 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic Noise Synthesis with Diffusion Models
Paper and Code
May 23, 2023

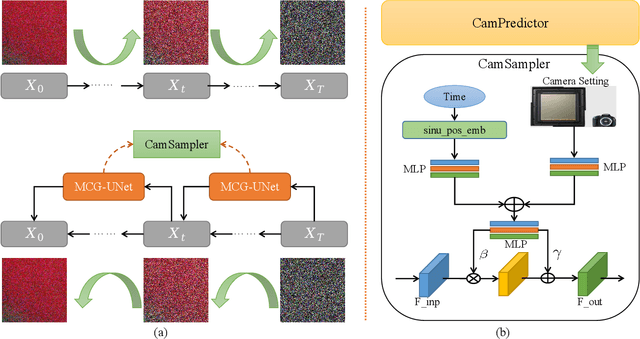

Deep learning-based approaches have achieved remarkable performance in single-image denoising. However, training denoising models typically requires a large amount of data, which can be difficult to obtain in real-world scenarios. Furthermore, synthetic noise used in the past has often produced significant differences compared to real-world noise due to the complexity of the latter and the poor modeling ability of noise distributions of Generative Adversarial Network (GAN) models, resulting in residual noise and artifacts within denoising models. To address these challenges, we propose a novel method for synthesizing realistic noise using diffusion models. This approach enables us to generate large amounts of high-quality data for training denoising models by controlling camera settings to simulate different environmental conditions and employing guided multi-scale content information to ensure that our method is more capable of generating real noise with multi-frequency spatial correlations. In particular, we design an inversion mechanism for the setting, which extends our method to more public datasets without setting information. Based on the noise dataset we synthesized, we have conducted sufficient experiments on multiple benchmarks, and experimental results demonstrate that our method outperforms state-of-the-art methods on multiple benchmarks and metrics, demonstrating its effectiveness in synthesizing realistic noise for training denoising models.