 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Game Playing Agents and Large Models: Methods, Applications, and Challenges
Mar 15, 2024The swift evolution of Large-scale Models (LMs), either language-focused or multi-modal, has garnered extensive attention in both academy and industry. But despite the surge in interest in this rapidly evolving area, there are scarce systematic reviews on their capabilities and potential in distinct impactful scenarios. This paper endeavours to help bridge this gap, offering a thorough examination of the current landscape of LM usage in regards to complex game playing scenarios and the challenges still open. Here, we seek to systematically review the existing architectures of LM-based Agents (LMAs) for games and summarize their commonalities, challenges, and any other insights. Furthermore, we present our perspective on promising future research avenues for the advancement of LMs in games. We hope to assist researchers in gaining a clear understanding of the field and to generate more interest in this highly impactful research direction. A corresponding resource, continuously updated, can be found in our GitHub repository.
Towards General Computer Control: A Multimodal Agent for Red Dead Redemption II as a Case Study
Mar 07, 2024Despite the success in specific tasks and scenarios, existing foundation agents, empowered by large models (LMs) and advanced tools, still cannot generalize to different scenarios, mainly due to dramatic differences in the observations and actions across scenarios. In this work, we propose the General Computer Control (GCC) setting: building foundation agents that can master any computer task by taking only screen images (and possibly audio) of the computer as input, and producing keyboard and mouse operations as output, similar to human-computer interaction. The main challenges of achieving GCC are: 1) the multimodal observations for decision-making, 2) the requirements of accurate control of keyboard and mouse, 3) the need for long-term memory and reasoning, and 4) the abilities of efficient exploration and self-improvement. To target GCC, we introduce Cradle, an agent framework with six main modules, including: 1) information gathering to extract multi-modality information, 2) self-reflection to rethink past experiences, 3) task inference to choose the best next task, 4) skill curation for generating and updating relevant skills for given tasks, 5) action planning to generate specific operations for keyboard and mouse control, and 6) memory for storage and retrieval of past experiences and known skills. To demonstrate the capabilities of generalization and self-improvement of Cradle, we deploy it in the complex AAA game Red Dead Redemption II, serving as a preliminary attempt towards GCC with a challenging target. To our best knowledge, our work is the first to enable LMM-based agents to follow the main storyline and finish real missions in complex AAA games, with minimal reliance on prior knowledge or resources. The project website is at https://baai-agents.github.io/Cradle/.
Fully Decentralized Cooperative Multi-Agent Reinforcement Learning: A Survey
Jan 10, 2024Cooperative multi-agent reinforcement learning is a powerful tool to solve many real-world cooperative tasks, but restrictions of real-world applications may require training the agents in a fully decentralized manner. Due to the lack of information about other agents, it is challenging to derive algorithms that can converge to the optimal joint policy in a fully decentralized setting. Thus, this research area has not been thoroughly studied. In this paper, we seek to systematically review the fully decentralized methods in two settings: maximizing a shared reward of all agents and maximizing the sum of individual rewards of all agents, and discuss open questions and future research directions.
Learning from Visual Observation via Offline Pretrained State-to-Go Transformer
Jun 22, 2023Learning from visual observation (LfVO), aiming at recovering policies from only visual observation data, is promising yet a challenging problem. Existing LfVO approaches either only adopt inefficient online learning schemes or require additional task-specific information like goal states, making them not suited for open-ended tasks. To address these issues, we propose a two-stage framework for learning from visual observation. In the first stage, we introduce and pretrain State-to-Go (STG) Transformer offline to predict and differentiate latent transitions of demonstrations. Subsequently, in the second stage, the STG Transformer provides intrinsic rewards for downstream reinforcement learning tasks where an agent learns merely from intrinsic rewards. Empirical results on Atari and Minecraft show that our proposed method outperforms baselines and in some tasks even achieves performance comparable to the policy learned from environmental rewards. These results shed light on the potential of utilizing video-only data to solve difficult visual reinforcement learning tasks rather than relying on complete offline datasets containing states, actions, and rewards. The project's website and code can be found at https://sites.google.com/view/stgtransformer.
Model-Based Decentralized Policy Optimization
Feb 16, 2023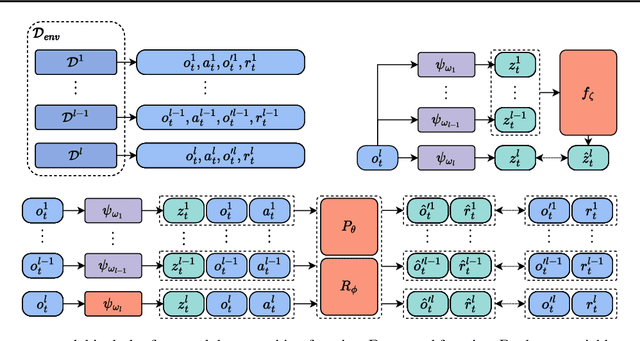

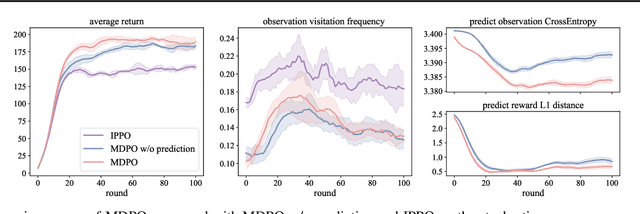

Decentralized policy optimization has been commonly used in cooperative multi-agent tasks. However, since all agents are updating their policies simultaneously, from the perspective of individual agents, the environment is non-stationary, resulting in it being hard to guarantee monotonic policy improvement. To help the policy improvement be stable and monotonic, we propose model-based decentralized policy optimization (MDPO), which incorporates a latent variable function to help construct the transition and reward function from an individual perspective. We theoretically analyze that the policy optimization of MDPO is more stable than model-free decentralized policy optimization. Moreover, due to non-stationarity, the latent variable function is varying and hard to be modeled. We further propose a latent variable prediction method to reduce the error of the latent variable function, which theoretically contributes to the monotonic policy improvement. Empirically, MDPO can indeed obtain superior performance than model-free decentralized policy optimization in a variety of cooperative multi-agent tasks.
Best Possible Q-Learning
Feb 02, 2023Fully decentralized learning, where the global information, i.e., the actions of other agents, is inaccessible, is a fundamental challenge in cooperative multi-agent reinforcement learning. However, the convergence and optimality of most decentralized algorithms are not theoretically guaranteed, since the transition probabilities are non-stationary as all agents are updating policies simultaneously. To tackle this challenge, we propose best possible operator, a novel decentralized operator, and prove that the policies of agents will converge to the optimal joint policy if each agent independently updates its individual state-action value by the operator. Further, to make the update more efficient and practical, we simplify the operator and prove that the convergence and optimality still hold with the simplified one. By instantiating the simplified operator, the derived fully decentralized algorithm, best possible Q-learning (BQL), does not suffer from non-stationarity. Empirically, we show that BQL achieves remarkable improvement over baselines in a variety of cooperative multi-agent tasks.
Model-Based Opponent Modeling
Aug 04, 2021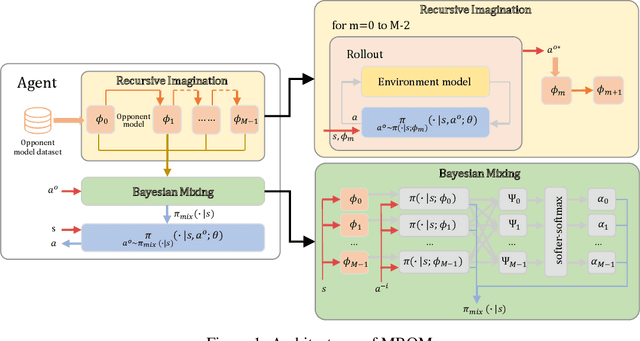
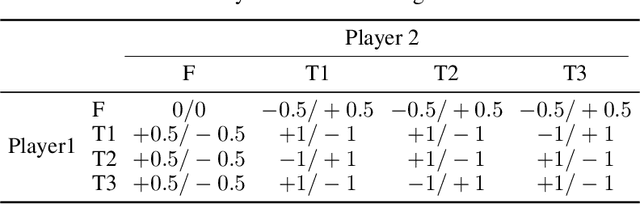
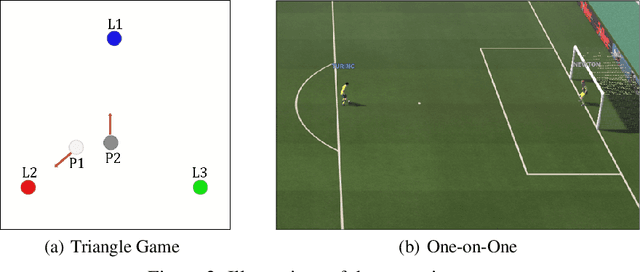
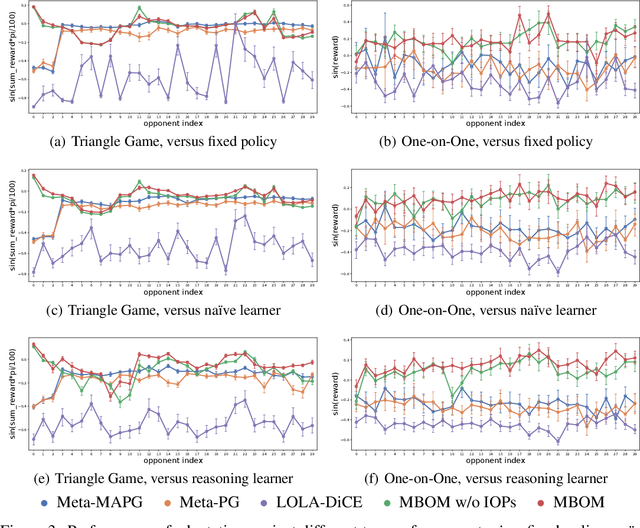
When one agent interacts with a multi-agent environment, it is challenging to deal with various opponents unseen before. Modeling the behaviors, goals, or beliefs of opponents could help the agent adjust its policy to adapt to different opponents. In addition, it is also important to consider opponents who are learning simultaneously or capable of reasoning. However, existing work usually tackles only one of the aforementioned types of opponent. In this paper, we propose model-based opponent modeling (MBOM), which employs the environment model to adapt to all kinds of opponent. MBOM simulates the recursive reasoning process in the environment model and imagines a set of improving opponent policies. To effectively and accurately represent the opponent policy, MBOM further mixes the imagined opponent policies according to the similarity with the real behaviors of opponents. Empirically, we show that MBOM achieves more effective adaptation than existing methods in competitive and cooperative environments, respectively with different types of opponent, i.e., fixed policy, na\"ive learner, and reasoning learner.
Offline Decentralized Multi-Agent Reinforcement Learning
Aug 04, 2021
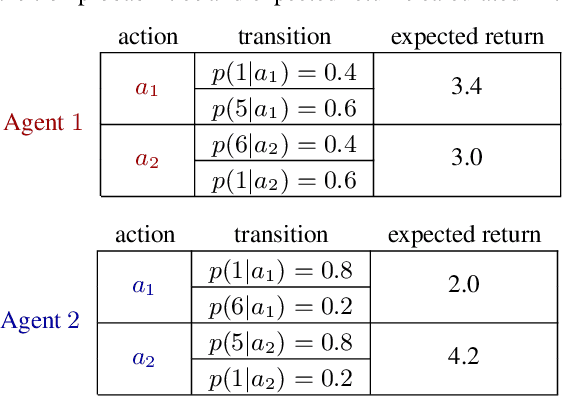
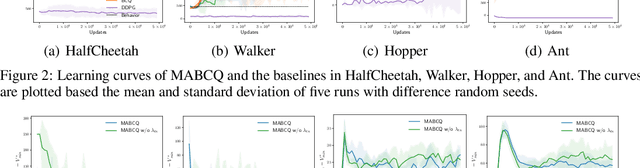
In many real-world multi-agent cooperative tasks, due to high cost and risk, agents cannot interact with the environment and collect experiences during learning, but have to learn from offline datasets. However, the transition probabilities calculated from the dataset can be much different from the transition probabilities induced by the learned policies of other agents, creating large errors in value estimates. Moreover, the experience distributions of agents' datasets may vary wildly due to diverse behavior policies, causing large difference in value estimates between agents. Consequently, agents will learn uncoordinated suboptimal policies. In this paper, we propose MABCQ, which exploits value deviation and transition normalization to modify the transition probabilities. Value deviation optimistically increases the transition probabilities of high-value next states, and transition normalization normalizes the biased transition probabilities of next states. They together encourage agents to discover potential optimal and coordinated policies. Mathematically, we prove the convergence of Q-learning under the non-stationary transition probabilities after modification. Empirically, we show that MABCQ greatly outperforms baselines and reduces the difference in value estimates between agents.
The Emergence of Individuality in Multi-Agent Reinforcement Learning
Jun 10, 2020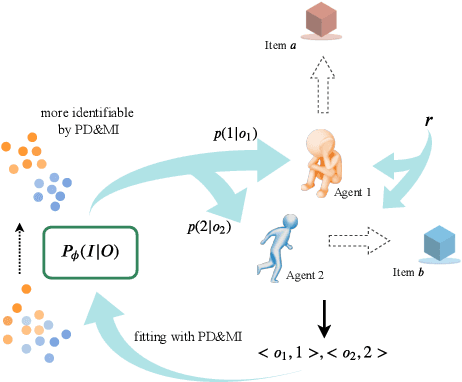
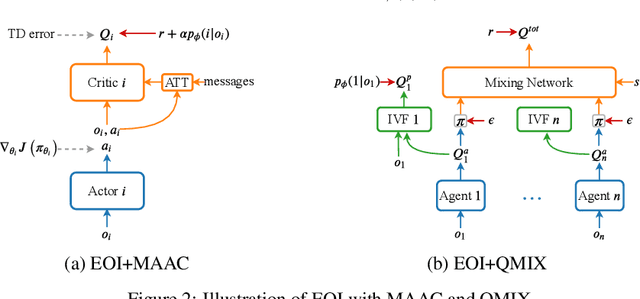
Individuality is essential in human society, which induces the division of labor and thus improves the efficiency and productivity. Similarly, it should also be the key to multi-agent cooperation. Inspired by that individuality is of being an individual separate from others, we propose a simple yet efficient method for the emergence of individuality (EOI) in multi-agent reinforcement learning (MARL). EOI learns a probabilistic classifier that predicts a probability distribution over agents given their observation and gives each agent an intrinsic reward of being correctly predicted by the classifier. The intrinsic reward encourages the agents to visit their own familiar observations, and learning the classifier by such observations makes the intrinsic reward signals stronger and the agents more identifiable. To further enhance the intrinsic reward and promote the emergence of individuality, two regularizers are proposed to increase the discriminability of the classifier. We implement EOI on top of popular MARL algorithms. Empirically, we show that EOI significantly outperforms existing methods in a variety of multi-agent cooperative scenarios.
Learning Fairness in Multi-Agent Systems
Oct 31, 2019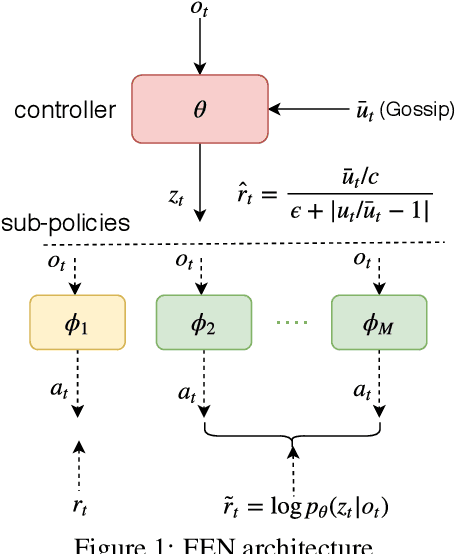
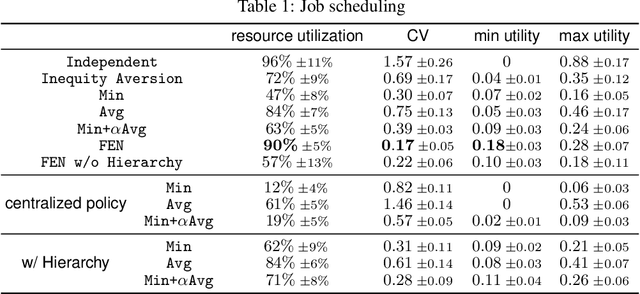

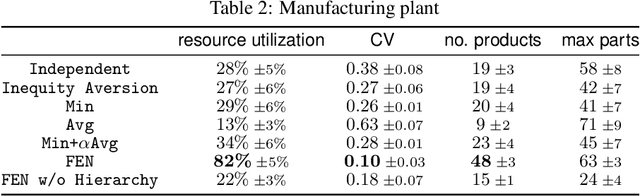
Fairness is essential for human society, contributing to stability and productivity. Similarly, fairness is also the key for many multi-agent systems. Taking fairness into multi-agent learning could help multi-agent systems become both efficient and stable. However, learning efficiency and fairness simultaneously is a complex, multi-objective, joint-policy optimization. To tackle these difficulties, we propose FEN, a novel hierarchical reinforcement learning model. We first decompose fairness for each agent and propose fair-efficient reward that each agent learns its own policy to optimize. To avoid multi-objective conflict, we design a hierarchy consisting of a controller and several sub-policies, where the controller maximizes the fair-efficient reward by switching among the sub-policies that provides diverse behaviors to interact with the environment. FEN can be trained in a fully decentralized way, making it easy to be deployed in real-world applications. Empirically, we show that FEN easily learns both fairness and efficiency and significantly outperforms baselines in a variety of multi-agent scenarios.