 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMnemis: Dual-Route Retrieval on Hierarchical Graphs for Long-Term LLM Memory
Feb 17, 2026AI Memory, specifically how models organizes and retrieves historical messages, becomes increasingly valuable to Large Language Models (LLMs), yet existing methods (RAG and Graph-RAG) primarily retrieve memory through similarity-based mechanisms. While efficient, such System-1-style retrieval struggles with scenarios that require global reasoning or comprehensive coverage of all relevant information. In this work, We propose Mnemis, a novel memory framework that integrates System-1 similarity search with a complementary System-2 mechanism, termed Global Selection. Mnemis organizes memory into a base graph for similarity retrieval and a hierarchical graph that enables top-down, deliberate traversal over semantic hierarchies. By combining the complementary strength from both retrieval routes, Mnemis retrieves memory items that are both semantically and structurally relevant. Mnemis achieves state-of-the-art performance across all compared methods on long-term memory benchmarks, scoring 93.9 on LoCoMo and 91.6 on LongMemEval-S using GPT-4.1-mini.
Context-DPO: Aligning Language Models for Context-Faithfulness
Dec 18, 2024



Reliable responses from large language models (LLMs) require adherence to user instructions and retrieved information. While alignment techniques help LLMs align with human intentions and values, improving context-faithfulness through alignment remains underexplored. To address this, we propose $\textbf{Context-DPO}$, the first alignment method specifically designed to enhance LLMs' context-faithfulness. We introduce $\textbf{ConFiQA}$, a benchmark that simulates Retrieval-Augmented Generation (RAG) scenarios with knowledge conflicts to evaluate context-faithfulness. By leveraging faithful and stubborn responses to questions with provided context from ConFiQA, our Context-DPO aligns LLMs through direct preference optimization. Extensive experiments demonstrate that our Context-DPO significantly improves context-faithfulness, achieving 35% to 280% improvements on popular open-source models. Further analysis demonstrates that Context-DPO preserves LLMs' generative capabilities while providing interpretable insights into context utilization. Our code and data are released at https://github.com/byronBBL/Context-DPO
E5-V: Universal Embeddings with Multimodal Large Language Models
Jul 17, 2024Multimodal large language models (MLLMs) have shown promising advancements in general visual and language understanding. However, the representation of multimodal information using MLLMs remains largely unexplored. In this work, we introduce a new framework, E5-V, designed to adapt MLLMs for achieving universal multimodal embeddings. Our findings highlight the significant potential of MLLMs in representing multimodal inputs compared to previous approaches. By leveraging MLLMs with prompts, E5-V effectively bridges the modality gap between different types of inputs, demonstrating strong performance in multimodal embeddings even without fine-tuning. We propose a single modality training approach for E5-V, where the model is trained exclusively on text pairs. This method demonstrates significant improvements over traditional multimodal training on image-text pairs, while reducing training costs by approximately 95%. Additionally, this approach eliminates the need for costly multimodal training data collection. Extensive experiments across four types of tasks demonstrate the effectiveness of E5-V. As a universal multimodal model, E5-V not only achieves but often surpasses state-of-the-art performance in each task, despite being trained on a single modality.
ASI++: Towards Distributionally Balanced End-to-End Generative Retrieval
May 23, 2024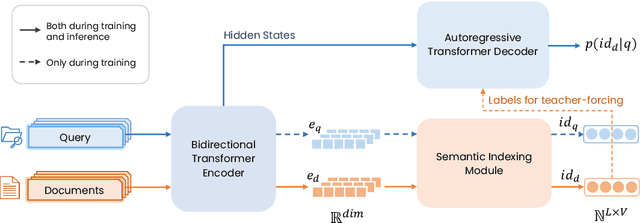



Generative retrieval, a promising new paradigm in information retrieval, employs a seq2seq model to encode document features into parameters and decode relevant document identifiers (IDs) based on search queries. Existing generative retrieval solutions typically rely on a preprocessing stage to pre-define document IDs, which can suffer from a semantic gap between these IDs and the retrieval task. However, end-to-end training for both ID assignments and retrieval tasks is challenging due to the long-tailed distribution characteristics of real-world data, resulting in inefficient and unbalanced ID space utilization. To address these issues, we propose ASI++, a novel fully end-to-end generative retrieval method that aims to simultaneously learn balanced ID assignments and improve retrieval performance. ASI++ builds on the fully end-to-end training framework of vanilla ASI and introduces several key innovations. First, a distributionally balanced criterion addresses the imbalance in ID assignments, promoting more efficient utilization of the ID space. Next, a representation bottleneck criterion enhances dense representations to alleviate bottlenecks in learning ID assignments. Finally, an information consistency criterion integrates these processes into a joint optimization framework grounded in information theory. We further explore various module structures for learning ID assignments, including neural quantization, differentiable product quantization, and residual quantization. Extensive experiments on both public and industrial datasets demonstrate the effectiveness of ASI++ in improving retrieval performance and achieving balanced ID assignments.
MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning
May 20, 2024



Low-rank adaptation is a popular parameter-efficient fine-tuning method for large language models. In this paper, we analyze the impact of low-rank updating, as implemented in LoRA. Our findings suggest that the low-rank updating mechanism may limit the ability of LLMs to effectively learn and memorize new knowledge. Inspired by this observation, we propose a new method called MoRA, which employs a square matrix to achieve high-rank updating while maintaining the same number of trainable parameters. To achieve it, we introduce the corresponding non-parameter operators to reduce the input dimension and increase the output dimension for the square matrix. Furthermore, these operators ensure that the weight can be merged back into LLMs, which makes our method can be deployed like LoRA. We perform a comprehensive evaluation of our method across five tasks: instruction tuning, mathematical reasoning, continual pretraining, memory and pretraining. Our method outperforms LoRA on memory-intensive tasks and achieves comparable performance on other tasks.
ResLoRA: Identity Residual Mapping in Low-Rank Adaption
Feb 28, 2024



As one of the most popular parameter-efficient fine-tuning (PEFT) methods, low-rank adaptation (LoRA) is commonly applied to fine-tune large language models (LLMs). However, updating the weights of LoRA blocks effectively and expeditiously is challenging due to the long calculation path in the original model. To address this, we propose ResLoRA, an improved framework of LoRA. By adding residual paths during training and using merging approaches to eliminate these extra paths during inference, our method can achieve better results in fewer training steps without any extra trainable parameters or inference cost compared to LoRA. The experiments on NLG, NLU, and text-to-image tasks demonstrate the effectiveness of our method. To the best of our knowledge, ResLoRA is the first work that combines the residual path with LoRA. The code of our method is available at https://github.com/microsoft/LMOps/tree/main/reslora .
HD-Eval: Aligning Large Language Model Evaluators Through Hierarchical Criteria Decomposition
Feb 24, 2024



Large language models (LLMs) have emerged as a promising alternative to expensive human evaluations. However, the alignment and coverage of LLM-based evaluations are often limited by the scope and potential bias of the evaluation prompts and criteria. To address this challenge, we propose HD-Eval, a novel framework that iteratively aligns LLM-based evaluators with human preference via Hierarchical Criteria Decomposition. HD-Eval inherits the essence from the evaluation mindset of human experts and enhances the alignment of LLM-based evaluators by decomposing a given evaluation task into finer-grained criteria, aggregating them according to estimated human preferences, pruning insignificant criteria with attribution, and further decomposing significant criteria. By integrating these steps within an iterative alignment training process, we obtain a hierarchical decomposition of criteria that comprehensively captures aspects of natural language at multiple levels of granularity. Implemented as a white box, the human preference-guided aggregator is efficient to train and more explainable than relying solely on prompting, and its independence from model parameters makes it applicable to closed-source LLMs. Extensive experiments on three evaluation domains demonstrate the superiority of HD-Eval in further aligning state-of-the-art evaluators and providing deeper insights into the explanation of evaluation results and the task itself.
Text Diffusion with Reinforced Conditioning
Feb 19, 2024



Diffusion models have demonstrated exceptional capability in generating high-quality images, videos, and audio. Due to their adaptiveness in iterative refinement, they provide a strong potential for achieving better non-autoregressive sequence generation. However, existing text diffusion models still fall short in their performance due to a challenge in handling the discreteness of language. This paper thoroughly analyzes text diffusion models and uncovers two significant limitations: degradation of self-conditioning during training and misalignment between training and sampling. Motivated by our findings, we propose a novel Text Diffusion model called TREC, which mitigates the degradation with Reinforced Conditioning and the misalignment by Time-Aware Variance Scaling. Our extensive experiments demonstrate the competitiveness of TREC against autoregressive, non-autoregressive, and diffusion baselines. Moreover, qualitative analysis shows its advanced ability to fully utilize the diffusion process in refining samples.
Improving Domain Adaptation through Extended-Text Reading Comprehension
Jan 18, 2024



To enhance the domain-specific capabilities of large language models, continued pre-training on a domain-specific corpus is a prevalent method. Recent work demonstrates that adapting models using reading comprehension data formatted by regex-based patterns can significantly improve performance on domain-specific tasks. However, regex-based patterns are incapable of parsing raw corpora using domain-specific knowledge. Furthermore, the question and answer pairs are extracted directly from the corpus in predefined formats offers limited context. To address this limitation, we improve reading comprehension via LLM and clustering. LLM focuses on leveraging domain knowledge within the corpus to refine comprehension stage, while clustering supplies relevant knowledge by extending the context to enrich reading stage. Additionally, our method incorporates parameter-efficient fine-tuning to improve the efficiency of domain adaptation. In comparison to AdaptLLM, our method achieves an improvement exceeding 5% in domain-specific tasks. Our code will available at https://github.com/microsoft/LMOps.
Auto Search Indexer for End-to-End Document Retrieval
Oct 30, 2023



Generative retrieval, which is a new advanced paradigm for document retrieval, has recently attracted research interests, since it encodes all documents into the model and directly generates the retrieved documents. However, its power is still underutilized since it heavily relies on the "preprocessed" document identifiers (docids), thus limiting its retrieval performance and ability to retrieve new documents. In this paper, we propose a novel fully end-to-end retrieval paradigm. It can not only end-to-end learn the best docids for existing and new documents automatically via a semantic indexing module, but also perform end-to-end document retrieval via an encoder-decoder-based generative model, namely Auto Search Indexer (ASI). Besides, we design a reparameterization mechanism to combine the above two modules into a joint optimization framework. Extensive experimental results demonstrate the superiority of our model over advanced baselines on both public and industrial datasets and also verify the ability to deal with new documents.