 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff-Shadow: Global-guided Diffusion Model for Shadow Removal
Jul 23, 2024



We propose Diff-Shadow, a global-guided diffusion model for high-quality shadow removal. Previous transformer-based approaches can utilize global information to relate shadow and non-shadow regions but are limited in their synthesis ability and recover images with obvious boundaries. In contrast, diffusion-based methods can generate better content but ignore global information, resulting in inconsistent illumination. In this work, we combine the advantages of diffusion models and global guidance to realize shadow-free restoration. Specifically, we propose a parallel UNets architecture: 1) the local branch performs the patch-based noise estimation in the diffusion process, and 2) the global branch recovers the low-resolution shadow-free images. A Reweight Cross Attention (RCA) module is designed to integrate global contextural information of non-shadow regions into the local branch. We further design a Global-guided Sampling Strategy (GSS) that mitigates patch boundary issues and ensures consistent illumination across shaded and unshaded regions in the recovered image. Comprehensive experiments on three publicly standard datasets ISTD, ISTD+, and SRD have demonstrated the effectiveness of Diff-Shadow. Compared to state-of-the-art methods, our method achieves a significant improvement in terms of PSNR, increasing from 32.33dB to 33.69dB on the SRD dataset. Codes will be released.
Improving Bracket Image Restoration and Enhancement with Flow-guided Alignment and Enhanced Feature Aggregation
Apr 16, 2024


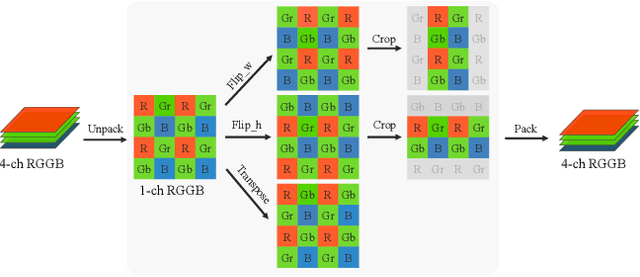
In this paper, we address the Bracket Image Restoration and Enhancement (BracketIRE) task using a novel framework, which requires restoring a high-quality high dynamic range (HDR) image from a sequence of noisy, blurred, and low dynamic range (LDR) multi-exposure RAW inputs. To overcome this challenge, we present the IREANet, which improves the multiple exposure alignment and aggregation with a Flow-guide Feature Alignment Module (FFAM) and an Enhanced Feature Aggregation Module (EFAM). Specifically, the proposed FFAM incorporates the inter-frame optical flow as guidance to facilitate the deformable alignment and spatial attention modules for better feature alignment. The EFAM further employs the proposed Enhanced Residual Block (ERB) as a foundational component, wherein a unidirectional recurrent network aggregates the aligned temporal features to better reconstruct the results. To improve model generalization and performance, we additionally employ the Bayer preserving augmentation (BayerAug) strategy to augment the multi-exposure RAW inputs. Our experimental evaluations demonstrate that the proposed IREANet shows state-of-the-art performance compared with previous methods.
Realistic Noise Synthesis with Diffusion Models
May 23, 2023

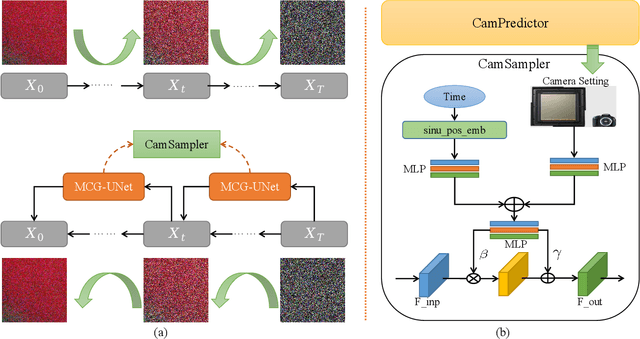

Deep learning-based approaches have achieved remarkable performance in single-image denoising. However, training denoising models typically requires a large amount of data, which can be difficult to obtain in real-world scenarios. Furthermore, synthetic noise used in the past has often produced significant differences compared to real-world noise due to the complexity of the latter and the poor modeling ability of noise distributions of Generative Adversarial Network (GAN) models, resulting in residual noise and artifacts within denoising models. To address these challenges, we propose a novel method for synthesizing realistic noise using diffusion models. This approach enables us to generate large amounts of high-quality data for training denoising models by controlling camera settings to simulate different environmental conditions and employing guided multi-scale content information to ensure that our method is more capable of generating real noise with multi-frequency spatial correlations. In particular, we design an inversion mechanism for the setting, which extends our method to more public datasets without setting information. Based on the noise dataset we synthesized, we have conducted sufficient experiments on multiple benchmarks, and experimental results demonstrate that our method outperforms state-of-the-art methods on multiple benchmarks and metrics, demonstrating its effectiveness in synthesizing realistic noise for training denoising models.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022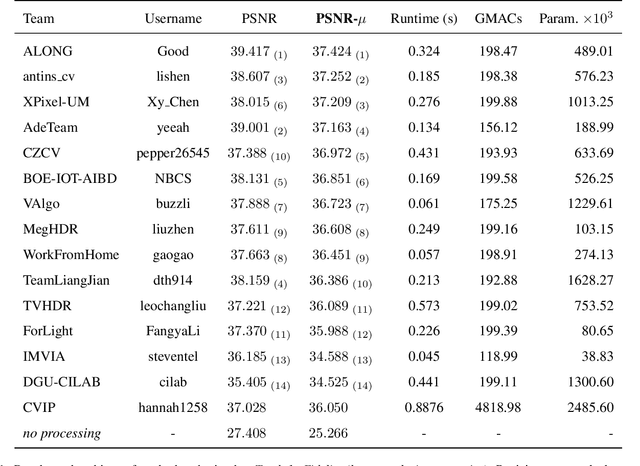
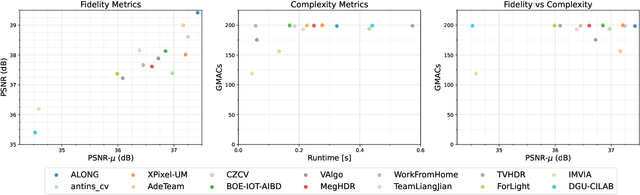
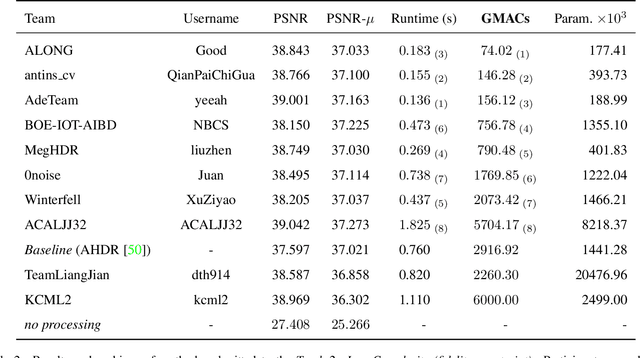
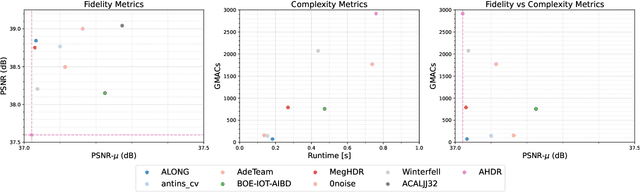
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
ADNet: Attention-guided Deformable Convolutional Network for High Dynamic Range Imaging
May 22, 2021
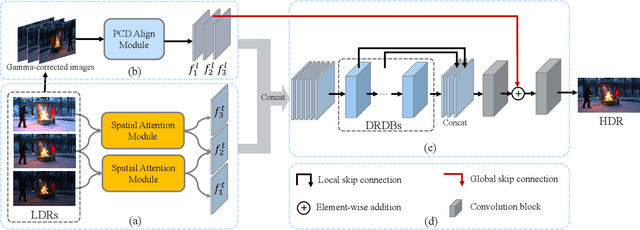
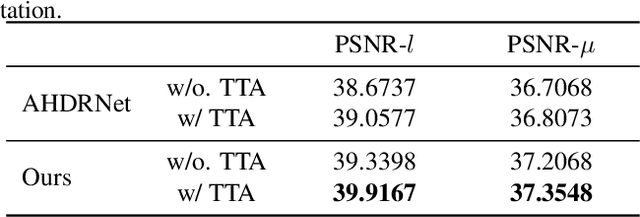
In this paper, we present an attention-guided deformable convolutional network for hand-held multi-frame high dynamic range (HDR) imaging, namely ADNet. This problem comprises two intractable challenges of how to handle saturation and noise properly and how to tackle misalignments caused by object motion or camera jittering. To address the former, we adopt a spatial attention module to adaptively select the most appropriate regions of various exposure low dynamic range (LDR) images for fusion. For the latter one, we propose to align the gamma-corrected images in the feature-level with a Pyramid, Cascading and Deformable (PCD) alignment module. The proposed ADNet shows state-of-the-art performance compared with previous methods, achieving a PSNR-$l$ of 39.4471 and a PSNR-$\mu$ of 37.6359 in NTIRE 2021 Multi-Frame HDR Challenge.