 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Humanoid Whole-Body Control via Pretraining and Fast Adaptation
Feb 12, 2026Learning a general whole-body controller for humanoid robots remains challenging due to the diversity of motion distributions, the difficulty of fast adaptation, and the need for robust balance in high-dynamic scenarios. Existing approaches often require task-specific training or suffer from performance degradation when adapting to new motions. In this paper, we present FAST, a general humanoid whole-body control framework that enables Fast Adaptation and Stable Motion Tracking. FAST introduces Parseval-Guided Residual Policy Adaptation, which learns a lightweight delta action policy under orthogonality and KL constraints, enabling efficient adaptation to out-of-distribution motions while mitigating catastrophic forgetting. To further improve physical robustness, we propose Center-of-Mass-Aware Control, which incorporates CoM-related observations and objectives to enhance balance when tracking challenging reference motions. Extensive experiments in simulation and real-world deployment demonstrate that FAST consistently outperforms state-of-the-art baselines in robustness, adaptation efficiency, and generalization.
From Experts to a Generalist: Toward General Whole-Body Control for Humanoid Robots
Jun 15, 2025Achieving general agile whole-body control on humanoid robots remains a major challenge due to diverse motion demands and data conflicts. While existing frameworks excel in training single motion-specific policies, they struggle to generalize across highly varied behaviors due to conflicting control requirements and mismatched data distributions. In this work, we propose BumbleBee (BB), an expert-generalist learning framework that combines motion clustering and sim-to-real adaptation to overcome these challenges. BB first leverages an autoencoder-based clustering method to group behaviorally similar motions using motion features and motion descriptions. Expert policies are then trained within each cluster and refined with real-world data through iterative delta action modeling to bridge the sim-to-real gap. Finally, these experts are distilled into a unified generalist controller that preserves agility and robustness across all motion types. Experiments on two simulations and a real humanoid robot demonstrate that BB achieves state-of-the-art general whole-body control, setting a new benchmark for agile, robust, and generalizable humanoid performance in the real world.
JAEGER: Dual-Level Humanoid Whole-Body Controller
May 10, 2025



This paper presents JAEGER, a dual-level whole-body controller for humanoid robots that addresses the challenges of training a more robust and versatile policy. Unlike traditional single-controller approaches, JAEGER separates the control of the upper and lower bodies into two independent controllers, so that they can better focus on their distinct tasks. This separation alleviates the dimensionality curse and improves fault tolerance. JAEGER supports both root velocity tracking (coarse-grained control) and local joint angle tracking (fine-grained control), enabling versatile and stable movements. To train the controller, we utilize a human motion dataset (AMASS), retargeting human poses to humanoid poses through an efficient retargeting network, and employ a curriculum learning approach. This method performs supervised learning for initialization, followed by reinforcement learning for further exploration. We conduct our experiments on two humanoid platforms and demonstrate the superiority of our approach against state-of-the-art methods in both simulation and real environments.
SELU: Self-Learning Embodied MLLMs in Unknown Environments
Oct 04, 2024



Recently, multimodal large language models (MLLMs) have demonstrated strong visual understanding and decision-making capabilities, enabling the exploration of autonomously improving MLLMs in unknown environments. However, external feedback like human or environmental feedback is not always available. To address this challenge, existing methods primarily focus on enhancing the decision-making capabilities of MLLMs through voting and scoring mechanisms, while little effort has been paid to improving the environmental comprehension of MLLMs in unknown environments. To fully unleash the self-learning potential of MLLMs, we propose a novel actor-critic self-learning paradigm, dubbed SELU, inspired by the actor-critic paradigm in reinforcement learning. The critic employs self-asking and hindsight relabeling to extract knowledge from interaction trajectories collected by the actor, thereby augmenting its environmental comprehension. Simultaneously, the actor is improved by the self-feedback provided by the critic, enhancing its decision-making. We evaluate our method in the AI2-THOR and VirtualHome environments, and SELU achieves critic improvements of approximately 28% and 30%, and actor improvements of about 20% and 24% via self-learning.
Visual Grounding for Object-Level Generalization in Reinforcement Learning
Aug 04, 2024



Generalization is a pivotal challenge for agents following natural language instructions. To approach this goal, we leverage a vision-language model (VLM) for visual grounding and transfer its vision-language knowledge into reinforcement learning (RL) for object-centric tasks, which makes the agent capable of zero-shot generalization to unseen objects and instructions. By visual grounding, we obtain an object-grounded confidence map for the target object indicated in the instruction. Based on this map, we introduce two routes to transfer VLM knowledge into RL. Firstly, we propose an object-grounded intrinsic reward function derived from the confidence map to more effectively guide the agent towards the target object. Secondly, the confidence map offers a more unified, accessible task representation for the agent's policy, compared to language embeddings. This enables the agent to process unseen objects and instructions through comprehensible visual confidence maps, facilitating zero-shot object-level generalization. Single-task experiments prove that our intrinsic reward significantly improves performance on challenging skill learning. In multi-task experiments, through testing on tasks beyond the training set, we show that the agent, when provided with the confidence map as the task representation, possesses better generalization capabilities than language-based conditioning. The code is available at https://github.com/PKU-RL/COPL.
Settling Decentralized Multi-Agent Coordinated Exploration by Novelty Sharing
Feb 03, 2024



Exploration in decentralized cooperative multi-agent reinforcement learning faces two challenges. One is that the novelty of global states is unavailable, while the novelty of local observations is biased. The other is how agents can explore in a coordinated way. To address these challenges, we propose MACE, a simple yet effective multi-agent coordinated exploration method. By communicating only local novelty, agents can take into account other agents' local novelty to approximate the global novelty. Further, we newly introduce weighted mutual information to measure the influence of one agent's action on other agents' accumulated novelty. We convert it as an intrinsic reward in hindsight to encourage agents to exert more influence on other agents' exploration and boost coordinated exploration. Empirically, we show that MACE achieves superior performance in three multi-agent environments with sparse rewards.
Model-Based Opponent Modeling
Aug 04, 2021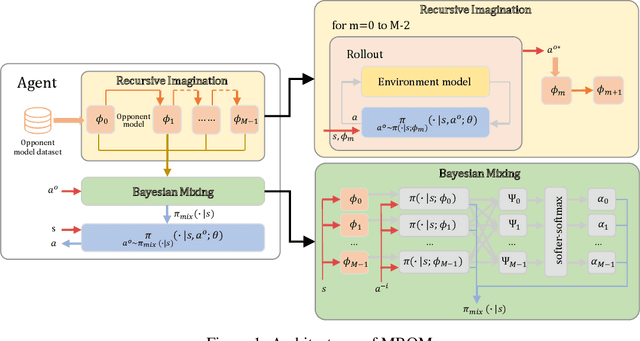
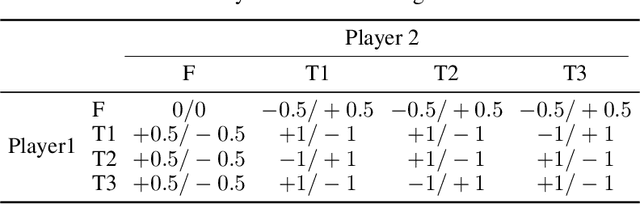
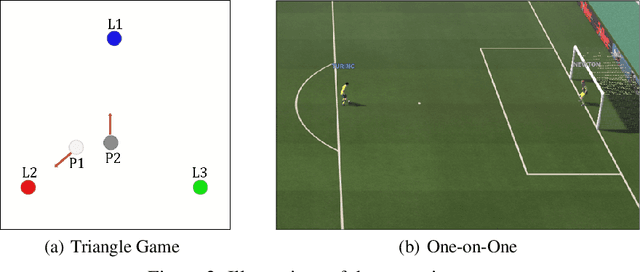
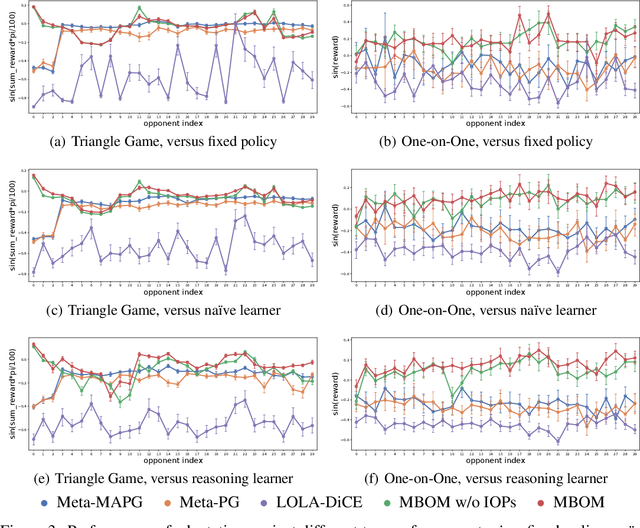
When one agent interacts with a multi-agent environment, it is challenging to deal with various opponents unseen before. Modeling the behaviors, goals, or beliefs of opponents could help the agent adjust its policy to adapt to different opponents. In addition, it is also important to consider opponents who are learning simultaneously or capable of reasoning. However, existing work usually tackles only one of the aforementioned types of opponent. In this paper, we propose model-based opponent modeling (MBOM), which employs the environment model to adapt to all kinds of opponent. MBOM simulates the recursive reasoning process in the environment model and imagines a set of improving opponent policies. To effectively and accurately represent the opponent policy, MBOM further mixes the imagined opponent policies according to the similarity with the real behaviors of opponents. Empirically, we show that MBOM achieves more effective adaptation than existing methods in competitive and cooperative environments, respectively with different types of opponent, i.e., fixed policy, na\"ive learner, and reasoning learner.
Informative Policy Representations in Multi-Agent Reinforcement Learning via Joint-Action Distributions
Jun 10, 2021
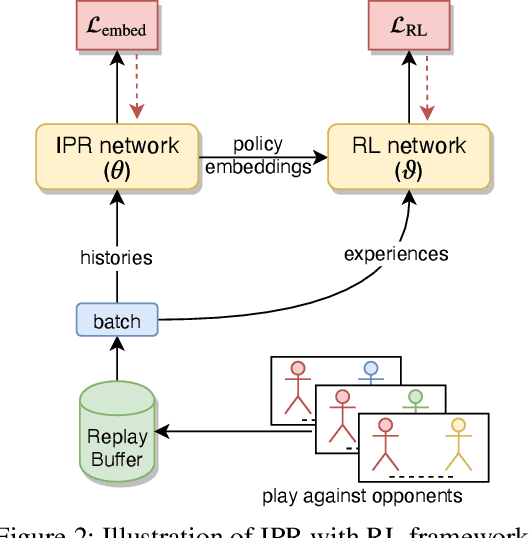
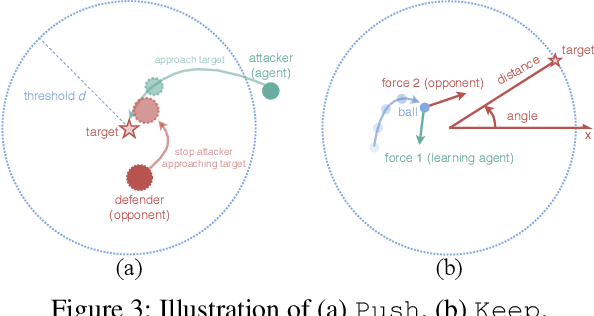
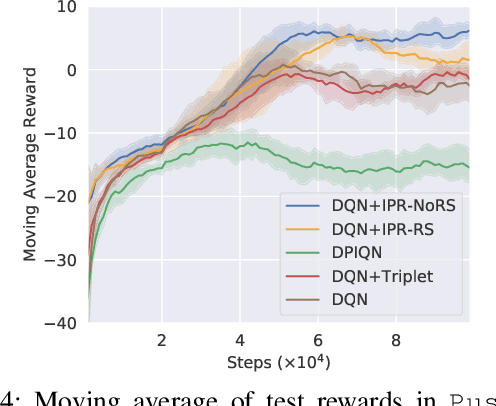
In multi-agent reinforcement learning, the inherent non-stationarity of the environment caused by other agents' actions posed significant difficulties for an agent to learn a good policy independently. One way to deal with non-stationarity is agent modeling, by which the agent takes into consideration the influence of other agents' policies. Most existing work relies on predicting other agents' actions or goals, or discriminating between their policies. However, such modeling fails to capture the similarities and differences between policies simultaneously and thus cannot provide useful information when generalizing to unseen policies. To address this, we propose a general method to learn representations of other agents' policies via the joint-action distributions sampled in interactions. The similarities and differences between policies are naturally captured by the policy distance inferred from the joint-action distributions and deliberately reflected in the learned representations. Agents conditioned on the policy representations can well generalize to unseen agents. We empirically demonstrate that our method outperforms existing work in multi-agent tasks when facing unseen agents.