 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLABench: A Large-Scale Benchmark for Language-Conditioned Robotics Manipulation with Long-Horizon Reasoning Tasks
Dec 24, 2024



General-purposed embodied agents are designed to understand the users' natural instructions or intentions and act precisely to complete universal tasks. Recently, methods based on foundation models especially Vision-Language-Action models (VLAs) have shown a substantial potential to solve language-conditioned manipulation (LCM) tasks well. However, existing benchmarks do not adequately meet the needs of VLAs and relative algorithms. To better define such general-purpose tasks in the context of LLMs and advance the research in VLAs, we present VLABench, an open-source benchmark for evaluating universal LCM task learning. VLABench provides 100 carefully designed categories of tasks, with strong randomization in each category of task and a total of 2000+ objects. VLABench stands out from previous benchmarks in four key aspects: 1) tasks requiring world knowledge and common sense transfer, 2) natural language instructions with implicit human intentions rather than templates, 3) long-horizon tasks demanding multi-step reasoning, and 4) evaluation of both action policies and language model capabilities. The benchmark assesses multiple competencies including understanding of mesh\&texture, spatial relationship, semantic instruction, physical laws, knowledge transfer and reasoning, etc. To support the downstream finetuning, we provide high-quality training data collected via an automated framework incorporating heuristic skills and prior information. The experimental results indicate that both the current state-of-the-art pretrained VLAs and the workflow based on VLMs face challenges in our tasks.
Predicting the Output Structure of Sparse Matrix Multiplication with Sampled Compression Ratio
Jul 28, 2022
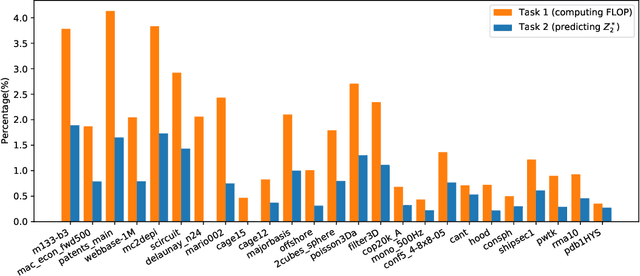
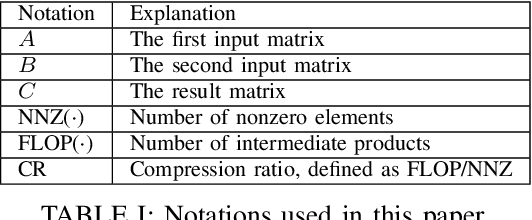
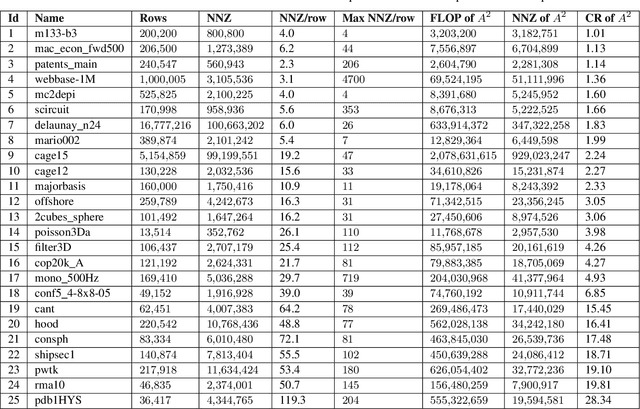
Sparse general matrix multiplication (SpGEMM) is a fundamental building block in numerous scientific applications. One critical task of SpGEMM is to compute or predict the structure of the output matrix (i.e., the number of nonzero elements per output row) for efficient memory allocation and load balance, which impact the overall performance of SpGEMM. Existing work either precisely calculates the output structure or adopts upper-bound or sampling-based methods to predict the output structure. However, these methods either take much execution time or are not accurate enough. In this paper, we propose a novel sampling-based method with better accuracy and low costs compared to the existing sampling-based method. The proposed method first predicts the compression ratio of SpGEMM by leveraging the number of intermediate products (denoted as FLOP) and the number of nonzero elements (denoted as NNZ) of the same sampled result matrix. And then, the predicted output structure is obtained by dividing the FLOP per output row by the predicted compression ratio. We also propose a reference design of the existing sampling-based method with optimized computing overheads to demonstrate the better accuracy of the proposed method. We construct 625 test cases with various matrix dimensions and sparse structures to evaluate the prediction accuracy. Experimental results show that the absolute relative errors of the proposed method and the reference design are 1.56\% and 8.12\%, respectively, on average, and 25\% and 156\%, respectively, in the worst case.
Model-Based Opponent Modeling
Aug 04, 2021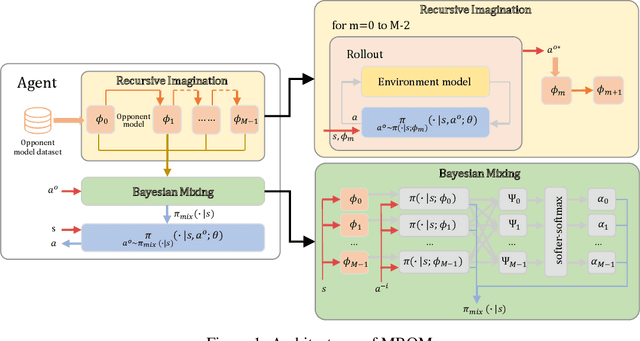
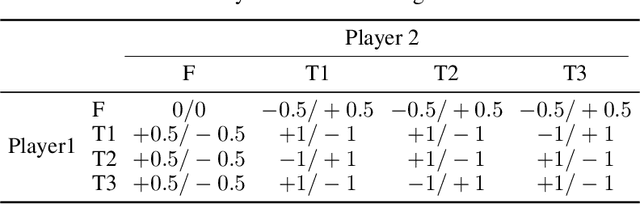
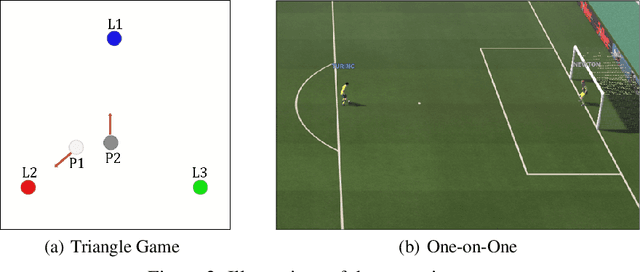
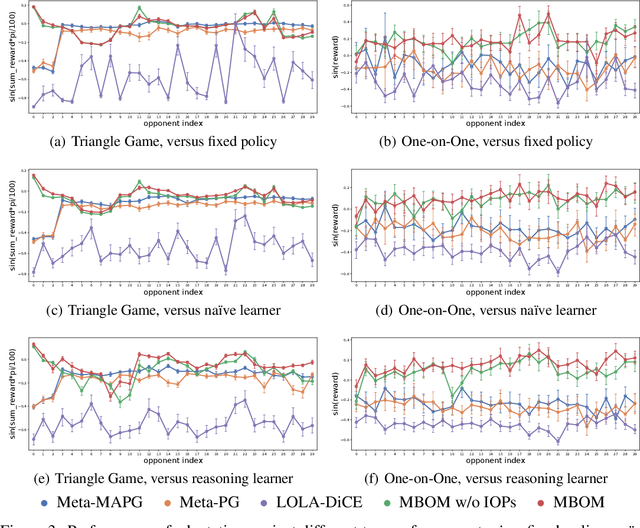
When one agent interacts with a multi-agent environment, it is challenging to deal with various opponents unseen before. Modeling the behaviors, goals, or beliefs of opponents could help the agent adjust its policy to adapt to different opponents. In addition, it is also important to consider opponents who are learning simultaneously or capable of reasoning. However, existing work usually tackles only one of the aforementioned types of opponent. In this paper, we propose model-based opponent modeling (MBOM), which employs the environment model to adapt to all kinds of opponent. MBOM simulates the recursive reasoning process in the environment model and imagines a set of improving opponent policies. To effectively and accurately represent the opponent policy, MBOM further mixes the imagined opponent policies according to the similarity with the real behaviors of opponents. Empirically, we show that MBOM achieves more effective adaptation than existing methods in competitive and cooperative environments, respectively with different types of opponent, i.e., fixed policy, na\"ive learner, and reasoning learner.