 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM4Sweat: A Trustworthy Large Language Model for Hyperhidrosis Support
Aug 21, 2025While large language models (LLMs) have shown promise in healthcare, their application for rare medical conditions is still hindered by scarce and unreliable datasets for fine-tuning. Hyperhidrosis, a disorder causing excessive sweating beyond physiological needs, is one such rare disorder, affecting 2-3% of the population and significantly impacting both physical comfort and psychosocial well-being. To date, no work has tailored LLMs to advance the diagnosis or care of hyperhidrosis. To address this gap, we present LLM4Sweat, an open-source and domain-specific LLM framework for trustworthy and empathetic hyperhidrosis support. The system follows a three-stage pipeline. In the data augmentation stage, a frontier LLM generates medically plausible synthetic vignettes from curated open-source data to create a diverse and balanced question-answer dataset. In the fine-tuning stage, an open-source foundation model is fine-tuned on the dataset to provide diagnosis, personalized treatment recommendations, and empathetic psychological support. In the inference and expert evaluation stage, clinical and psychological specialists assess accuracy, appropriateness, and empathy, with validated responses iteratively enriching the dataset. Experiments show that LLM4Sweat outperforms baselines and delivers the first open-source LLM framework for hyperhidrosis, offering a generalizable approach for other rare diseases with similar data and trustworthiness challenges.
Think, Reflect, Create: Metacognitive Learning for Zero-Shot Robotic Planning with LLMs
May 20, 2025While large language models (LLMs) have shown great potential across various domains, their applications in robotics remain largely limited to static, prompt-based behaviors and still face challenges in handling complex tasks under zero-shot or few-shot settings. Inspired by human metacognitive learning and creative problem-solving, we address this limitation by exploring a fundamental research question: Can LLMs be empowered with metacognitive capabilities to reason, reflect, and create, thereby enhancing their ability to perform robotic tasks with minimal demonstrations? In this paper, we present an early-stage framework that integrates metacognitive learning into LLM-powered multi-robot collaboration. The proposed framework equips the LLM-powered robotic agents with a skill decomposition and self-reflection mechanism that identifies modular skills from prior tasks, reflects on failures in unseen task scenarios, and synthesizes effective new solutions. Experimental results show that our metacognitive-learning-empowered LLM framework significantly outperforms existing baselines. Moreover, we observe that the framework is capable of generating solutions that differ from the ground truth yet still successfully complete the tasks. These exciting findings support our hypothesis that metacognitive learning can foster creativity in robotic planning.
A High Energy-Efficiency Multi-core Neuromorphic Architecture for Deep SNN Training
Dec 10, 2024
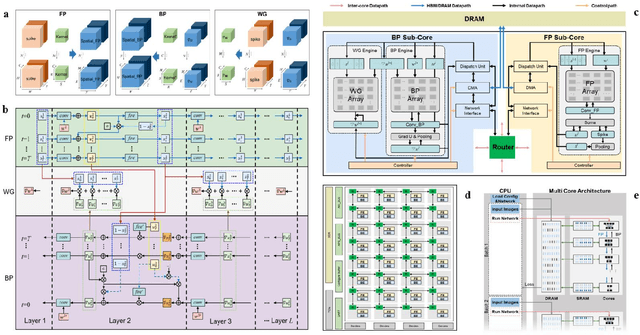
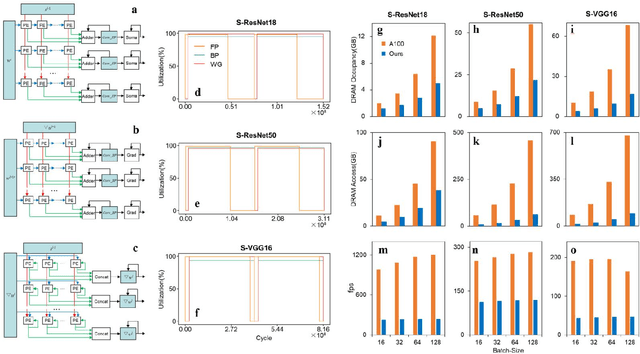
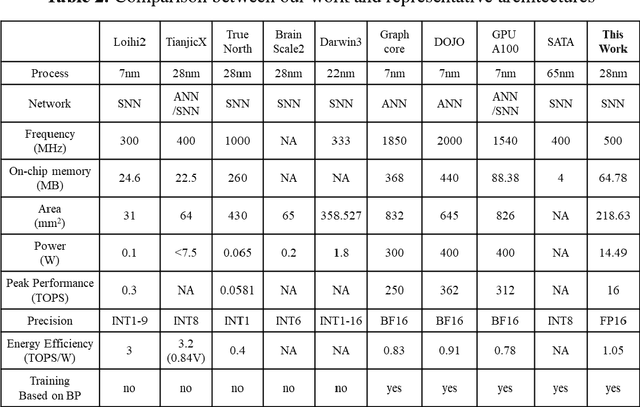
There is a growing necessity for edge training to adapt to dynamically changing environment. Neuromorphic computing represents a significant pathway for high-efficiency intelligent computation in energy-constrained edges, but existing neuromorphic architectures lack the ability of directly training spiking neural networks (SNNs) based on backpropagation. We develop a multi-core neuromorphic architecture with Feedforward-Propagation, Back-Propagation, and Weight-Gradient engines in each core, supporting high efficient parallel computing at both the engine and core levels. It combines various data flows and sparse computation optimization by fully leveraging the sparsity in SNN training, obtaining a high energy efficiency of 1.05TFLOPS/W@ FP16 @ 28nm, 55 ~ 85% reduction of DRAM access compared to A100 GPU in SNN trainings, and a 20-core deep SNN training and a 5-worker federated learning on FPGAs. Our study develops the first multi-core neuromorphic architecture supporting the direct SNN training, facilitating the neuromorphic computing in edge-learnable applications.
Core Placement Optimization of Many-core Brain-Inspired Near-Storage Systems for Spiking Neural Network Training
Nov 29, 2024With the increasing application scope of spiking neural networks (SNN), the complexity of SNN models has surged, leading to an exponential growth in demand for AI computility. As the new generation computing architecture of the neural networks, the efficiency and power consumption of distributed storage and parallel computing in the many-core near-memory computing system have attracted much attention. Among them, the mapping problem from logical cores to physical cores is one of the research hotspots. In order to improve the computing parallelism and system throughput of the many-core near-memory computing system, and to reduce power consumption, we propose a SNN training many-core deployment optimization method based on Off-policy Deterministic Actor-Critic. We utilize deep reinforcement learning as a nonlinear optimizer, treating the many-core topology as network graph features and using graph convolution to input the many-core structure into the policy network. We update the parameters of the policy network through near-end policy optimization to achieve deployment optimization of SNN models in the many-core near-memory computing architecture to reduce chip power consumption. To handle large-dimensional action spaces, we use continuous values matching the number of cores as the output of the policy network and then discretize them again to obtain new deployment schemes. Furthermore, to further balance inter-core computation latency and improve system throughput, we propose a model partitioning method with a balanced storage and computation strategy. Our method overcomes the problems such as uneven computation and storage loads between cores, and the formation of local communication hotspots, significantly reducing model training time, communication costs, and average flow load between cores in the many-core near-memory computing architecture.
Efficient Single Image Super-Resolution with Entropy Attention and Receptive Field Augmentation
Aug 08, 2024
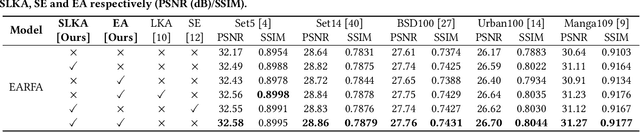

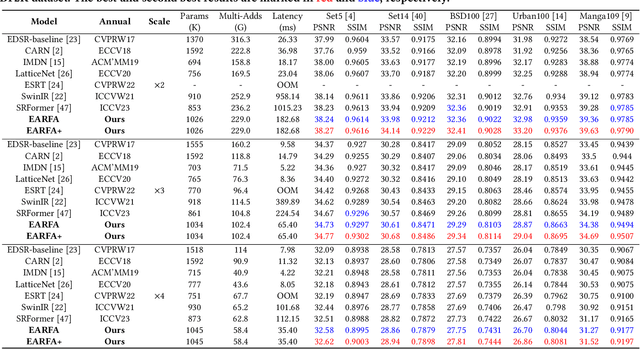
Transformer-based deep models for single image super-resolution (SISR) have greatly improved the performance of lightweight SISR tasks in recent years. However, they often suffer from heavy computational burden and slow inference due to the complex calculation of multi-head self-attention (MSA), seriously hindering their practical application and deployment. In this work, we present an efficient SR model to mitigate the dilemma between model efficiency and SR performance, which is dubbed Entropy Attention and Receptive Field Augmentation network (EARFA), and composed of a novel entropy attention (EA) and a shifting large kernel attention (SLKA). From the perspective of information theory, EA increases the entropy of intermediate features conditioned on a Gaussian distribution, providing more informative input for subsequent reasoning. On the other hand, SLKA extends the receptive field of SR models with the assistance of channel shifting, which also favors to boost the diversity of hierarchical features. Since the implementation of EA and SLKA does not involve complex computations (such as extensive matrix multiplications), the proposed method can achieve faster nonlinear inference than Transformer-based SR models while maintaining better SR performance. Extensive experiments show that the proposed model can significantly reduce the delay of model inference while achieving the SR performance comparable with other advanced models.
Improving Bracket Image Restoration and Enhancement with Flow-guided Alignment and Enhanced Feature Aggregation
Apr 16, 2024


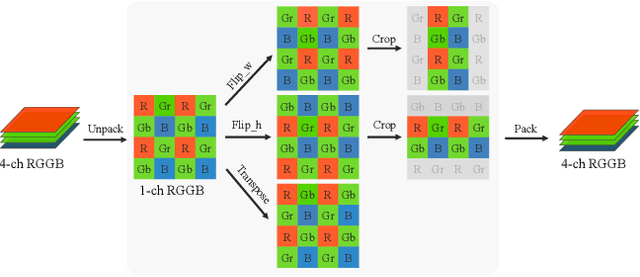
In this paper, we address the Bracket Image Restoration and Enhancement (BracketIRE) task using a novel framework, which requires restoring a high-quality high dynamic range (HDR) image from a sequence of noisy, blurred, and low dynamic range (LDR) multi-exposure RAW inputs. To overcome this challenge, we present the IREANet, which improves the multiple exposure alignment and aggregation with a Flow-guide Feature Alignment Module (FFAM) and an Enhanced Feature Aggregation Module (EFAM). Specifically, the proposed FFAM incorporates the inter-frame optical flow as guidance to facilitate the deformable alignment and spatial attention modules for better feature alignment. The EFAM further employs the proposed Enhanced Residual Block (ERB) as a foundational component, wherein a unidirectional recurrent network aggregates the aligned temporal features to better reconstruct the results. To improve model generalization and performance, we additionally employ the Bayer preserving augmentation (BayerAug) strategy to augment the multi-exposure RAW inputs. Our experimental evaluations demonstrate that the proposed IREANet shows state-of-the-art performance compared with previous methods.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022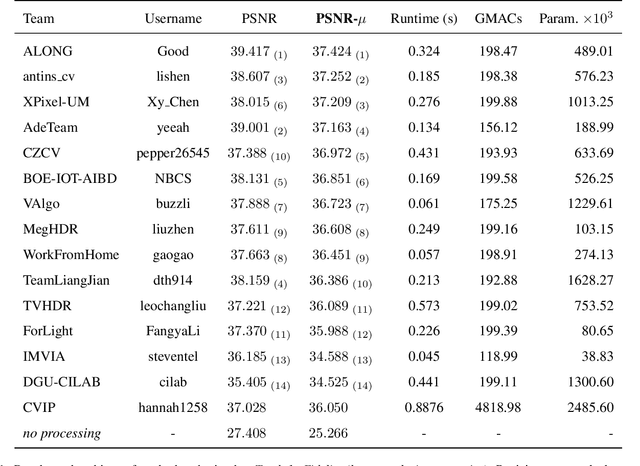
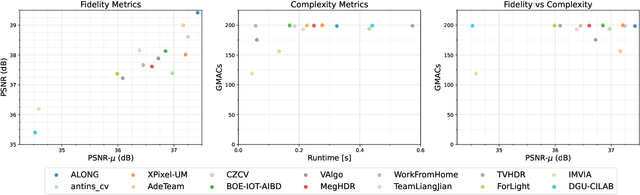
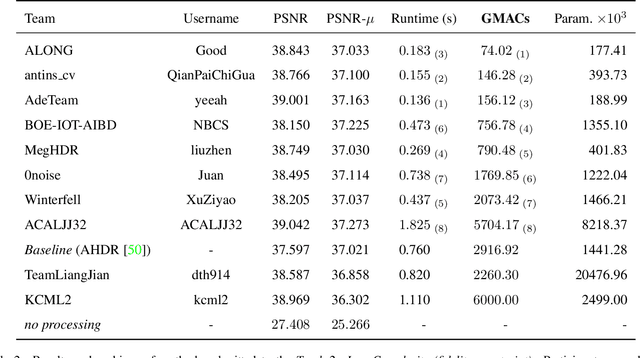
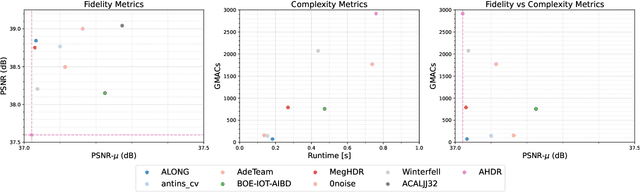
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
ADNet: Attention-guided Deformable Convolutional Network for High Dynamic Range Imaging
May 22, 2021
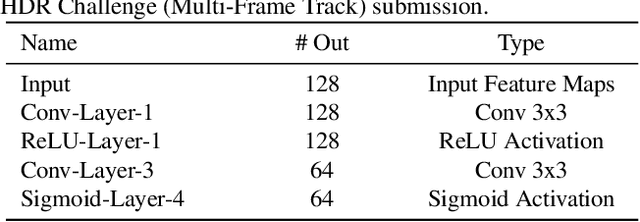
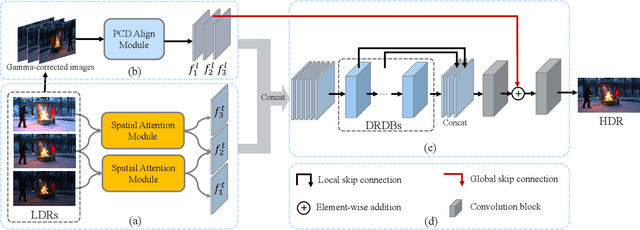
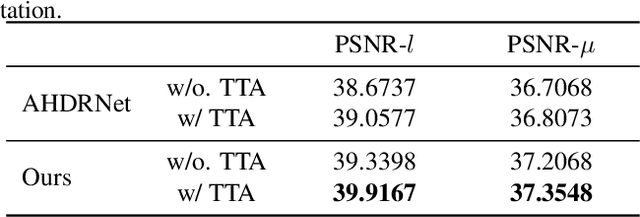
In this paper, we present an attention-guided deformable convolutional network for hand-held multi-frame high dynamic range (HDR) imaging, namely ADNet. This problem comprises two intractable challenges of how to handle saturation and noise properly and how to tackle misalignments caused by object motion or camera jittering. To address the former, we adopt a spatial attention module to adaptively select the most appropriate regions of various exposure low dynamic range (LDR) images for fusion. For the latter one, we propose to align the gamma-corrected images in the feature-level with a Pyramid, Cascading and Deformable (PCD) alignment module. The proposed ADNet shows state-of-the-art performance compared with previous methods, achieving a PSNR-$l$ of 39.4471 and a PSNR-$\mu$ of 37.6359 in NTIRE 2021 Multi-Frame HDR Challenge.
New Era of Deeplearning-Based Malware Intrusion Detection: The Malware Detection and Prediction Based On Deep Learning
Jul 19, 2019

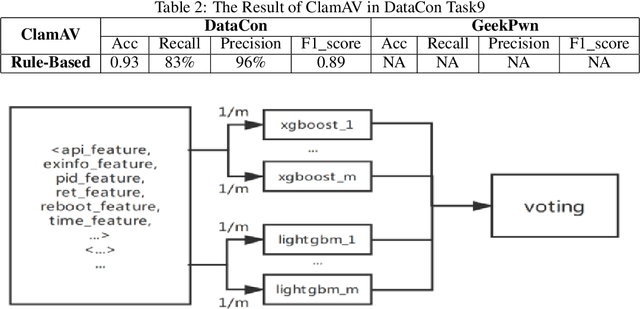
With the development of artificial intelligence algorithms like deep learning models and the successful applications in many different fields, further similar trails of deep learning technology have been made in cyber security area. It shows the preferable performance not only in academic security research but also in industry practices when dealing with part of cyber security issues by deep learning methods compared to those conventional rules. Especially for the malware detection and classification tasks, it saves generous time cost and promotes the accuracy for a total pipeline of malware detection system. In this paper, we construct special deep neural network, ie, MalDeepNet (TB-Malnet and IB-Malnet) for malware dynamic behavior classification tasks. Then we build the family clustering algorithm based on deep learning and fulfil related testing. Except that, we also design a novel malware prediction model which could detect the malware coming in future through the Mal Generative Adversarial Network (Mal-GAN) implementation. All those algorithms present fairly considerable value in related datasets afterwards.