 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE5-V: Universal Embeddings with Multimodal Large Language Models
Jul 17, 2024Multimodal large language models (MLLMs) have shown promising advancements in general visual and language understanding. However, the representation of multimodal information using MLLMs remains largely unexplored. In this work, we introduce a new framework, E5-V, designed to adapt MLLMs for achieving universal multimodal embeddings. Our findings highlight the significant potential of MLLMs in representing multimodal inputs compared to previous approaches. By leveraging MLLMs with prompts, E5-V effectively bridges the modality gap between different types of inputs, demonstrating strong performance in multimodal embeddings even without fine-tuning. We propose a single modality training approach for E5-V, where the model is trained exclusively on text pairs. This method demonstrates significant improvements over traditional multimodal training on image-text pairs, while reducing training costs by approximately 95%. Additionally, this approach eliminates the need for costly multimodal training data collection. Extensive experiments across four types of tasks demonstrate the effectiveness of E5-V. As a universal multimodal model, E5-V not only achieves but often surpasses state-of-the-art performance in each task, despite being trained on a single modality.
ASI++: Towards Distributionally Balanced End-to-End Generative Retrieval
May 23, 2024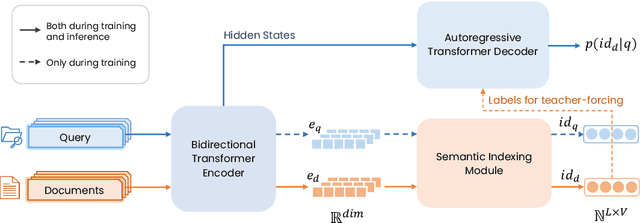



Generative retrieval, a promising new paradigm in information retrieval, employs a seq2seq model to encode document features into parameters and decode relevant document identifiers (IDs) based on search queries. Existing generative retrieval solutions typically rely on a preprocessing stage to pre-define document IDs, which can suffer from a semantic gap between these IDs and the retrieval task. However, end-to-end training for both ID assignments and retrieval tasks is challenging due to the long-tailed distribution characteristics of real-world data, resulting in inefficient and unbalanced ID space utilization. To address these issues, we propose ASI++, a novel fully end-to-end generative retrieval method that aims to simultaneously learn balanced ID assignments and improve retrieval performance. ASI++ builds on the fully end-to-end training framework of vanilla ASI and introduces several key innovations. First, a distributionally balanced criterion addresses the imbalance in ID assignments, promoting more efficient utilization of the ID space. Next, a representation bottleneck criterion enhances dense representations to alleviate bottlenecks in learning ID assignments. Finally, an information consistency criterion integrates these processes into a joint optimization framework grounded in information theory. We further explore various module structures for learning ID assignments, including neural quantization, differentiable product quantization, and residual quantization. Extensive experiments on both public and industrial datasets demonstrate the effectiveness of ASI++ in improving retrieval performance and achieving balanced ID assignments.
ResLoRA: Identity Residual Mapping in Low-Rank Adaption
Feb 28, 2024



As one of the most popular parameter-efficient fine-tuning (PEFT) methods, low-rank adaptation (LoRA) is commonly applied to fine-tune large language models (LLMs). However, updating the weights of LoRA blocks effectively and expeditiously is challenging due to the long calculation path in the original model. To address this, we propose ResLoRA, an improved framework of LoRA. By adding residual paths during training and using merging approaches to eliminate these extra paths during inference, our method can achieve better results in fewer training steps without any extra trainable parameters or inference cost compared to LoRA. The experiments on NLG, NLU, and text-to-image tasks demonstrate the effectiveness of our method. To the best of our knowledge, ResLoRA is the first work that combines the residual path with LoRA. The code of our method is available at https://github.com/microsoft/LMOps/tree/main/reslora .
Auto Search Indexer for End-to-End Document Retrieval
Oct 30, 2023



Generative retrieval, which is a new advanced paradigm for document retrieval, has recently attracted research interests, since it encodes all documents into the model and directly generates the retrieved documents. However, its power is still underutilized since it heavily relies on the "preprocessed" document identifiers (docids), thus limiting its retrieval performance and ability to retrieve new documents. In this paper, we propose a novel fully end-to-end retrieval paradigm. It can not only end-to-end learn the best docids for existing and new documents automatically via a semantic indexing module, but also perform end-to-end document retrieval via an encoder-decoder-based generative model, namely Auto Search Indexer (ASI). Besides, we design a reparameterization mechanism to combine the above two modules into a joint optimization framework. Extensive experimental results demonstrate the superiority of our model over advanced baselines on both public and industrial datasets and also verify the ability to deal with new documents.
Democratizing Reasoning Ability: Tailored Learning from Large Language Model
Oct 20, 2023



Large language models (LLMs) exhibit impressive emergent abilities in natural language processing, but their democratization is hindered due to huge computation requirements and closed-source nature. Recent research on advancing open-source smaller LMs by distilling knowledge from black-box LLMs has obtained promising results in the instruction-following ability. However, the reasoning ability which is more challenging to foster, is relatively rarely explored. In this paper, we propose a tailored learning approach to distill such reasoning ability to smaller LMs to facilitate the democratization of the exclusive reasoning ability. In contrast to merely employing LLM as a data annotator, we exploit the potential of LLM as a reasoning teacher by building an interactive multi-round learning paradigm. This paradigm enables the student to expose its deficiencies to the black-box teacher who then can provide customized training data in return. Further, to exploit the reasoning potential of the smaller LM, we propose self-reflection learning to motivate the student to learn from self-made mistakes. The learning from self-reflection and LLM are all tailored to the student's learning status, thanks to the seamless integration with the multi-round learning paradigm. Comprehensive experiments and analysis on mathematical and commonsense reasoning tasks demonstrate the effectiveness of our method. The code will be available at https://github.com/Raibows/Learn-to-Reason.