 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-DPO: Aligning Language Models for Context-Faithfulness
Dec 18, 2024



Reliable responses from large language models (LLMs) require adherence to user instructions and retrieved information. While alignment techniques help LLMs align with human intentions and values, improving context-faithfulness through alignment remains underexplored. To address this, we propose $\textbf{Context-DPO}$, the first alignment method specifically designed to enhance LLMs' context-faithfulness. We introduce $\textbf{ConFiQA}$, a benchmark that simulates Retrieval-Augmented Generation (RAG) scenarios with knowledge conflicts to evaluate context-faithfulness. By leveraging faithful and stubborn responses to questions with provided context from ConFiQA, our Context-DPO aligns LLMs through direct preference optimization. Extensive experiments demonstrate that our Context-DPO significantly improves context-faithfulness, achieving 35% to 280% improvements on popular open-source models. Further analysis demonstrates that Context-DPO preserves LLMs' generative capabilities while providing interpretable insights into context utilization. Our code and data are released at https://github.com/byronBBL/Context-DPO
ASI++: Towards Distributionally Balanced End-to-End Generative Retrieval
May 23, 2024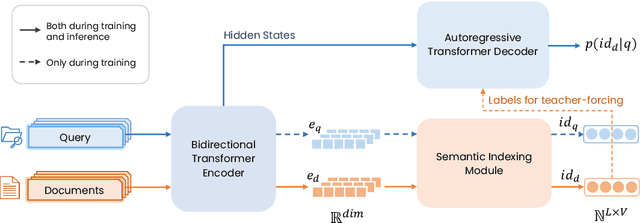



Generative retrieval, a promising new paradigm in information retrieval, employs a seq2seq model to encode document features into parameters and decode relevant document identifiers (IDs) based on search queries. Existing generative retrieval solutions typically rely on a preprocessing stage to pre-define document IDs, which can suffer from a semantic gap between these IDs and the retrieval task. However, end-to-end training for both ID assignments and retrieval tasks is challenging due to the long-tailed distribution characteristics of real-world data, resulting in inefficient and unbalanced ID space utilization. To address these issues, we propose ASI++, a novel fully end-to-end generative retrieval method that aims to simultaneously learn balanced ID assignments and improve retrieval performance. ASI++ builds on the fully end-to-end training framework of vanilla ASI and introduces several key innovations. First, a distributionally balanced criterion addresses the imbalance in ID assignments, promoting more efficient utilization of the ID space. Next, a representation bottleneck criterion enhances dense representations to alleviate bottlenecks in learning ID assignments. Finally, an information consistency criterion integrates these processes into a joint optimization framework grounded in information theory. We further explore various module structures for learning ID assignments, including neural quantization, differentiable product quantization, and residual quantization. Extensive experiments on both public and industrial datasets demonstrate the effectiveness of ASI++ in improving retrieval performance and achieving balanced ID assignments.
Minimum Topology Attacks for Graph Neural Networks
Mar 05, 2024



With the great popularity of Graph Neural Networks (GNNs), their robustness to adversarial topology attacks has received significant attention. Although many attack methods have been proposed, they mainly focus on fixed-budget attacks, aiming at finding the most adversarial perturbations within a fixed budget for target node. However, considering the varied robustness of each node, there is an inevitable dilemma caused by the fixed budget, i.e., no successful perturbation is found when the budget is relatively small, while if it is too large, the yielding redundant perturbations will hurt the invisibility. To break this dilemma, we propose a new type of topology attack, named minimum-budget topology attack, aiming to adaptively find the minimum perturbation sufficient for a successful attack on each node. To this end, we propose an attack model, named MiBTack, based on a dynamic projected gradient descent algorithm, which can effectively solve the involving non-convex constraint optimization on discrete topology. Extensive results on three GNNs and four real-world datasets show that MiBTack can successfully lead all target nodes misclassified with the minimum perturbation edges. Moreover, the obtained minimum budget can be used to measure node robustness, so we can explore the relationships of robustness, topology, and uncertainty for nodes, which is beyond what the current fixed-budget topology attacks can offer.
HD-Eval: Aligning Large Language Model Evaluators Through Hierarchical Criteria Decomposition
Feb 24, 2024



Large language models (LLMs) have emerged as a promising alternative to expensive human evaluations. However, the alignment and coverage of LLM-based evaluations are often limited by the scope and potential bias of the evaluation prompts and criteria. To address this challenge, we propose HD-Eval, a novel framework that iteratively aligns LLM-based evaluators with human preference via Hierarchical Criteria Decomposition. HD-Eval inherits the essence from the evaluation mindset of human experts and enhances the alignment of LLM-based evaluators by decomposing a given evaluation task into finer-grained criteria, aggregating them according to estimated human preferences, pruning insignificant criteria with attribution, and further decomposing significant criteria. By integrating these steps within an iterative alignment training process, we obtain a hierarchical decomposition of criteria that comprehensively captures aspects of natural language at multiple levels of granularity. Implemented as a white box, the human preference-guided aggregator is efficient to train and more explainable than relying solely on prompting, and its independence from model parameters makes it applicable to closed-source LLMs. Extensive experiments on three evaluation domains demonstrate the superiority of HD-Eval in further aligning state-of-the-art evaluators and providing deeper insights into the explanation of evaluation results and the task itself.
Text Diffusion with Reinforced Conditioning
Feb 19, 2024



Diffusion models have demonstrated exceptional capability in generating high-quality images, videos, and audio. Due to their adaptiveness in iterative refinement, they provide a strong potential for achieving better non-autoregressive sequence generation. However, existing text diffusion models still fall short in their performance due to a challenge in handling the discreteness of language. This paper thoroughly analyzes text diffusion models and uncovers two significant limitations: degradation of self-conditioning during training and misalignment between training and sampling. Motivated by our findings, we propose a novel Text Diffusion model called TREC, which mitigates the degradation with Reinforced Conditioning and the misalignment by Time-Aware Variance Scaling. Our extensive experiments demonstrate the competitiveness of TREC against autoregressive, non-autoregressive, and diffusion baselines. Moreover, qualitative analysis shows its advanced ability to fully utilize the diffusion process in refining samples.
Auto Search Indexer for End-to-End Document Retrieval
Oct 30, 2023



Generative retrieval, which is a new advanced paradigm for document retrieval, has recently attracted research interests, since it encodes all documents into the model and directly generates the retrieved documents. However, its power is still underutilized since it heavily relies on the "preprocessed" document identifiers (docids), thus limiting its retrieval performance and ability to retrieve new documents. In this paper, we propose a novel fully end-to-end retrieval paradigm. It can not only end-to-end learn the best docids for existing and new documents automatically via a semantic indexing module, but also perform end-to-end document retrieval via an encoder-decoder-based generative model, namely Auto Search Indexer (ASI). Besides, we design a reparameterization mechanism to combine the above two modules into a joint optimization framework. Extensive experimental results demonstrate the superiority of our model over advanced baselines on both public and industrial datasets and also verify the ability to deal with new documents.
Calibrating LLM-Based Evaluator
Sep 23, 2023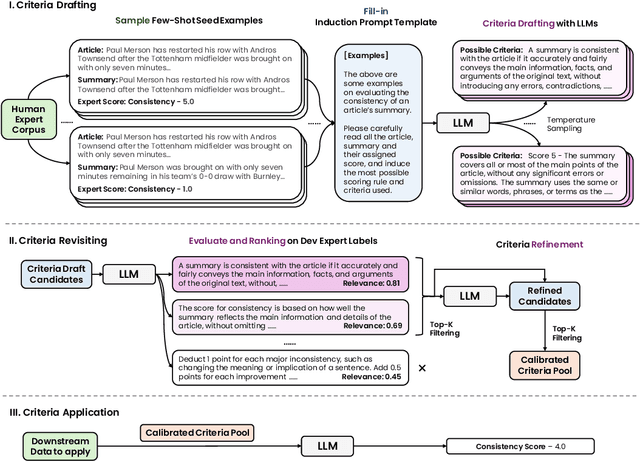
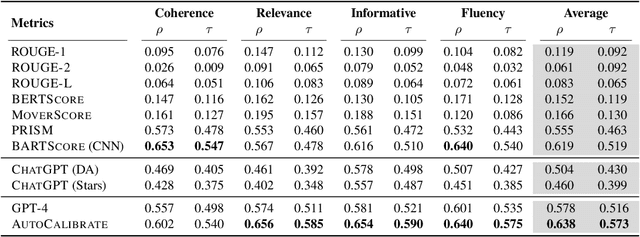

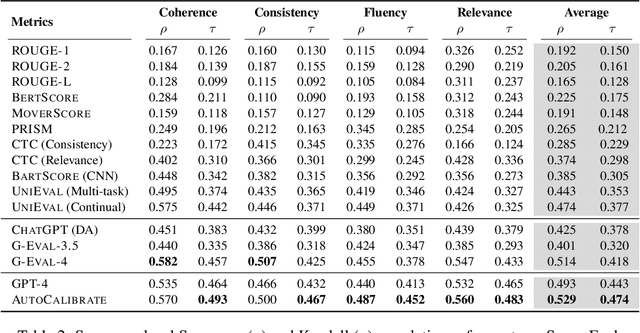
Recent advancements in large language models (LLMs) on language modeling and emergent capabilities make them a promising reference-free evaluator of natural language generation quality, and a competent alternative to human evaluation. However, hindered by the closed-source or high computational demand to host and tune, there is a lack of practice to further calibrate an off-the-shelf LLM-based evaluator towards better human alignment. In this work, we propose AutoCalibrate, a multi-stage, gradient-free approach to automatically calibrate and align an LLM-based evaluator toward human preference. Instead of explicitly modeling human preferences, we first implicitly encompass them within a set of human labels. Then, an initial set of scoring criteria is drafted by the language model itself, leveraging in-context learning on different few-shot examples. To further calibrate this set of criteria, we select the best performers and re-draft them with self-refinement. Our experiments on multiple text quality evaluation datasets illustrate a significant improvement in correlation with expert evaluation through calibration. Our comprehensive qualitative analysis conveys insightful intuitions and observations on the essence of effective scoring criteria.