 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepPHY: Benchmarking Agentic VLMs on Physical Reasoning
Aug 07, 2025Although Vision Language Models (VLMs) exhibit strong perceptual abilities and impressive visual reasoning, they struggle with attention to detail and precise action planning in complex, dynamic environments, leading to subpar performance. Real-world tasks typically require complex interactions, advanced spatial reasoning, long-term planning, and continuous strategy refinement, usually necessitating understanding the physics rules of the target scenario. However, evaluating these capabilities in real-world scenarios is often prohibitively expensive. To bridge this gap, we introduce DeepPHY, a novel benchmark framework designed to systematically evaluate VLMs' understanding and reasoning about fundamental physical principles through a series of challenging simulated environments. DeepPHY integrates multiple physical reasoning environments of varying difficulty levels and incorporates fine-grained evaluation metrics. Our evaluation finds that even state-of-the-art VLMs struggle to translate descriptive physical knowledge into precise, predictive control.
High-Quality Pseudo-Label Generation Based on Visual Prompt Assisted Cloud Model Update
Apr 01, 2025



Generating high-quality pseudo-labels on the cloud is crucial for cloud-edge object detection, especially in dynamic traffic monitoring where data distributions evolve. Existing methods often assume reliable cloud models, neglecting potential errors or struggling with complex distribution shifts. This paper proposes Cloud-Adaptive High-Quality Pseudo-label generation (CA-HQP), addressing these limitations by incorporating a learnable Visual Prompt Generator (VPG) and dual feature alignment into cloud model updates. The VPG enables parameter-efficient adaptation by injecting visual prompts, enhancing flexibility without extensive fine-tuning. CA-HQP mitigates domain discrepancies via two feature alignment techniques: global Domain Query Feature Alignment (DQFA) capturing scene-level shifts, and fine-grained Temporal Instance-Aware Feature Embedding Alignment (TIAFA) addressing instance variations. Experiments on the Bellevue traffic dataset demonstrate that CA-HQP significantly improves pseudo-label quality compared to existing methods, leading to notable performance gains for the edge model and showcasing CA-HQP's adaptation effectiveness. Ablation studies validate each component (DQFA, TIAFA, VPG) and the synergistic effect of combined alignment strategies, highlighting the importance of adaptive cloud updates and domain adaptation for robust object detection in evolving scenarios. CA-HQP provides a promising solution for enhancing cloud-edge object detection systems in real-world applications.
Vulnerability of Text-to-Image Models to Prompt Template Stealing: A Differential Evolution Approach
Feb 20, 2025Prompt trading has emerged as a significant intellectual property concern in recent years, where vendors entice users by showcasing sample images before selling prompt templates that can generate similar images. This work investigates a critical security vulnerability: attackers can steal prompt templates using only a limited number of sample images. To investigate this threat, we introduce Prism, a prompt-stealing benchmark consisting of 50 templates and 450 images, organized into Easy and Hard difficulty levels. To identify the vulnerabity of VLMs to prompt stealing, we propose EvoStealer, a novel template stealing method that operates without model fine-tuning by leveraging differential evolution algorithms. The system first initializes population sets using multimodal large language models (MLLMs) based on predefined patterns, then iteratively generates enhanced offspring through MLLMs. During evolution, EvoStealer identifies common features across offspring to derive generalized templates. Our comprehensive evaluation conducted across open-source (INTERNVL2-26B) and closed-source models (GPT-4o and GPT-4o-mini) demonstrates that EvoStealer's stolen templates can reproduce images highly similar to originals and effectively generalize to other subjects, significantly outperforming baseline methods with an average improvement of over 10%. Moreover, our cost analysis reveals that EvoStealer achieves template stealing with negligible computational expenses. Our code and dataset are available at https://github.com/whitepagewu/evostealer.
Extract Information from Hybrid Long Documents Leveraging LLMs: A Framework and Dataset
Dec 28, 2024



Large Language Models (LLMs) demonstrate exceptional performance in textual understanding and tabular reasoning tasks. However, their ability to comprehend and analyze hybrid text, containing textual and tabular data, remains unexplored. The hybrid text often appears in the form of hybrid long documents (HLDs), which far exceed the token limit of LLMs. Consequently, we apply an Automated Information Extraction framework (AIE) to enable LLMs to process the HLDs and carry out experiments to analyse four important aspects of information extraction from HLDs. Given the findings: 1) The effective way to select and summarize the useful part of a HLD. 2) An easy table serialization way is enough for LLMs to understand tables. 3) The naive AIE has adaptability in many complex scenarios. 4) The useful prompt engineering to enhance LLMs on HLDs. To address the issue of dataset scarcity in HLDs and support future work, we also propose the Financial Reports Numerical Extraction (FINE) dataset. The dataset and code are publicly available in the attachments.
AMPO: Automatic Multi-Branched Prompt Optimization
Oct 11, 2024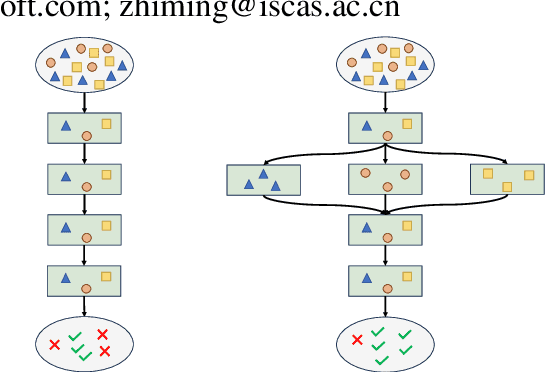
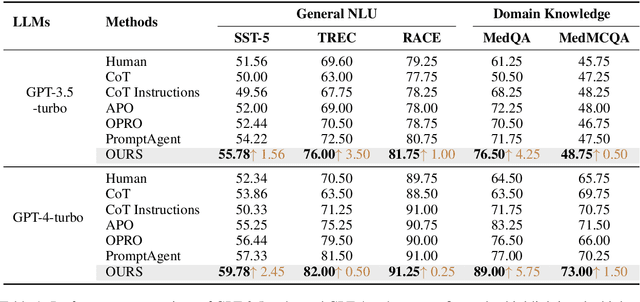
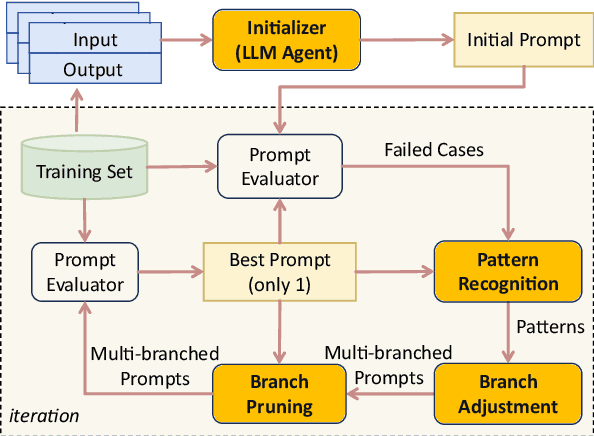
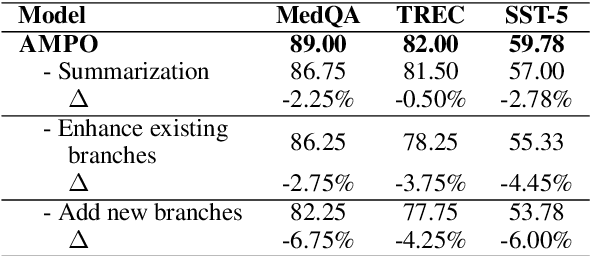
Prompt engineering is very important to enhance the performance of large language models (LLMs). When dealing with complex issues, prompt engineers tend to distill multiple patterns from examples and inject relevant solutions to optimize the prompts, achieving satisfying results. However, existing automatic prompt optimization techniques are only limited to producing single flow instructions, struggling with handling diverse patterns. In this paper, we present AMPO, an automatic prompt optimization method that can iteratively develop a multi-branched prompt using failure cases as feedback. Our goal is to explore a novel way of structuring prompts with multi-branches to better handle multiple patterns in complex tasks, for which we introduce three modules: Pattern Recognition, Branch Adjustment, and Branch Pruning. In experiments across five tasks, AMPO consistently achieves the best results. Additionally, our approach demonstrates significant optimization efficiency due to our adoption of a minimal search strategy.
StraGo: Harnessing Strategic Guidance for Prompt Optimization
Oct 11, 2024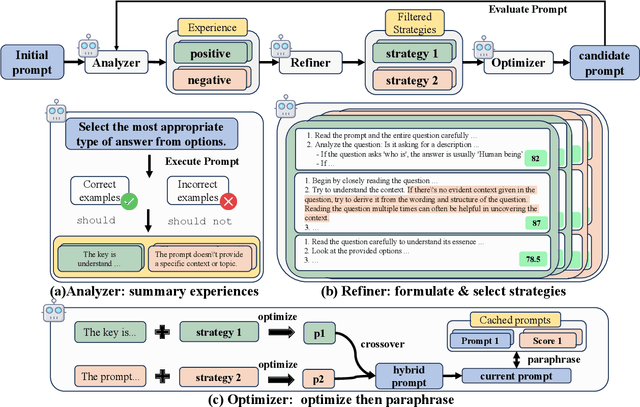
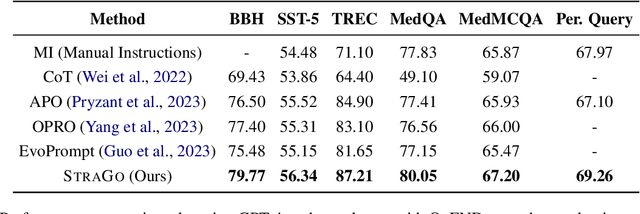
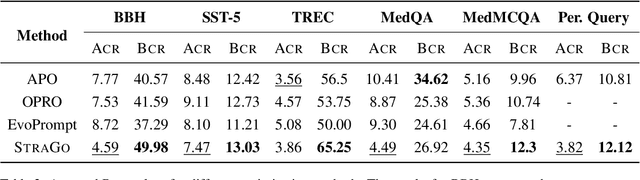
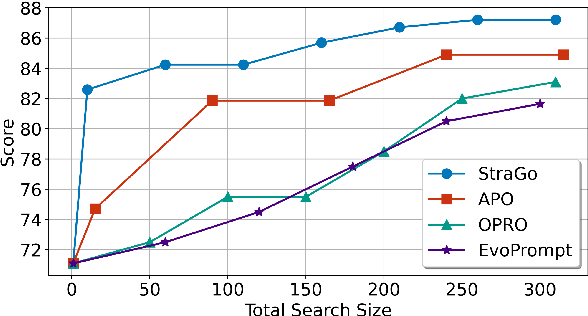
Prompt engineering is pivotal for harnessing the capabilities of large language models (LLMs) across diverse applications. While existing prompt optimization methods improve prompt effectiveness, they often lead to prompt drifting, where newly generated prompts can adversely impact previously successful cases while addressing failures. Furthermore, these methods tend to rely heavily on LLMs' intrinsic capabilities for prompt optimization tasks. In this paper, we introduce StraGo (Strategic-Guided Optimization), a novel approach designed to mitigate prompt drifting by leveraging insights from both successful and failed cases to identify critical factors for achieving optimization objectives. StraGo employs a how-to-do methodology, integrating in-context learning to formulate specific, actionable strategies that provide detailed, step-by-step guidance for prompt optimization. Extensive experiments conducted across a range of tasks, including reasoning, natural language understanding, domain-specific knowledge, and industrial applications, demonstrate StraGo's superior performance. It establishes a new state-of-the-art in prompt optimization, showcasing its ability to deliver stable and effective prompt improvements.
Research on Foundation Model for Spatial Data Intelligence: China's 2024 White Paper on Strategic Development of Spatial Data Intelligence
May 30, 2024This report focuses on spatial data intelligent large models, delving into the principles, methods, and cutting-edge applications of these models. It provides an in-depth discussion on the definition, development history, current status, and trends of spatial data intelligent large models, as well as the challenges they face. The report systematically elucidates the key technologies of spatial data intelligent large models and their applications in urban environments, aerospace remote sensing, geography, transportation, and other scenarios. Additionally, it summarizes the latest application cases of spatial data intelligent large models in themes such as urban development, multimodal systems, remote sensing, smart transportation, and resource environments. Finally, the report concludes with an overview and outlook on the development prospects of spatial data intelligent large models.
A Clustering Method with Graph Maximum Decoding Information
Mar 18, 2024



The clustering method based on graph models has garnered increased attention for its widespread applicability across various knowledge domains. Its adaptability to integrate seamlessly with other relevant applications endows the graph model-based clustering analysis with the ability to robustly extract "natural associations" or "graph structures" within datasets, facilitating the modelling of relationships between data points. Despite its efficacy, the current clustering method utilizing the graph-based model overlooks the uncertainty associated with random walk access between nodes and the embedded structural information in the data. To address this gap, we present a novel Clustering method for Maximizing Decoding Information within graph-based models, named CMDI. CMDI innovatively incorporates two-dimensional structural information theory into the clustering process, consisting of two phases: graph structure extraction and graph vertex partitioning. Within CMDI, graph partitioning is reformulated as an abstract clustering problem, leveraging maximum decoding information to minimize uncertainty associated with random visits to vertices. Empirical evaluations on three real-world datasets demonstrate that CMDI outperforms classical baseline methods, exhibiting a superior decoding information ratio (DI-R). Furthermore, CMDI showcases heightened efficiency, particularly when considering prior knowledge (PK). These findings underscore the effectiveness of CMDI in enhancing decoding information quality and computational efficiency, positioning it as a valuable tool in graph-based clustering analyses.
A Multi-constraint and Multi-objective Allocation Model for Emergency Rescue in IoT Environment
Mar 15, 2024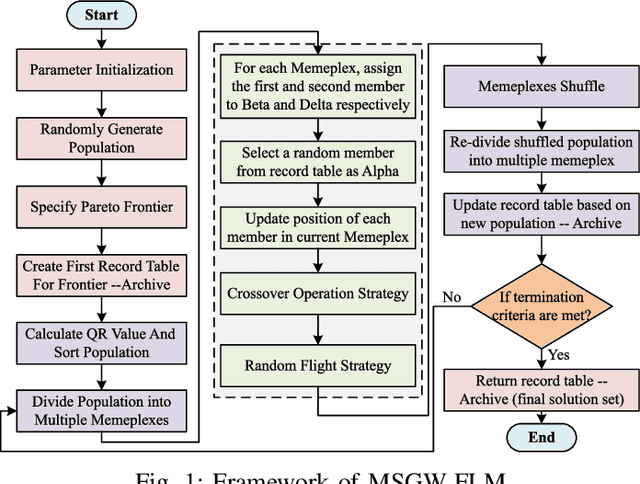
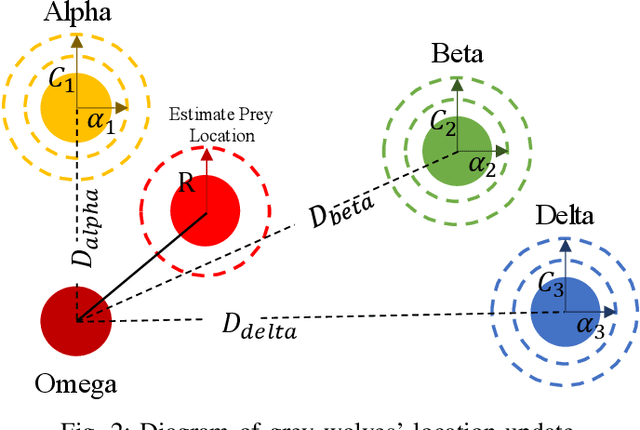
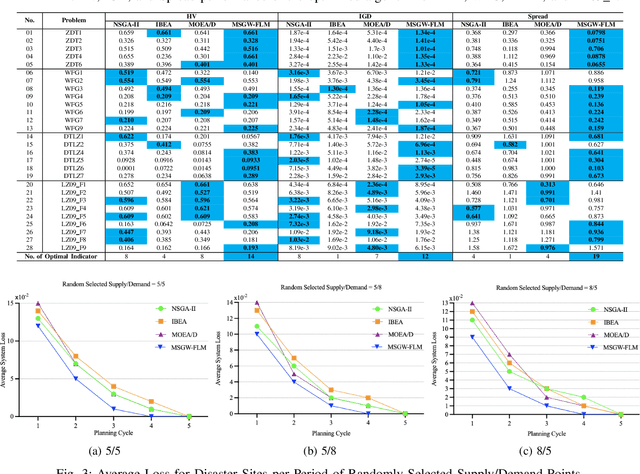
Emergency relief operations are essential in disaster aftermaths, necessitating effective resource allocation to minimize negative impacts and maximize benefits. In prolonged crises or extensive disasters, a systematic, multi-cycle approach is key for timely and informed decision-making. Leveraging advancements in IoT and spatio-temporal data analytics, we've developed the Multi-Objective Shuffled Gray-Wolf Frog Leaping Model (MSGW-FLM). This multi-constraint, multi-objective resource allocation model has been rigorously tested against 28 diverse challenges, showing superior performance in comparison to established models such as NSGA-II, IBEA, and MOEA/D. MSGW-FLM's effectiveness is particularly notable in complex, multi-cycle emergency rescue scenarios, which involve numerous constraints and objectives. This model represents a significant step forward in optimizing resource distribution in emergency response situations.
A Survey on Game Playing Agents and Large Models: Methods, Applications, and Challenges
Mar 15, 2024The swift evolution of Large-scale Models (LMs), either language-focused or multi-modal, has garnered extensive attention in both academy and industry. But despite the surge in interest in this rapidly evolving area, there are scarce systematic reviews on their capabilities and potential in distinct impactful scenarios. This paper endeavours to help bridge this gap, offering a thorough examination of the current landscape of LM usage in regards to complex game playing scenarios and the challenges still open. Here, we seek to systematically review the existing architectures of LM-based Agents (LMAs) for games and summarize their commonalities, challenges, and any other insights. Furthermore, we present our perspective on promising future research avenues for the advancement of LMs in games. We hope to assist researchers in gaining a clear understanding of the field and to generate more interest in this highly impactful research direction. A corresponding resource, continuously updated, can be found in our GitHub repository.