 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2D or 3D: Who Governs Salience in VLA Models? -- Tri-Stage Token Pruning Framework with Modality Salience Awareness
Apr 10, 2026Vision-Language-Action (VLA) models have emerged as the mainstream of embodied intelligence. Recent VLA models have expanded their input modalities from 2D-only to 2D+3D paradigms, forming multi-visual-modal VLA (MVLA) models. Despite achieving improved spatial perception, MVLA faces a greater acceleration demand due to the increased number of input tokens caused by modal expansion. Token pruning is an effective optimization methods tailored to MVLA models. However, existing token pruning schemes are designed for 2D-only VLA models, ignoring 2D/3D modality salience differences. In this paper, we follow the application process of multi-modal data in MVLA models and develop a tri-stage analysis to capture the discrepancy and dynamics of 2D/3D modality salience. Based on these, we propose a corresponding tri-stage token pruning framework for MVLA models to achieve optimal 2D/3D token selection and efficient pruning. Experiments show that our framework achieves up to a 2.55x inference speedup with minimal accuracy loss, while only costing 5.8% overhead. Our Code is coming soon.
RoboECC: Multi-Factor-Aware Edge-Cloud Collaborative Deployment for VLA Models
Mar 21, 2026Vision-Language-Action (VLA) models are mainstream in embodied intelligence but face high inference costs. Edge-Cloud Collaborative (ECC) deployment offers an effective fix by easing edge-device computing pressure to meet real-time needs. However, existing ECC frameworks are suboptimal for VLA models due to two challenges: (1) Diverse model structures hinder optimal ECC segmentation point identification; (2) Even if the optimal split point is determined, changes in network bandwidth can cause performance drift. To address these issues, we propose a novel ECC deployment framework for various VLA models, termed RoboECC. Specifically, we propose a model-hardware co-aware segmentation strategy to help find the optimal segmentation point for various VLA models. Moreover, we propose a network-aware deployment adjustment approach to adapt to the network fluctuations for maintaining optimal performance. Experiments demonstrate that RoboECC achieves a speedup of up to 3.28x with only 2.55x~2.62x overhead.
RAPID: Redundancy-Aware and Compatibility-Optimal Edge-Cloud Partitioned Inference for Diverse VLA Models
Mar 12, 2026Vision Language Action (VLA) models are mainstream in embodied intelligence but face high inference costs. Edge-Cloud Collaborative (ECC) inference offers an effective fix by easing edge-device computing pressure to meet real-time needs. However, existing ECC frameworks are suboptimal for VLA models due to two challenges: (1) Mainstream environment-oriented edge-cloud partitioning methods are susceptible to interference from visual noise; (2) Existing edge-cloud partitioning methods overlook the step-wise redundancy unique to embodied tasks, thereby disrupting the physical continuity of motion. To address these issues, we propose a novel ECC inference framework, termed RAPID. Specifically, we developed an implementation tailored to the proposed framework. Experiments demonstrate this achieves a speedup of up to 1.73x with only 5%~7% overhead.
ToProVAR: Efficient Visual Autoregressive Modeling via Tri-Dimensional Entropy-Aware Semantic Analysis and Sparsity Optimization
Feb 26, 2026Visual Autoregressive(VAR) models enhance generation quality but face a critical efficiency bottleneck in later stages. In this paper, we present a novel optimization framework for VAR models that fundamentally differs from prior approaches such as FastVAR and SkipVAR. Instead of relying on heuristic skipping strategies, our method leverages attention entropy to characterize the semantic projections across different dimensions of the model architecture. This enables precise identification of parameter dynamics under varying token granularity levels, semantic scopes, and generation scales. Building on this analysis, we further uncover sparsity patterns along three critical dimensions-token, layer, and scale-and propose a set of fine-grained optimization strategies tailored to these patterns. Extensive evaluation demonstrates that our approach achieves aggressive acceleration of the generation process while significantly preserving semantic fidelity and fine details, outperforming traditional methods in both efficiency and quality. Experiments on Infinity-2B and Infinity-8B models demonstrate that ToProVAR achieves up to 3.4x acceleration with minimal quality loss, effectively mitigating the issues found in prior work. Our code will be made publicly available.
DynamicRTL: RTL Representation Learning for Dynamic Circuit Behavior
Nov 12, 2025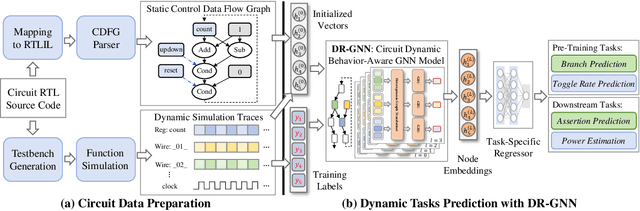

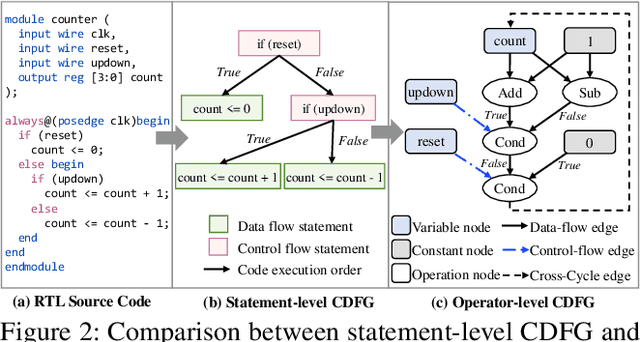

There is a growing body of work on using Graph Neural Networks (GNNs) to learn representations of circuits, focusing primarily on their static characteristics. However, these models fail to capture circuit runtime behavior, which is crucial for tasks like circuit verification and optimization. To address this limitation, we introduce DR-GNN (DynamicRTL-GNN), a novel approach that learns RTL circuit representations by incorporating both static structures and multi-cycle execution behaviors. DR-GNN leverages an operator-level Control Data Flow Graph (CDFG) to represent Register Transfer Level (RTL) circuits, enabling the model to capture dynamic dependencies and runtime execution. To train and evaluate DR-GNN, we build the first comprehensive dynamic circuit dataset, comprising over 6,300 Verilog designs and 63,000 simulation traces. Our results demonstrate that DR-GNN outperforms existing models in branch hit prediction and toggle rate prediction. Furthermore, its learned representations transfer effectively to related dynamic circuit tasks, achieving strong performance in power estimation and assertion prediction.
OpenLS-DGF: An Adaptive Open-Source Dataset Generation Framework for Machine Learning Tasks in Logic Synthesis
Nov 16, 2024



This paper introduces OpenLS-DGF, an adaptive logic synthesis dataset generation framework, to enhance machine learning~(ML) applications within the logic synthesis process. Previous dataset generation flows were tailored for specific tasks or lacked integrated machine learning capabilities. While OpenLS-DGF supports various machine learning tasks by encapsulating the three fundamental steps of logic synthesis: Boolean representation, logic optimization, and technology mapping. It preserves the original information in both Verilog and machine-learning-friendly GraphML formats. The verilog files offer semi-customizable capabilities, enabling researchers to insert additional steps and incrementally refine the generated dataset. Furthermore, OpenLS-DGF includes an adaptive circuit engine that facilitates the final dataset management and downstream tasks. The generated OpenLS-D-v1 dataset comprises 46 combinational designs from established benchmarks, totaling over 966,000 Boolean circuits. OpenLS-D-v1 supports integrating new data features, making it more versatile for new challenges. This paper demonstrates the versatility of OpenLS-D-v1 through four distinct downstream tasks: circuit classification, circuit ranking, quality of results (QoR) prediction, and probability prediction. Each task is chosen to represent essential steps of logic synthesis, and the experimental results show the generated dataset from OpenLS-DGF achieves prominent diversity and applicability. The source code and datasets are available at https://github.com/Logic-Factory/ACE/blob/master/OpenLS-DGF/readme.md.
An Adaptive Open-Source Dataset Generation Framework for Machine Learning Tasks in Logic Synthesis
Nov 14, 2024This paper introduces an adaptive logic synthesis dataset generation framework designed to enhance machine learning applications within the logic synthesis process. Unlike previous dataset generation flows that were tailored for specific tasks or lacked integrated machine learning capabilities, the proposed framework supports a comprehensive range of machine learning tasks by encapsulating the three fundamental steps of logic synthesis: Boolean representation, logic optimization, and technology mapping. It preserves the original information in the intermediate files that can be stored in both Verilog and Graphmal format. Verilog files enable semi-customizability, allowing researchers to add steps and incrementally refine the generated dataset. The framework also includes an adaptive circuit engine to facilitate the loading of GraphML files for final dataset packaging and sub-dataset extraction. The generated OpenLS-D dataset comprises 46 combinational designs from established benchmarks, totaling over 966,000 Boolean circuits, with each design containing 21,000 circuits generated from 1000 synthesis recipes, including 7000 Boolean networks, 7000 ASIC netlists, and 7000 FPGA netlists. Furthermore, OpenLS-D supports integrating newly desired data features, making it more versatile for new challenges. The utility of OpenLS-D is demonstrated through four distinct downstream tasks: circuit classification, circuit ranking, quality of results (QoR) prediction, and probability prediction. Each task highlights different internal steps of logic synthesis, with the datasets extracted and relabeled from the OpenLS-D dataset using the circuit engine. The experimental results confirm the dataset's diversity and extensive applicability. The source code and datasets are available at https://github.com/Logic-Factory/ACE/blob/master/OpenLS-D/readme.md.
VerilogReader: LLM-Aided Hardware Test Generation
Jun 03, 2024Test generation has been a critical and labor-intensive process in hardware design verification. Recently, the emergence of Large Language Model (LLM) with their advanced understanding and inference capabilities, has introduced a novel approach. In this work, we investigate the integration of LLM into the Coverage Directed Test Generation (CDG) process, where the LLM functions as a Verilog Reader. It accurately grasps the code logic, thereby generating stimuli that can reach unexplored code branches. We compare our framework with random testing, using our self-designed Verilog benchmark suite. Experiments demonstrate that our framework outperforms random testing on designs within the LLM's comprehension scope. Our work also proposes prompt engineering optimizations to augment LLM's understanding scope and accuracy.
Fast Exact NPN Classification with Influence-aided Canonical Form
Aug 23, 2023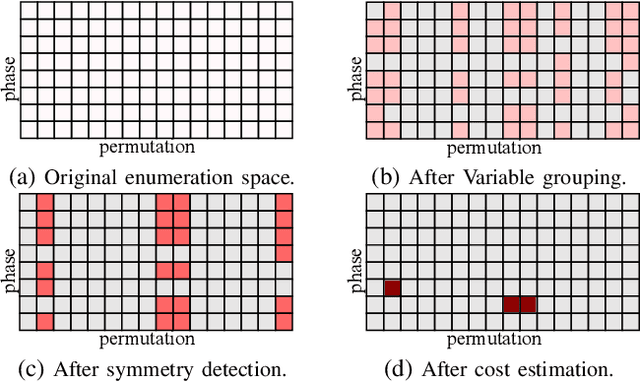
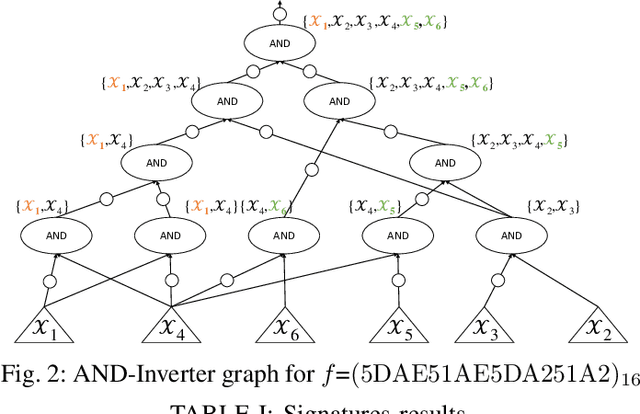
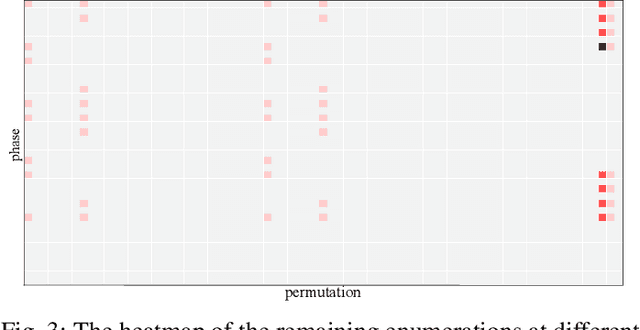
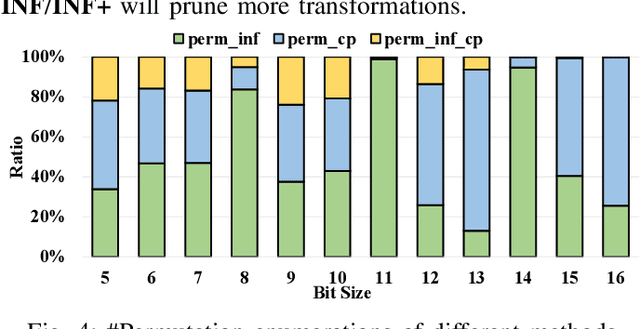
NPN classification has many applications in the synthesis and verification of digital circuits. The canonical-form-based method is the most common approach, designing a canonical form as representative for the NPN equivalence class first and then computing the transformation function according to the canonical form. Most works use variable symmetries and several signatures, mainly based on the cofactor, to simplify the canonical form construction and computation. This paper describes a novel canonical form and its computation algorithm by introducing Boolean influence to NPN classification, which is a basic concept in analysis of Boolean functions. We show that influence is input-negation-independent, input-permutation-dependent, and has other structural information than previous signatures for NPN classification. Therefore, it is a significant ingredient in speeding up NPN classification. Experimental results prove that influence plays an important role in reducing the transformation enumeration in computing the canonical form. Compared with the state-of-the-art algorithm implemented in ABC, our influence-aided canonical form for exact NPN classification gains up to 5.5x speedup.
Enhanced Fast Boolean Matching based on Sensitivity Signatures Pruning
Nov 11, 2021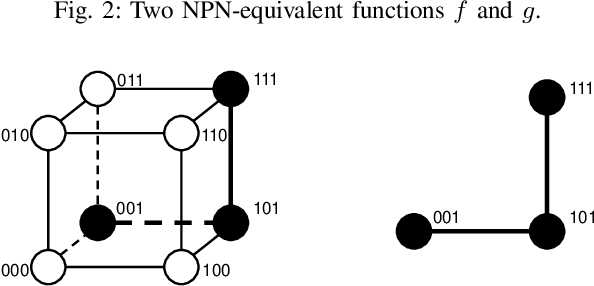
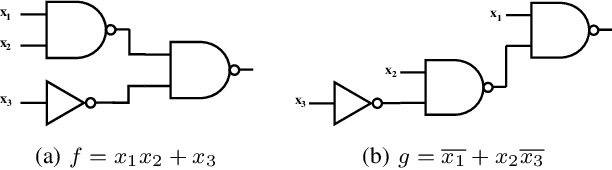
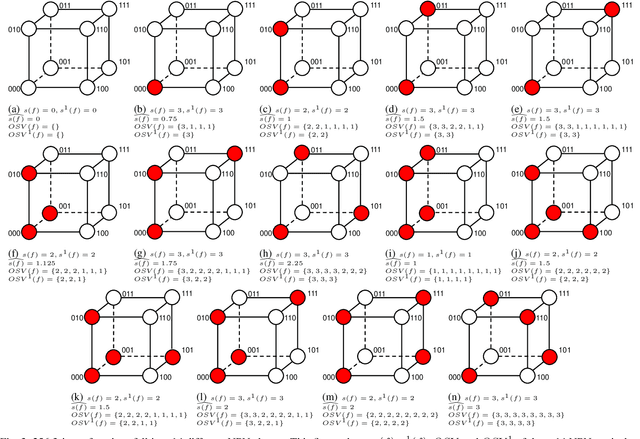
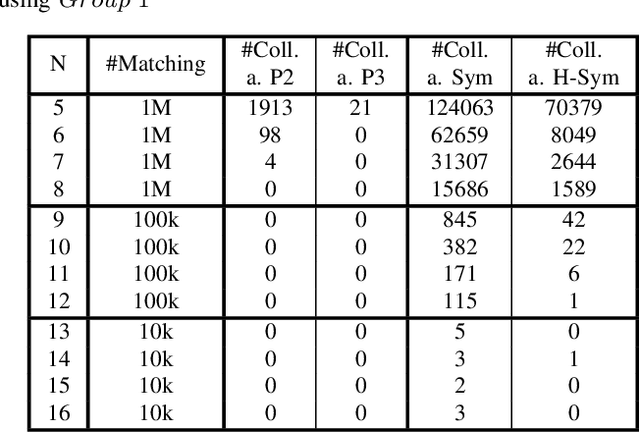
Boolean matching is significant to digital integrated circuits design. An exhaustive method for Boolean matching is computationally expensive even for functions with only a few variables, because the time complexity of such an algorithm for an n-variable Boolean function is $O(2^{n+1}n!)$. Sensitivity is an important characteristic and a measure of the complexity of Boolean functions. It has been used in analysis of the complexity of algorithms in different fields. This measure could be regarded as a signature of Boolean functions and has great potential to help reduce the search space of Boolean matching. In this paper, we introduce Boolean sensitivity into Boolean matching and design several sensitivity-related signatures to enhance fast Boolean matching. First, we propose some new signatures that relate sensitivity to Boolean equivalence. Then, we prove that these signatures are prerequisites for Boolean matching, which we can use to reduce the search space of the matching problem. Besides, we develop a fast sensitivity calculation method to compute and compare these signatures of two Boolean functions. Compared with the traditional cofactor and symmetric detection methods, sensitivity is a series of signatures of another dimension. We also show that sensitivity can be easily integrated into traditional methods and distinguish the mismatched Boolean functions faster. To the best of our knowledge, this is the first work that introduces sensitivity to Boolean matching. The experimental results show that sensitivity-related signatures we proposed in this paper can reduce the search space to a very large extent, and perform up to 3x speedup over the state-of-the-art Boolean matching methods.