 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated Differentiable Working Memory for Long-Context Language Modeling
Jan 19, 2026Long contexts challenge transformers: attention scores dilute across thousands of tokens, critical information is often lost in the middle, and models struggle to adapt to novel patterns at inference time. Recent work on test-time adaptation addresses this by maintaining a form of working memory -- transient parameters updated on the current context -- but existing approaches rely on uniform write policies that waste computation on low-utility regions and suffer from high gradient variance across semantically heterogeneous contexts. In this work, we reframe test-time adaptation as a budget-constrained memory consolidation problem, focusing on which parts of the context should be consolidated into working memory under limited computation. We propose Gdwm (Gated Differentiable Working Memory), a framework that introduces a write controller to gate the consolidation process. The controller estimates Contextual Utility, an information-theoretic measure of long-range contextual dependence, and allocates gradient steps accordingly while maintaining global coverage. Experiments on ZeroSCROLLS and LongBench v2 demonstrate that Gdwm achieves comparable or superior performance with 4$\times$ fewer gradient steps than uniform baselines, establishing a new efficiency-performance Pareto frontier for test-time adaptation.
Reward and Guidance through Rubrics: Promoting Exploration to Improve Multi-Domain Reasoning
Nov 18, 2025



Recent advances in reinforcement learning (RL) have significantly improved the complex reasoning capabilities of large language models (LLMs). Despite these successes, existing methods mainly focus on single-domain RL (e.g., mathematics) with verifiable rewards (RLVR), and their reliance on purely online RL frameworks restricts the exploration space, thereby limiting reasoning performance. In this paper, we address these limitations by leveraging rubrics to provide both fine-grained reward signals and offline guidance. We propose $\textbf{RGR-GRPO}$ (Reward and Guidance through Rubrics), a rubric-driven RL framework for multi-domain reasoning. RGR-GRPO enables LLMs to receive dense and informative rewards while exploring a larger solution space during GRPO training. Extensive experiments across 14 benchmarks spanning multiple domains demonstrate that RGR-GRPO consistently outperforms RL methods that rely solely on alternative reward schemes or offline guidance. Compared with verifiable online RL baseline, RGR-GRPO achieves average improvements of +7.0%, +5.4%, +8.4%, and +6.6% on mathematics, physics, chemistry, and general reasoning tasks, respectively. Notably, RGR-GRPO maintains stable entropy fluctuations during off-policy training and achieves superior pass@k performance, reflecting sustained exploration and effective breakthrough beyond existing performance bottlenecks.
A Survey of Vibe Coding with Large Language Models
Oct 14, 2025The advancement of large language models (LLMs) has catalyzed a paradigm shift from code generation assistance to autonomous coding agents, enabling a novel development methodology termed "Vibe Coding" where developers validate AI-generated implementations through outcome observation rather than line-by-line code comprehension. Despite its transformative potential, the effectiveness of this emergent paradigm remains under-explored, with empirical evidence revealing unexpected productivity losses and fundamental challenges in human-AI collaboration. To address this gap, this survey provides the first comprehensive and systematic review of Vibe Coding with large language models, establishing both theoretical foundations and practical frameworks for this transformative development approach. Drawing from systematic analysis of over 1000 research papers, we survey the entire vibe coding ecosystem, examining critical infrastructure components including LLMs for coding, LLM-based coding agent, development environment of coding agent, and feedback mechanisms. We first introduce Vibe Coding as a formal discipline by formalizing it through a Constrained Markov Decision Process that captures the dynamic triadic relationship among human developers, software projects, and coding agents. Building upon this theoretical foundation, we then synthesize existing practices into five distinct development models: Unconstrained Automation, Iterative Conversational Collaboration, Planning-Driven, Test-Driven, and Context-Enhanced Models, thus providing the first comprehensive taxonomy in this domain. Critically, our analysis reveals that successful Vibe Coding depends not merely on agent capabilities but on systematic context engineering, well-established development environments, and human-agent collaborative development models.
AdaptFlow: Adaptive Workflow Optimization via Meta-Learning
Aug 11, 2025Recent advances in large language models (LLMs) have sparked growing interest in agentic workflows, which are structured sequences of LLM invocations intended to solve complex tasks. However, existing approaches often rely on static templates or manually designed workflows, which limit adaptability to diverse tasks and hinder scalability. We propose AdaptFlow, a natural language-based meta-learning framework inspired by model-agnostic meta-learning (MAML). AdaptFlow learns a generalizable workflow initialization that enables rapid subtask-level adaptation. It employs a bi-level optimization scheme: the inner loop refines the workflow for a specific subtask using LLM-generated feedback, while the outer loop updates the shared initialization to perform well across tasks. This setup allows AdaptFlow to generalize effectively to unseen tasks by adapting the initialized workflow through language-guided modifications. Evaluated across question answering, code generation, and mathematical reasoning benchmarks, AdaptFlow consistently outperforms both manually crafted and automatically searched baselines, achieving state-of-the-art results with strong generalization across tasks and models. The source code and data are available at https://github.com/microsoft/DKI_LLM/tree/AdaptFlow/AdaptFlow.
A Survey of Context Engineering for Large Language Models
Jul 17, 2025The performance of Large Language Models (LLMs) is fundamentally determined by the contextual information provided during inference. This survey introduces Context Engineering, a formal discipline that transcends simple prompt design to encompass the systematic optimization of information payloads for LLMs. We present a comprehensive taxonomy decomposing Context Engineering into its foundational components and the sophisticated implementations that integrate them into intelligent systems. We first examine the foundational components: context retrieval and generation, context processing and context management. We then explore how these components are architecturally integrated to create sophisticated system implementations: retrieval-augmented generation (RAG), memory systems and tool-integrated reasoning, and multi-agent systems. Through this systematic analysis of over 1300 research papers, our survey not only establishes a technical roadmap for the field but also reveals a critical research gap: a fundamental asymmetry exists between model capabilities. While current models, augmented by advanced context engineering, demonstrate remarkable proficiency in understanding complex contexts, they exhibit pronounced limitations in generating equally sophisticated, long-form outputs. Addressing this gap is a defining priority for future research. Ultimately, this survey provides a unified framework for both researchers and engineers advancing context-aware AI.
Rethinking All Evidence: Enhancing Trustworthy Retrieval-Augmented Generation via Conflict-Driven Summarization
Jul 02, 2025Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by integrating their parametric knowledge with external retrieved content. However, knowledge conflicts caused by internal inconsistencies or noisy retrieved content can severely undermine the generation reliability of RAG systems.In this work, we argue that LLMs should rethink all evidence, including both retrieved content and internal knowledge, before generating responses.We propose CARE-RAG (Conflict-Aware and Reliable Evidence for RAG), a novel framework that improves trustworthiness through Conflict-Driven Summarization of all available evidence.CARE-RAG first derives parameter-aware evidence by comparing parameter records to identify diverse internal perspectives. It then refines retrieved evidences to produce context-aware evidence, removing irrelevant or misleading content. To detect and summarize conflicts, we distill a 3B LLaMA3.2 model to perform conflict-driven summarization, enabling reliable synthesis across multiple sources.To further ensure evaluation integrity, we introduce a QA Repair step to correct outdated or ambiguous benchmark answers.Experiments on revised QA datasets with retrieval data show that CARE-RAG consistently outperforms strong RAG baselines, especially in scenarios with noisy or conflicting evidence.
Large Language Models as Computable Approximations to Solomonoff Induction
May 21, 2025The rapid advancement of large language models (LLMs) calls for a rigorous theoretical framework to explain their empirical success. While significant progress has been made in understanding LLM behaviors, existing theoretical frameworks remain fragmented in explaining emergent phenomena through a unified mathematical lens. We establish the first formal connection between LLM architectures and Algorithmic Information Theory (AIT) by proving two fundamental results: (1) the training process computationally approximates Solomonoff prior through loss minimization interpreted as program length optimization, and (2) next-token prediction implements approximate Solomonoff induction. We leverage AIT to provide a unified theoretical explanation for in-context learning, few-shot learning, and scaling laws. Furthermore, our theoretical insights lead to a principled method for few-shot example selection that prioritizes samples where models exhibit lower predictive confidence. We demonstrate through experiments on diverse text classification benchmarks that this strategy yields significant performance improvements, particularly for smaller model architectures, when compared to selecting high-confidence examples. Our framework bridges the gap between theoretical foundations and practical LLM behaviors, providing both explanatory power and actionable insights for future model development.
a1: Steep Test-time Scaling Law via Environment Augmented Generation
Apr 20, 2025Large Language Models (LLMs) have made remarkable breakthroughs in reasoning, yet continue to struggle with hallucinations, logical errors, and inability to self-correct during complex multi-step tasks. Current approaches like chain-of-thought prompting offer limited reasoning capabilities that fail when precise step validation is required. We propose Environment Augmented Generation (EAG), a framework that enhances LLM reasoning through: (1) real-time environmental feedback validating each reasoning step, (2) dynamic branch exploration for investigating alternative solution paths when faced with errors, and (3) experience-based learning from successful reasoning trajectories. Unlike existing methods, EAG enables deliberate backtracking and strategic replanning through tight integration of execution feedback with branching exploration. Our a1-32B model achieves state-of-the-art performance among similar-sized models across all benchmarks, matching larger models like o1 on competition mathematics while outperforming comparable models by up to 24.4 percentage points. Analysis reveals EAG's distinctive scaling pattern: initial token investment in environment interaction yields substantial long-term performance dividends, with advantages amplifying proportionally to task complexity. EAG's theoretical framework demonstrates how environment interactivity and systematic branch exploration together establish a new paradigm for reliable machine reasoning, particularly for problems requiring precise multi-step calculation and logical verification.
Innate Reasoning is Not Enough: In-Context Learning Enhances Reasoning Large Language Models with Less Overthinking
Mar 25, 2025
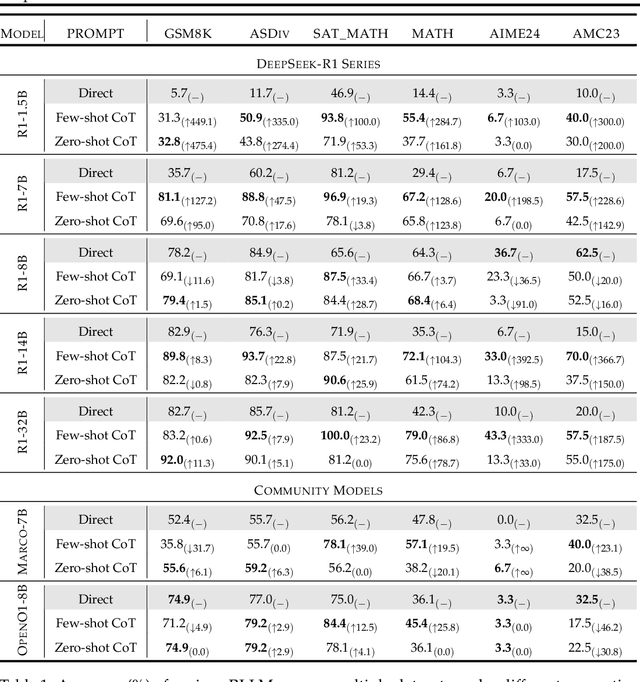
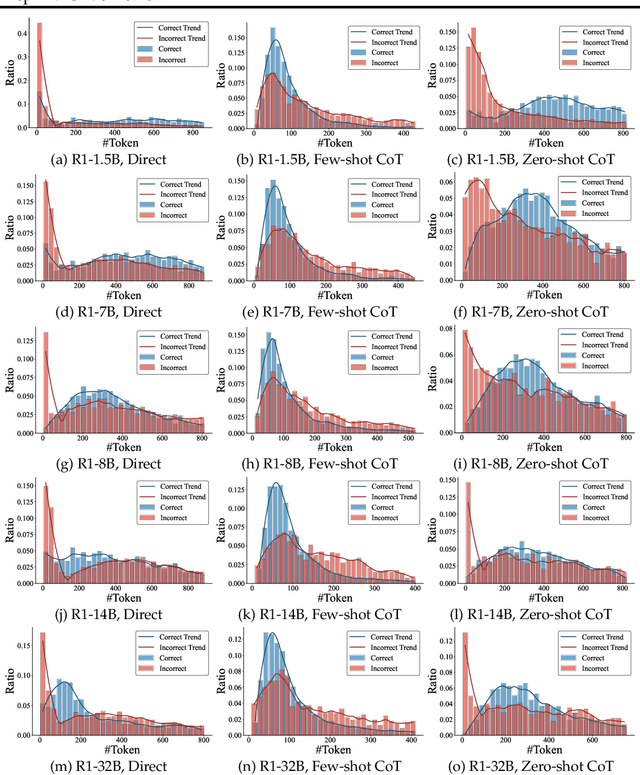
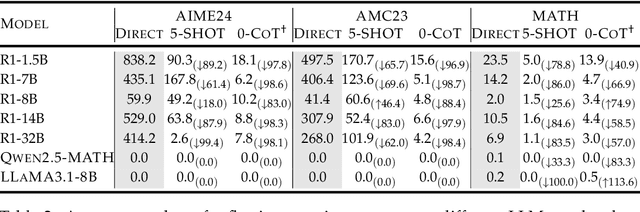
Recent advances in Large Language Models (LLMs) have introduced Reasoning Large Language Models (RLLMs), which employ extended thinking processes with reflection and self-correction capabilities, demonstrating the effectiveness of test-time scaling. RLLMs exhibit innate Chain-of-Thought (CoT) reasoning capability obtained from training, leading to a natural question: "Is CoT prompting, a popular In-Context Learning (ICL) method for chat LLMs, necessary to enhance the reasoning capability of RLLMs?" In this work, we present the first comprehensive analysis of the impacts of Zero-shot CoT and Few-shot CoT on RLLMs across mathematical reasoning tasks. We examine models ranging from 1.5B to 32B parameters, finding that contrary to concerns, CoT prompting significantly enhances RLLMs' performance in most scenarios. Our results reveal distinct patterns: large-capacity models show minimal improvement on simple tasks but substantial gains on complex problems, while smaller models exhibit the opposite behavior. Further analysis demonstrates that CoT prompting effectively controls the distribution of the numbers of thinking tokens and reasoning steps, reducing excessive reflections by approximately 90% in some cases. Moreover, attention logits analysis reveals the RLLMs' overfitting to reflection-related words, which is mitigated by external CoT guidance. Notably, our experiments indicate that for RLLMs, one-shot CoT consistently yields superior performance compared to Few-shot CoT approaches. Our findings provide important insights for optimizing RLLMs' performance through appropriate prompting strategies.
Parameters vs. Context: Fine-Grained Control of Knowledge Reliance in Language Models
Mar 20, 2025



Retrieval-Augmented Generation (RAG) mitigates hallucinations in Large Language Models (LLMs) by integrating external knowledge. However, conflicts between parametric knowledge and retrieved context pose challenges, particularly when retrieved information is unreliable or the model's internal knowledge is outdated. In such cases, LLMs struggle to determine whether to rely more on their own parameters or the conflicted context. To address this, we propose **CK-PLUG**, a plug-and-play method for controlling LLMs' reliance on parametric and contextual knowledge. We introduce a novel knowledge consistency metric, Confidence Gain, which detects knowledge conflicts by measuring entropy shifts in token probability distributions after context insertion. CK-PLUG then enables fine-grained control over knowledge preference by adjusting the probability distribution of tokens with negative confidence gain through a single tuning parameter. Experiments demonstrate CK-PLUG's ability to significantly regulate knowledge reliance in counterfactual RAG scenarios while maintaining generation fluency and knowledge accuracy. For instance, on Llama3-8B, memory recall (MR) of RAG response can be adjusted within a broad range (9.9%-71.9%), compared to the baseline of 42.1%. Moreover, CK-PLUG supports adaptive control based on the model's confidence in both internal and external knowledge, achieving consistent performance improvements across various general RAG tasks. Our code is available at: $\href{https://github.com/byronBBL/CK-PLUG}{\text{this https URL}}$.