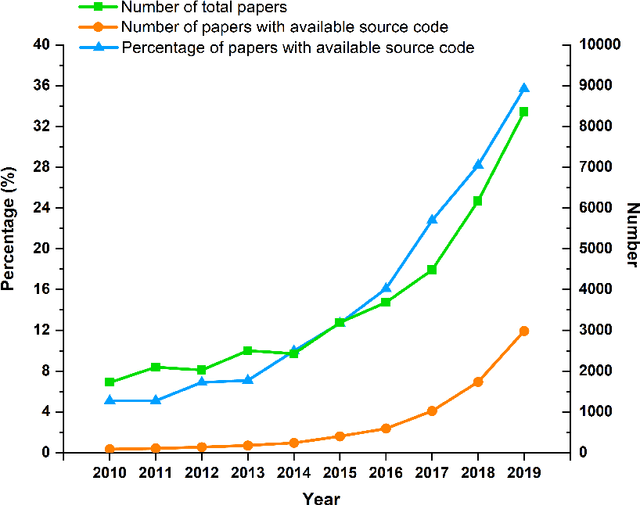


Source code is essential for researchers to reproduce the methods and replicate the results of artificial intelligence (AI) papers. Some organizations and researchers manually collect AI papers with available source code to contribute to the AI community. However, manual collection is a labor-intensive and time-consuming task. To address this issue, we propose a method to automatically identify papers with available source code and extract their source code repository URLs. With this method, we find that 20.5% of regular papers of 10 top AI conferences published from 2010 to 2019 are identified as papers with available source code and that 8.1% of these source code repositories are no longer accessible. We also create the XMU NLP Lab README Dataset, the largest dataset of labeled README files for source code document research. Through this dataset, we have discovered that quite a few README files have no installation instructions or usage tutorials provided. Further, a large-scale comprehensive statistical analysis is made for a general picture of the source code of AI conference papers. The proposed solution can also go beyond AI conference papers to analyze other scientific papers from both journals and conferences to shed light on more domains.
* Please cite the version of IJSEKE
Automated scholarly paper review: Possibility and challenges
Nov 15, 2021
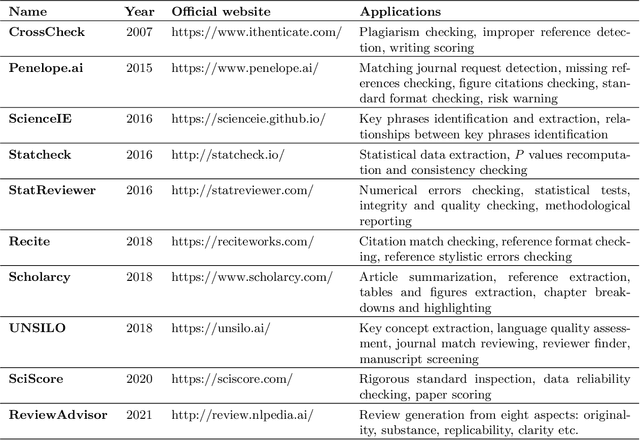
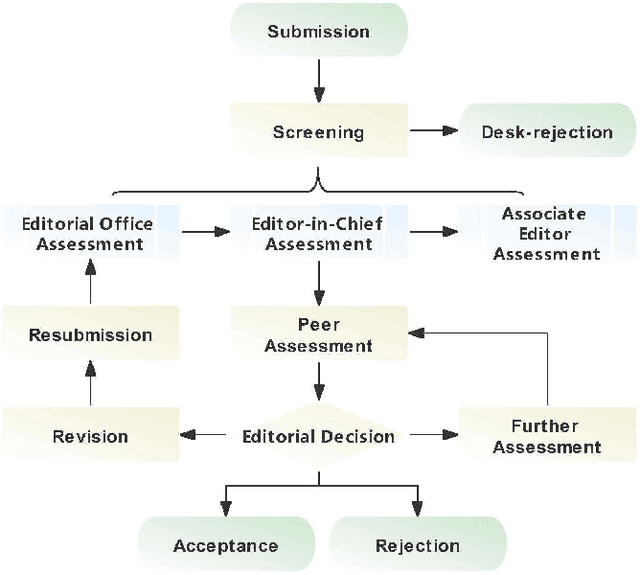

Peer review is a widely accepted mechanism for research evaluation, playing a pivotal role in scholarly publishing. However, criticisms have long been leveled on this mechanism, mostly because of its inefficiency and subjectivity. Recent years have seen the application of artificial intelligence (AI) in assisting the peer review process. Nonetheless, with the involvement of humans, such limitations remain inevitable. In this review paper, we propose the concept of automated scholarly paper review (ASPR) and review the relevant literature and technologies to discuss the possibility of achieving a full-scale computerized review process. We further look into the challenges in ASPR with the existing technologies. On the basis of the review and discussion, we conclude that there are already corresponding research and technologies at each stage of ASPR. This verifies that ASPR can be realized in the long term as the relevant technologies continue to develop. The major difficulties in its realization lie in imperfect document parsing and representation, inadequate data, defected human-computer interaction and flawed deep logical reasoning. In the foreseeable future, ASPR and peer review will coexist in a reinforcing manner before ASPR is able to fully undertake the reviewing workload from humans.