 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer learning for scalar-on-function regression via control variates
Jan 23, 2026Transfer learning (TL) has emerged as a powerful tool for improving estimation and prediction performance by leveraging information from related datasets. In this paper, we repurpose the control-variates (CVS) method for TL in the context of scalar-on-function regression. Our proposed framework relies exclusively on dataset-specific summary statistics, avoiding the need to pool subject-level data and thus remaining applicable in privacy-restricted or decentralized settings. We establish theoretical connections among several existing TL strategies and derive convergence rates for our CVS-based proposals. These rates explicitly account for the typically overlooked smoothing error and reveal how the similarity among covariance functions across datasets influences convergence behavior. Numerical studies support the theoretical findings and demonstrate that the proposed methods achieve competitive estimation and prediction performance compared with existing alternatives.
How many preprints have actually been printed and why: a case study of computer science preprints on arXiv
Aug 03, 2023Preprints play an increasingly critical role in academic communities. There are many reasons driving researchers to post their manuscripts to preprint servers before formal submission to journals or conferences, but the use of preprints has also sparked considerable controversy, especially surrounding the claim of priority. In this paper, a case study of computer science preprints submitted to arXiv from 2008 to 2017 is conducted to quantify how many preprints have eventually been printed in peer-reviewed venues. Among those published manuscripts, some are published under different titles and without an update to their preprints on arXiv. In the case of these manuscripts, the traditional fuzzy matching method is incapable of mapping the preprint to the final published version. In view of this issue, we introduce a semantics-based mapping method with the employment of Bidirectional Encoder Representations from Transformers (BERT). With this new mapping method and a plurality of data sources, we find that 66% of all sampled preprints are published under unchanged titles and 11% are published under different titles and with other modifications. A further analysis was then performed to investigate why these preprints but not others were accepted for publication. Our comparison reveals that in the field of computer science, published preprints feature adequate revisions, multiple authorship, detailed abstract and introduction, extensive and authoritative references and available source code.
* Please cite the version of Scientometrics
Empirical Quantitative Analysis of COVID-19 Forecasting Models
Oct 01, 2021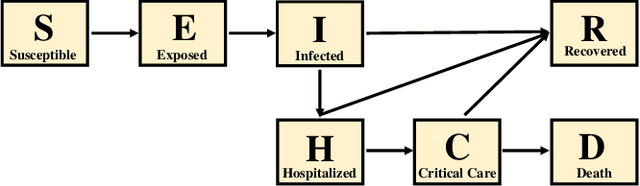
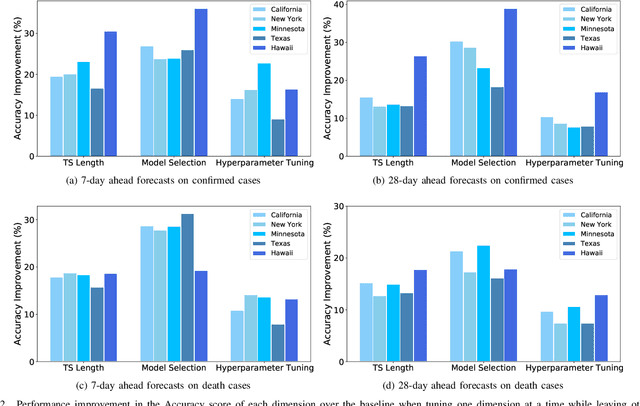
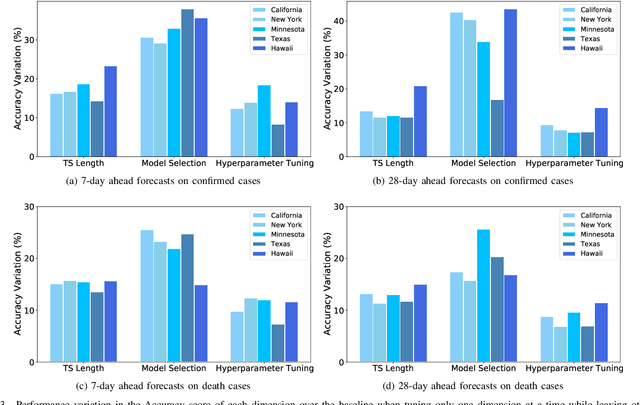
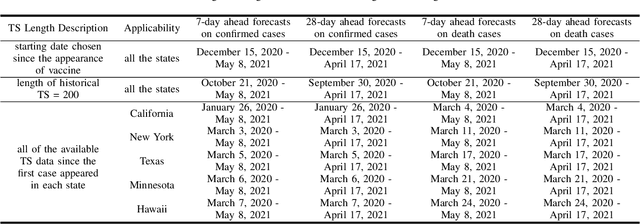
COVID-19 has been a public health emergency of international concern since early 2020. Reliable forecasting is critical to diminish the impact of this disease. To date, a large number of different forecasting models have been proposed, mainly including statistical models, compartmental models, and deep learning models. However, due to various uncertain factors across different regions such as economics and government policy, no forecasting model appears to be the best for all scenarios. In this paper, we perform quantitative analysis of COVID-19 forecasting of confirmed cases and deaths across different regions in the United States with different forecasting horizons, and evaluate the relative impacts of the following three dimensions on the predictive performance (improvement and variation) through different evaluation metrics: model selection, hyperparameter tuning, and the length of time series required for training. We find that if a dimension brings about higher performance gains, if not well-tuned, it may also lead to harsher performance penalties. Furthermore, model selection is the dominant factor in determining the predictive performance. It is responsible for both the largest improvement and the largest variation in performance in all prediction tasks across different regions. While practitioners may perform more complicated time series analysis in practice, they should be able to achieve reasonable results if they have adequate insight into key decisions like model selection.