 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenseJudge: Human-Centric Preference-Driven Judgment Framework
Jun 03, 2026Large Language Models (LLMs) as judges across various scenarios such as assessing model responses is becoming an increasingly accepted paradigm. However, existing judgment approaches often rely on trained judgers using fixed preference data, which tend to overlook diverse user preferences and struggle to adapt to real-world human-AI dialogue scenarios. To address these limitations, we propose SenseJudge, a customizable judgment framework driven by human preferences and SenseBench, a diverse and challenging instruction-following benchmark derived from real-world multi-turn interactions. We applied the automatic judgment framework and benchmark to two tasks: (1) LLMs as personalized judges, and (2) model ranking. We conducted extensive experiments, and the results demonstrate that the SenseJudge framework surpasses other judgment methods and models in the LLMs-as-personalized-judges task and achieves model ranking that aligns with real human sense. Additionally, we conducted analyses on position bias and consistency, alongside ablation studies, which affirmed the robustness of SenseJudge.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
HauntAttack: When Attack Follows Reasoning as a Shadow
Jun 08, 2025



Emerging Large Reasoning Models (LRMs) consistently excel in mathematical and reasoning tasks, showcasing exceptional capabilities. However, the enhancement of reasoning abilities and the exposure of their internal reasoning processes introduce new safety vulnerabilities. One intriguing concern is: when reasoning is strongly entangled with harmfulness, what safety-reasoning trade-off do LRMs exhibit? To address this issue, we introduce HauntAttack, a novel and general-purpose black-box attack framework that systematically embeds harmful instructions into reasoning questions. Specifically, we treat reasoning questions as carriers and substitute one of their original conditions with a harmful instruction. This process creates a reasoning pathway in which the model is guided step by step toward generating unsafe outputs. Based on HauntAttack, we conduct comprehensive experiments on multiple LRMs. Our results reveal that even the most advanced LRMs exhibit significant safety vulnerabilities. Additionally, we perform a detailed analysis of different models, various types of harmful instructions, and model output patterns, providing valuable insights into the security of LRMs.
CoMAC: Conversational Agent for Multi-Source Auxiliary Context with Sparse and Symmetric Latent Interactions
Mar 25, 2025Recent advancements in AI-driven conversational agents have exhibited immense potential of AI applications. Effective response generation is crucial to the success of these agents. While extensive research has focused on leveraging multiple auxiliary data sources (e.g., knowledge bases and personas) to enhance response generation, existing methods often struggle to efficiently extract relevant information from these sources. There are still clear limitations in the ability to combine versatile conversational capabilities with adherence to known facts and adaptation to large variations in user preferences and belief systems, which continues to hinder the wide adoption of conversational AI tools. This paper introduces a novel method, Conversational Agent for Multi-Source Auxiliary Context with Sparse and Symmetric Latent Interactions (CoMAC), for conversation generation, which employs specialized encoding streams and post-fusion grounding networks for multiple data sources to identify relevant persona and knowledge information for the conversation. CoMAC also leverages a novel text similarity metric that allows bi-directional information sharing among multiple sources and focuses on a selective subset of meaningful words. Our experiments show that CoMAC improves the relevant persona and knowledge prediction accuracies and response generation quality significantly over two state-of-the-art methods.
OpenLS-DGF: An Adaptive Open-Source Dataset Generation Framework for Machine Learning Tasks in Logic Synthesis
Nov 16, 2024



This paper introduces OpenLS-DGF, an adaptive logic synthesis dataset generation framework, to enhance machine learning~(ML) applications within the logic synthesis process. Previous dataset generation flows were tailored for specific tasks or lacked integrated machine learning capabilities. While OpenLS-DGF supports various machine learning tasks by encapsulating the three fundamental steps of logic synthesis: Boolean representation, logic optimization, and technology mapping. It preserves the original information in both Verilog and machine-learning-friendly GraphML formats. The verilog files offer semi-customizable capabilities, enabling researchers to insert additional steps and incrementally refine the generated dataset. Furthermore, OpenLS-DGF includes an adaptive circuit engine that facilitates the final dataset management and downstream tasks. The generated OpenLS-D-v1 dataset comprises 46 combinational designs from established benchmarks, totaling over 966,000 Boolean circuits. OpenLS-D-v1 supports integrating new data features, making it more versatile for new challenges. This paper demonstrates the versatility of OpenLS-D-v1 through four distinct downstream tasks: circuit classification, circuit ranking, quality of results (QoR) prediction, and probability prediction. Each task is chosen to represent essential steps of logic synthesis, and the experimental results show the generated dataset from OpenLS-DGF achieves prominent diversity and applicability. The source code and datasets are available at https://github.com/Logic-Factory/ACE/blob/master/OpenLS-DGF/readme.md.
An Adaptive Open-Source Dataset Generation Framework for Machine Learning Tasks in Logic Synthesis
Nov 14, 2024This paper introduces an adaptive logic synthesis dataset generation framework designed to enhance machine learning applications within the logic synthesis process. Unlike previous dataset generation flows that were tailored for specific tasks or lacked integrated machine learning capabilities, the proposed framework supports a comprehensive range of machine learning tasks by encapsulating the three fundamental steps of logic synthesis: Boolean representation, logic optimization, and technology mapping. It preserves the original information in the intermediate files that can be stored in both Verilog and Graphmal format. Verilog files enable semi-customizability, allowing researchers to add steps and incrementally refine the generated dataset. The framework also includes an adaptive circuit engine to facilitate the loading of GraphML files for final dataset packaging and sub-dataset extraction. The generated OpenLS-D dataset comprises 46 combinational designs from established benchmarks, totaling over 966,000 Boolean circuits, with each design containing 21,000 circuits generated from 1000 synthesis recipes, including 7000 Boolean networks, 7000 ASIC netlists, and 7000 FPGA netlists. Furthermore, OpenLS-D supports integrating newly desired data features, making it more versatile for new challenges. The utility of OpenLS-D is demonstrated through four distinct downstream tasks: circuit classification, circuit ranking, quality of results (QoR) prediction, and probability prediction. Each task highlights different internal steps of logic synthesis, with the datasets extracted and relabeled from the OpenLS-D dataset using the circuit engine. The experimental results confirm the dataset's diversity and extensive applicability. The source code and datasets are available at https://github.com/Logic-Factory/ACE/blob/master/OpenLS-D/readme.md.
Generalization Gap in Data Augmentation: Insights from Illumination
Apr 11, 2024In the field of computer vision, data augmentation is widely used to enrich the feature complexity of training datasets with deep learning techniques. However, regarding the generalization capabilities of models, the difference in artificial features generated by data augmentation and natural visual features has not been fully revealed. This study focuses on the visual representation variable 'illumination', by simulating its distribution degradation and examining how data augmentation techniques enhance model performance on a classification task. Our goal is to investigate the differences in generalization between models trained with augmented data and those trained under real-world illumination conditions. Results indicate that after undergoing various data augmentation methods, model performance has been significantly improved. Yet, a noticeable generalization gap still exists after utilizing various data augmentation methods, emphasizing the critical role of feature diversity in the training set for enhancing model generalization.
Word Order's Impacts: Insights from Reordering and Generation Analysis
Mar 18, 2024Existing works have studied the impacts of the order of words within natural text. They usually analyze it by destroying the original order of words to create a scrambled sequence, and then comparing the models' performance between the original and scrambled sequences. The experimental results demonstrate marginal drops. Considering this findings, different hypothesis about word order is proposed, including ``the order of words is redundant with lexical semantics'', and ``models do not rely on word order''. In this paper, we revisit the aforementioned hypotheses by adding a order reconstruction perspective, and selecting datasets of different spectrum. Specifically, we first select four different datasets, and then design order reconstruction and continuing generation tasks. Empirical findings support that ChatGPT relies on word order to infer, but cannot support or negate the redundancy relations between word order lexical semantics.
Adaptive Reconvergence-driven AIG Rewriting via Strategy Learning
Dec 22, 2023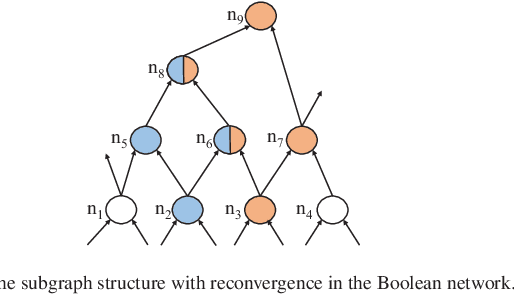
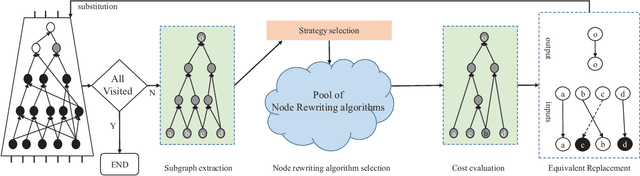
Rewriting is a common procedure in logic synthesis aimed at improving the performance, power, and area (PPA) of circuits. The traditional reconvergence-driven And-Inverter Graph (AIG) rewriting method focuses solely on optimizing the reconvergence cone through Boolean algebra minimization. However, there exist opportunities to incorporate other node-rewriting algorithms that are better suited for specific cones. In this paper, we propose an adaptive reconvergence-driven AIG rewriting algorithm that combines two key techniques: multi-strategy-based AIG rewriting and strategy learning-based algorithm selection. The multi-strategy-based rewriting method expands upon the traditional approach by incorporating support for multi-node-rewriting algorithms, thus expanding the optimization space. Additionally, the strategy learning-based algorithm selection method determines the most suitable node-rewriting algorithm for a given cone. Experimental results demonstrate that our proposed method yields a significant average improvement of 5.567\% in size and 5.327\% in depth.