 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSADA: Stability-guided Adaptive Diffusion Acceleration
Jul 23, 2025Diffusion models have achieved remarkable success in generative tasks but suffer from high computational costs due to their iterative sampling process and quadratic attention costs. Existing training-free acceleration strategies that reduce per-step computation cost, while effectively reducing sampling time, demonstrate low faithfulness compared to the original baseline. We hypothesize that this fidelity gap arises because (a) different prompts correspond to varying denoising trajectory, and (b) such methods do not consider the underlying ODE formulation and its numerical solution. In this paper, we propose Stability-guided Adaptive Diffusion Acceleration (SADA), a novel paradigm that unifies step-wise and token-wise sparsity decisions via a single stability criterion to accelerate sampling of ODE-based generative models (Diffusion and Flow-matching). For (a), SADA adaptively allocates sparsity based on the sampling trajectory. For (b), SADA introduces principled approximation schemes that leverage the precise gradient information from the numerical ODE solver. Comprehensive evaluations on SD-2, SDXL, and Flux using both EDM and DPM++ solvers reveal consistent $\ge 1.8\times$ speedups with minimal fidelity degradation (LPIPS $\leq 0.10$ and FID $\leq 4.5$) compared to unmodified baselines, significantly outperforming prior methods. Moreover, SADA adapts seamlessly to other pipelines and modalities: It accelerates ControlNet without any modifications and speeds up MusicLDM by $1.8\times$ with $\sim 0.01$ spectrogram LPIPS.
A Multi-Scale Spatial-Temporal Network for Wireless Video Transmission
Nov 15, 2024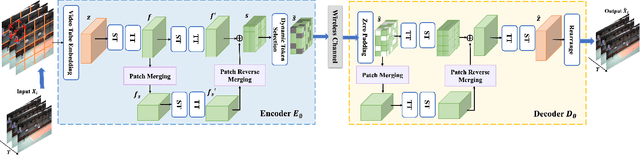
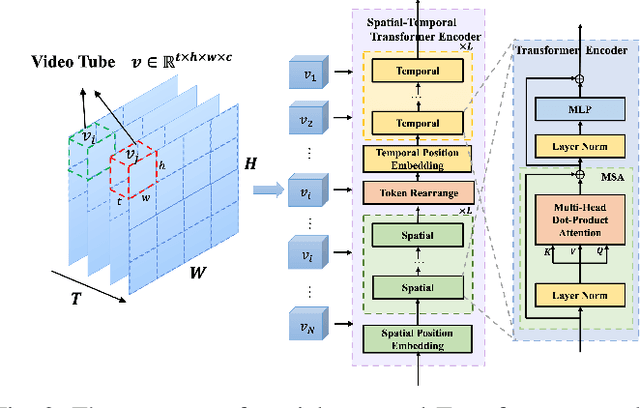
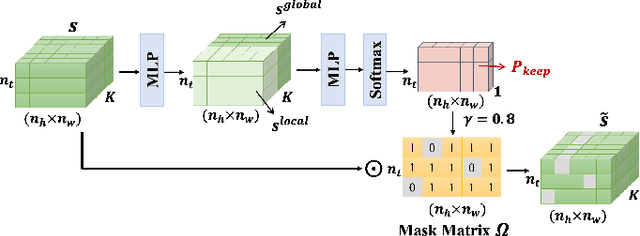
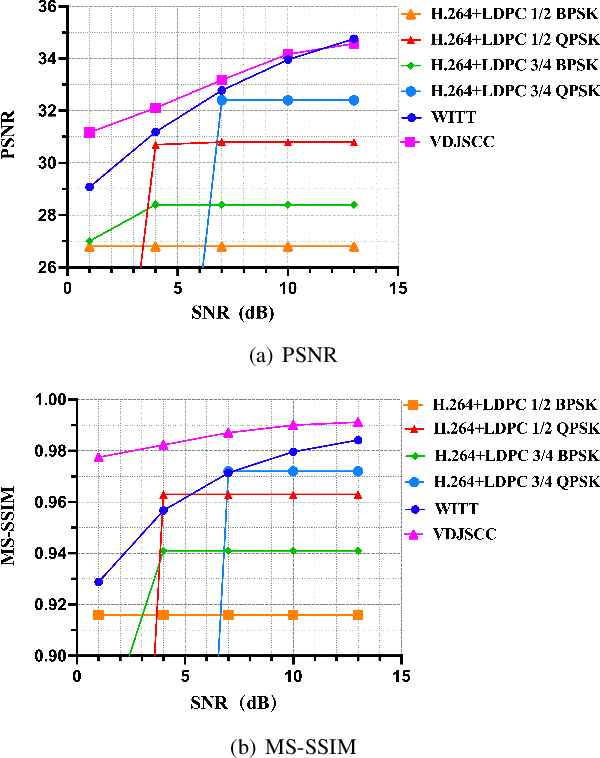
Deep joint source-channel coding (DeepJSCC) has shown promise in wireless transmission of text, speech, and images within the realm of semantic communication. However, wireless video transmission presents greater challenges due to the difficulty of extracting and compactly representing both spatial and temporal features, as well as its significant bandwidth and computational resource requirements. In response, we propose a novel video DeepJSCC (VDJSCC) approach to enable end-to-end video transmission over a wireless channel. Our approach involves the design of a multi-scale vision Transformer encoder and decoder to effectively capture spatial-temporal representations over long-term frames. Additionally, we propose a dynamic token selection module to mask less semantically important tokens from spatial or temporal dimensions, allowing for content-adaptive variable-length video coding by adjusting the token keep ratio. Experimental results demonstrate the effectiveness of our VDJSCC approach compared to digital schemes that use separate source and channel codes, as well as other DeepJSCC schemes, in terms of reconstruction quality and bandwidth reduction.
Efficient Single Image Super-Resolution with Entropy Attention and Receptive Field Augmentation
Aug 08, 2024
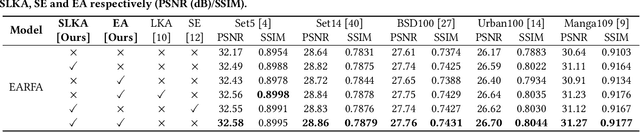

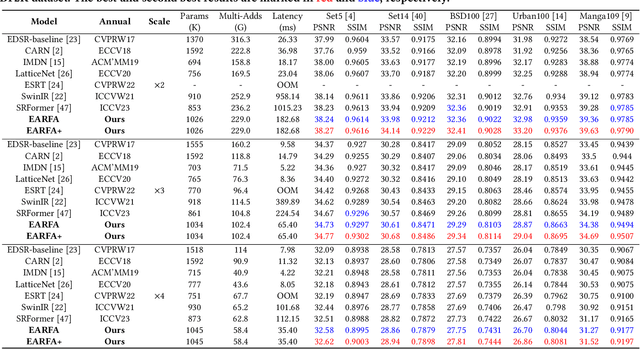
Transformer-based deep models for single image super-resolution (SISR) have greatly improved the performance of lightweight SISR tasks in recent years. However, they often suffer from heavy computational burden and slow inference due to the complex calculation of multi-head self-attention (MSA), seriously hindering their practical application and deployment. In this work, we present an efficient SR model to mitigate the dilemma between model efficiency and SR performance, which is dubbed Entropy Attention and Receptive Field Augmentation network (EARFA), and composed of a novel entropy attention (EA) and a shifting large kernel attention (SLKA). From the perspective of information theory, EA increases the entropy of intermediate features conditioned on a Gaussian distribution, providing more informative input for subsequent reasoning. On the other hand, SLKA extends the receptive field of SR models with the assistance of channel shifting, which also favors to boost the diversity of hierarchical features. Since the implementation of EA and SLKA does not involve complex computations (such as extensive matrix multiplications), the proposed method can achieve faster nonlinear inference than Transformer-based SR models while maintaining better SR performance. Extensive experiments show that the proposed model can significantly reduce the delay of model inference while achieving the SR performance comparable with other advanced models.
Diff-Shadow: Global-guided Diffusion Model for Shadow Removal
Jul 23, 2024



We propose Diff-Shadow, a global-guided diffusion model for high-quality shadow removal. Previous transformer-based approaches can utilize global information to relate shadow and non-shadow regions but are limited in their synthesis ability and recover images with obvious boundaries. In contrast, diffusion-based methods can generate better content but ignore global information, resulting in inconsistent illumination. In this work, we combine the advantages of diffusion models and global guidance to realize shadow-free restoration. Specifically, we propose a parallel UNets architecture: 1) the local branch performs the patch-based noise estimation in the diffusion process, and 2) the global branch recovers the low-resolution shadow-free images. A Reweight Cross Attention (RCA) module is designed to integrate global contextural information of non-shadow regions into the local branch. We further design a Global-guided Sampling Strategy (GSS) that mitigates patch boundary issues and ensures consistent illumination across shaded and unshaded regions in the recovered image. Comprehensive experiments on three publicly standard datasets ISTD, ISTD+, and SRD have demonstrated the effectiveness of Diff-Shadow. Compared to state-of-the-art methods, our method achieves a significant improvement in terms of PSNR, increasing from 32.33dB to 33.69dB on the SRD dataset. Codes will be released.
E5-V: Universal Embeddings with Multimodal Large Language Models
Jul 17, 2024Multimodal large language models (MLLMs) have shown promising advancements in general visual and language understanding. However, the representation of multimodal information using MLLMs remains largely unexplored. In this work, we introduce a new framework, E5-V, designed to adapt MLLMs for achieving universal multimodal embeddings. Our findings highlight the significant potential of MLLMs in representing multimodal inputs compared to previous approaches. By leveraging MLLMs with prompts, E5-V effectively bridges the modality gap between different types of inputs, demonstrating strong performance in multimodal embeddings even without fine-tuning. We propose a single modality training approach for E5-V, where the model is trained exclusively on text pairs. This method demonstrates significant improvements over traditional multimodal training on image-text pairs, while reducing training costs by approximately 95%. Additionally, this approach eliminates the need for costly multimodal training data collection. Extensive experiments across four types of tasks demonstrate the effectiveness of E5-V. As a universal multimodal model, E5-V not only achieves but often surpasses state-of-the-art performance in each task, despite being trained on a single modality.
MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning
May 20, 2024



Low-rank adaptation is a popular parameter-efficient fine-tuning method for large language models. In this paper, we analyze the impact of low-rank updating, as implemented in LoRA. Our findings suggest that the low-rank updating mechanism may limit the ability of LLMs to effectively learn and memorize new knowledge. Inspired by this observation, we propose a new method called MoRA, which employs a square matrix to achieve high-rank updating while maintaining the same number of trainable parameters. To achieve it, we introduce the corresponding non-parameter operators to reduce the input dimension and increase the output dimension for the square matrix. Furthermore, these operators ensure that the weight can be merged back into LLMs, which makes our method can be deployed like LoRA. We perform a comprehensive evaluation of our method across five tasks: instruction tuning, mathematical reasoning, continual pretraining, memory and pretraining. Our method outperforms LoRA on memory-intensive tasks and achieves comparable performance on other tasks.
Improving Bracket Image Restoration and Enhancement with Flow-guided Alignment and Enhanced Feature Aggregation
Apr 16, 2024


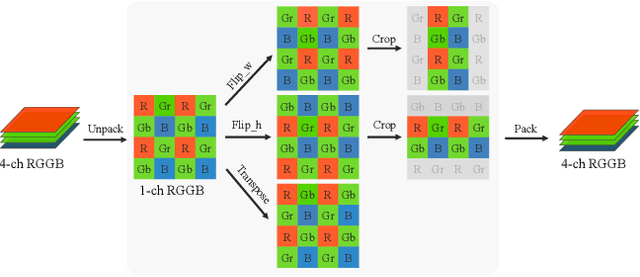
In this paper, we address the Bracket Image Restoration and Enhancement (BracketIRE) task using a novel framework, which requires restoring a high-quality high dynamic range (HDR) image from a sequence of noisy, blurred, and low dynamic range (LDR) multi-exposure RAW inputs. To overcome this challenge, we present the IREANet, which improves the multiple exposure alignment and aggregation with a Flow-guide Feature Alignment Module (FFAM) and an Enhanced Feature Aggregation Module (EFAM). Specifically, the proposed FFAM incorporates the inter-frame optical flow as guidance to facilitate the deformable alignment and spatial attention modules for better feature alignment. The EFAM further employs the proposed Enhanced Residual Block (ERB) as a foundational component, wherein a unidirectional recurrent network aggregates the aligned temporal features to better reconstruct the results. To improve model generalization and performance, we additionally employ the Bayer preserving augmentation (BayerAug) strategy to augment the multi-exposure RAW inputs. Our experimental evaluations demonstrate that the proposed IREANet shows state-of-the-art performance compared with previous methods.
Improving Domain Adaptation through Extended-Text Reading Comprehension
Jan 18, 2024



To enhance the domain-specific capabilities of large language models, continued pre-training on a domain-specific corpus is a prevalent method. Recent work demonstrates that adapting models using reading comprehension data formatted by regex-based patterns can significantly improve performance on domain-specific tasks. However, regex-based patterns are incapable of parsing raw corpora using domain-specific knowledge. Furthermore, the question and answer pairs are extracted directly from the corpus in predefined formats offers limited context. To address this limitation, we improve reading comprehension via LLM and clustering. LLM focuses on leveraging domain knowledge within the corpus to refine comprehension stage, while clustering supplies relevant knowledge by extending the context to enrich reading stage. Additionally, our method incorporates parameter-efficient fine-tuning to improve the efficiency of domain adaptation. In comparison to AdaptLLM, our method achieves an improvement exceeding 5% in domain-specific tasks. Our code will available at https://github.com/microsoft/LMOps.
MEFLUT: Unsupervised 1D Lookup Tables for Multi-exposure Image Fusion
Sep 21, 2023In this paper, we introduce a new approach for high-quality multi-exposure image fusion (MEF). We show that the fusion weights of an exposure can be encoded into a 1D lookup table (LUT), which takes pixel intensity value as input and produces fusion weight as output. We learn one 1D LUT for each exposure, then all the pixels from different exposures can query 1D LUT of that exposure independently for high-quality and efficient fusion. Specifically, to learn these 1D LUTs, we involve attention mechanism in various dimensions including frame, channel and spatial ones into the MEF task so as to bring us significant quality improvement over the state-of-the-art (SOTA). In addition, we collect a new MEF dataset consisting of 960 samples, 155 of which are manually tuned by professionals as ground-truth for evaluation. Our network is trained by this dataset in an unsupervised manner. Extensive experiments are conducted to demonstrate the effectiveness of all the newly proposed components, and results show that our approach outperforms the SOTA in our and another representative dataset SICE, both qualitatively and quantitatively. Moreover, our 1D LUT approach takes less than 4ms to run a 4K image on a PC GPU. Given its high quality, efficiency and robustness, our method has been shipped into millions of Android mobiles across multiple brands world-wide. Code is available at: https://github.com/Hedlen/MEFLUT.
FrFT based estimation of linear and nonlinear impairments using Vision Transformer
Aug 25, 2023



To comprehensively assess optical fiber communication system conditions, it is essential to implement joint estimation of the following four critical impairments: nonlinear signal-to-noise ratio (SNRNL), optical signal-to-noise ratio (OSNR), chromatic dispersion (CD) and differential group delay (DGD). However, current studies only achieve identifying a limited number of impairments within a narrow range, due to limitations in network capabilities and lack of unified representation of impairments. To address these challenges, we adopt time-frequency signal processing based on fractional Fourier transform (FrFT) to achieve the unified representation of impairments, while employing a Transformer based neural networks (NN) to break through network performance limitations. To verify the effectiveness of the proposed estimation method, the numerical simulation is carried on a 5-channel polarization-division-multiplexed quadrature phase shift keying (PDM-QPSK) long haul optical transmission system with the symbol rate of 50 GBaud per channel, the mean absolute error (MAE) for SNRNL, OSNR, CD, and DGD estimation is 0.091 dB, 0.058 dB, 117 ps/nm, and 0.38 ps, and the monitoring window ranges from 0~20 dB, 10~30 dB, 0~51000 ps/nm, and 0~100 ps, respectively. Our proposed method achieves accurate estimation of linear and nonlinear impairments over a broad range, representing a significant advancement in the field of optical performance monitoring (OPM).