 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Output Structure of Sparse Matrix Multiplication with Sampled Compression Ratio
Jul 28, 2022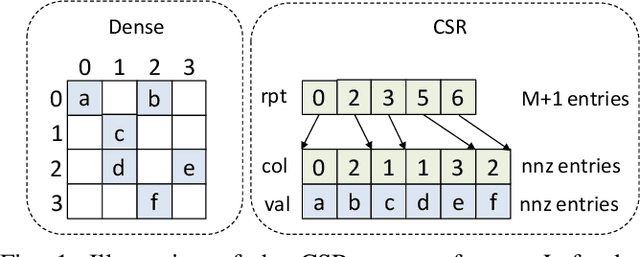
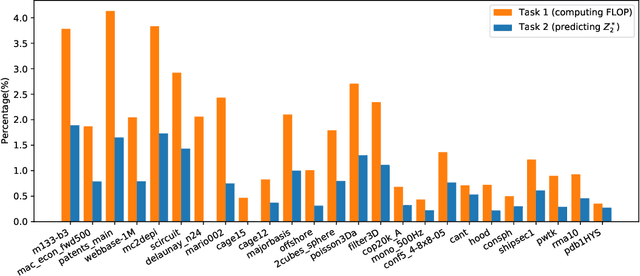
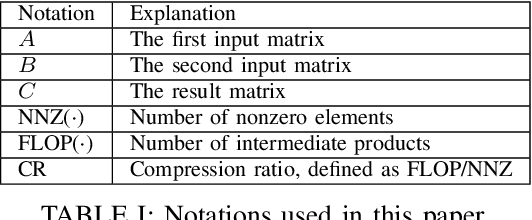
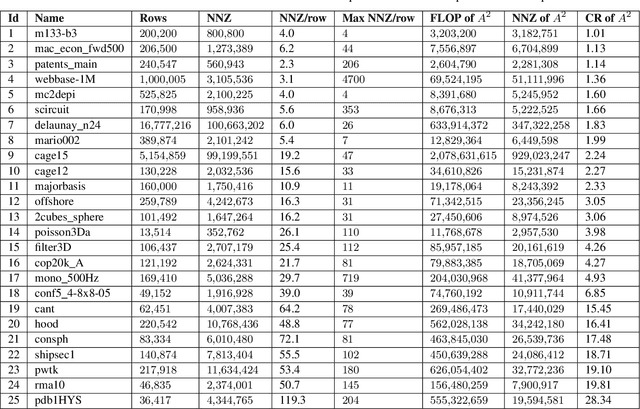
Sparse general matrix multiplication (SpGEMM) is a fundamental building block in numerous scientific applications. One critical task of SpGEMM is to compute or predict the structure of the output matrix (i.e., the number of nonzero elements per output row) for efficient memory allocation and load balance, which impact the overall performance of SpGEMM. Existing work either precisely calculates the output structure or adopts upper-bound or sampling-based methods to predict the output structure. However, these methods either take much execution time or are not accurate enough. In this paper, we propose a novel sampling-based method with better accuracy and low costs compared to the existing sampling-based method. The proposed method first predicts the compression ratio of SpGEMM by leveraging the number of intermediate products (denoted as FLOP) and the number of nonzero elements (denoted as NNZ) of the same sampled result matrix. And then, the predicted output structure is obtained by dividing the FLOP per output row by the predicted compression ratio. We also propose a reference design of the existing sampling-based method with optimized computing overheads to demonstrate the better accuracy of the proposed method. We construct 625 test cases with various matrix dimensions and sparse structures to evaluate the prediction accuracy. Experimental results show that the absolute relative errors of the proposed method and the reference design are 1.56\% and 8.12\%, respectively, on average, and 25\% and 156\%, respectively, in the worst case.
BlockGNN: Towards Efficient GNN Acceleration Using Block-Circulant Weight Matrices
Apr 13, 2021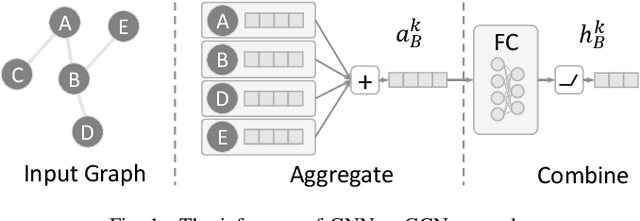
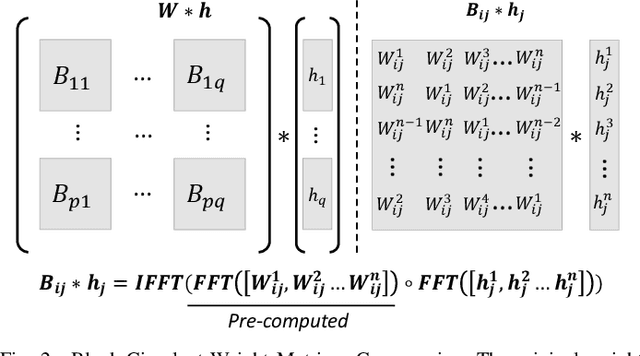
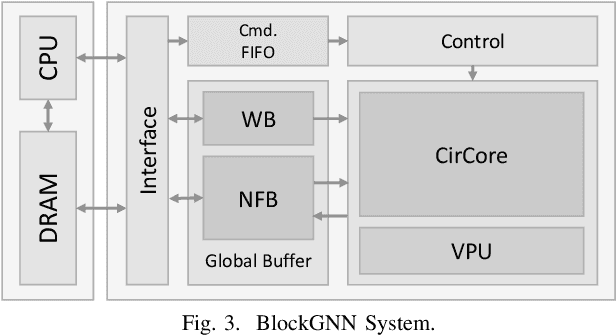
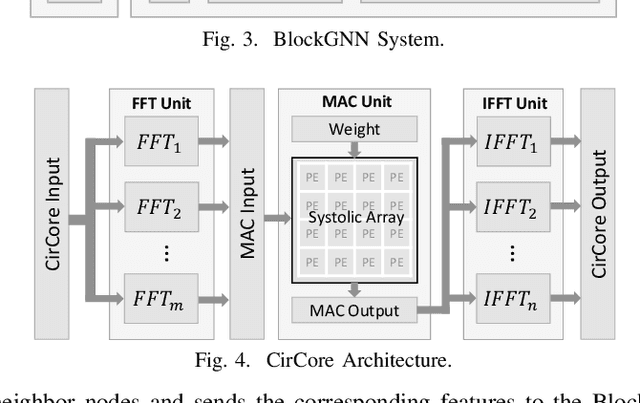
In recent years, Graph Neural Networks (GNNs) appear to be state-of-the-art algorithms for analyzing non-euclidean graph data. By applying deep-learning to extract high-level representations from graph structures, GNNs achieve extraordinary accuracy and great generalization ability in various tasks. However, with the ever-increasing graph sizes, more and more complicated GNN layers, and higher feature dimensions, the computational complexity of GNNs grows exponentially. How to inference GNNs in real time has become a challenging problem, especially for some resource-limited edge-computing platforms. To tackle this challenge, we propose BlockGNN, a software-hardware co-design approach to realize efficient GNN acceleration. At the algorithm level, we propose to leverage block-circulant weight matrices to greatly reduce the complexity of various GNN models. At the hardware design level, we propose a pipelined CirCore architecture, which supports efficient block-circulant matrices computation. Basing on CirCore, we present a novel BlockGNN accelerator to compute various GNNs with low latency. Moreover, to determine the optimal configurations for diverse deployed tasks, we also introduce a performance and resource model that helps choose the optimal hardware parameters automatically. Comprehensive experiments on the ZC706 FPGA platform demonstrate that on various GNN tasks, BlockGNN achieves up to $8.3\times$ speedup compared to the baseline HyGCN architecture and $111.9\times$ energy reduction compared to the Intel Xeon CPU platform.