 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA High Energy-Efficiency Multi-core Neuromorphic Architecture for Deep SNN Training
Dec 10, 2024
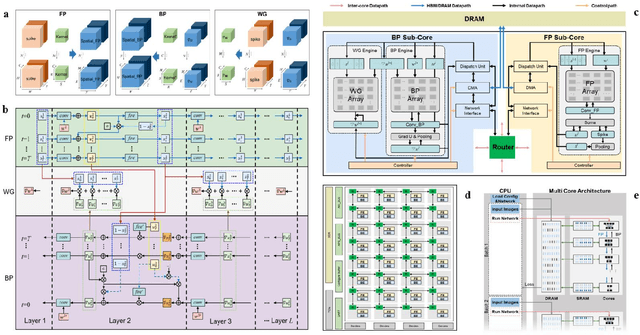
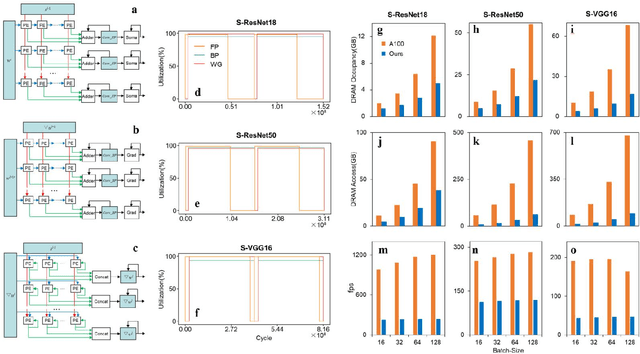
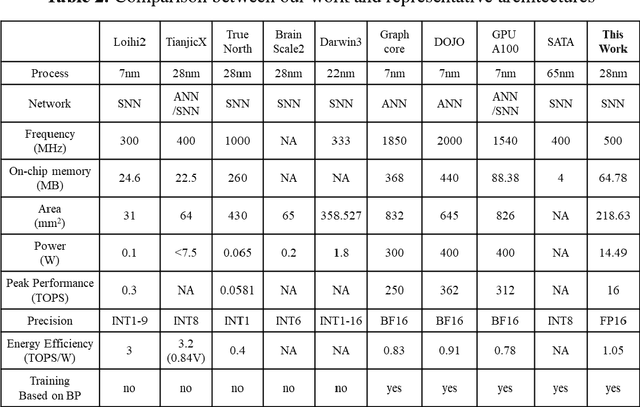
There is a growing necessity for edge training to adapt to dynamically changing environment. Neuromorphic computing represents a significant pathway for high-efficiency intelligent computation in energy-constrained edges, but existing neuromorphic architectures lack the ability of directly training spiking neural networks (SNNs) based on backpropagation. We develop a multi-core neuromorphic architecture with Feedforward-Propagation, Back-Propagation, and Weight-Gradient engines in each core, supporting high efficient parallel computing at both the engine and core levels. It combines various data flows and sparse computation optimization by fully leveraging the sparsity in SNN training, obtaining a high energy efficiency of 1.05TFLOPS/W@ FP16 @ 28nm, 55 ~ 85% reduction of DRAM access compared to A100 GPU in SNN trainings, and a 20-core deep SNN training and a 5-worker federated learning on FPGAs. Our study develops the first multi-core neuromorphic architecture supporting the direct SNN training, facilitating the neuromorphic computing in edge-learnable applications.
Super-Resolving Face Image by Facial Parsing Information
Apr 06, 2023



Face super-resolution is a technology that transforms a low-resolution face image into the corresponding high-resolution one. In this paper, we build a novel parsing map guided face super-resolution network which extracts the face prior (i.e., parsing map) directly from low-resolution face image for the following utilization. To exploit the extracted prior fully, a parsing map attention fusion block is carefully designed, which can not only effectively explore the information of parsing map, but also combines powerful attention mechanism. Moreover, in light of that high-resolution features contain more precise spatial information while low-resolution features provide strong contextual information, we hope to maintain and utilize these complementary information. To achieve this goal, we develop a multi-scale refine block to maintain spatial and contextual information and take advantage of multi-scale features to refine the feature representations. Experimental results demonstrate that our method outperforms the state-of-the-arts in terms of quantitative metrics and visual quality. The source codes will be available at https://github.com/wcy-cs/FishFSRNet.
Guided Depth Map Super-resolution: A Survey
Mar 07, 2023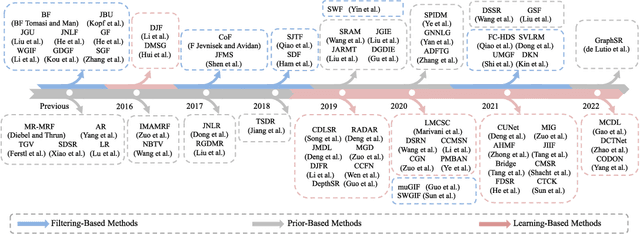


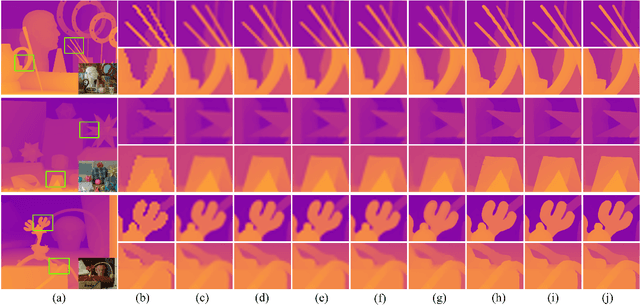
Guided depth map super-resolution (GDSR), which aims to reconstruct a high-resolution (HR) depth map from a low-resolution (LR) observation with the help of a paired HR color image, is a longstanding and fundamental problem, it has attracted considerable attention from computer vision and image processing communities. A myriad of novel and effective approaches have been proposed recently, especially with powerful deep learning techniques. This survey is an effort to present a comprehensive survey of recent progress in GDSR. We start by summarizing the problem of GDSR and explaining why it is challenging. Next, we introduce some commonly used datasets and image quality assessment methods. In addition, we roughly classify existing GDSR methods into three categories, i.e., filtering-based methods, prior-based methods, and learning-based methods. In each category, we introduce the general description of the published algorithms and design principles, summarize the representative methods, and discuss their highlights and limitations. Moreover, the depth related applications are introduced. Furthermore, we conduct experiments to evaluate the performance of some representative methods based on unified experimental configurations, so as to offer a systematic and fair performance evaluation to readers. Finally, we conclude this survey with possible directions and open problems for further research. All the related materials can be found at \url{https://github.com/zhwzhong/Guided-Depth-Map-Super-resolution-A-Survey}.
Self-Supervised Arbitrary-Scale Point Clouds Upsampling via Implicit Neural Representation
Apr 18, 2022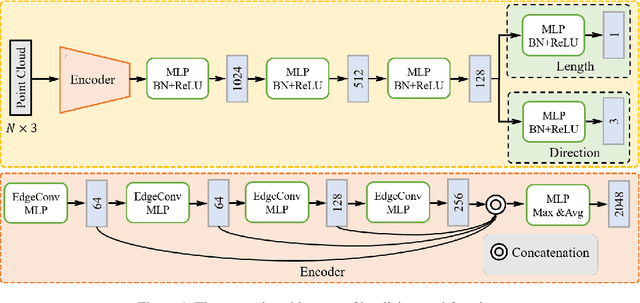
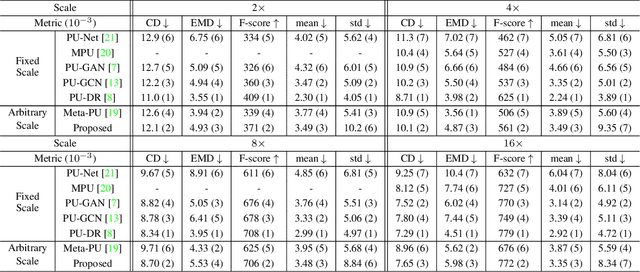
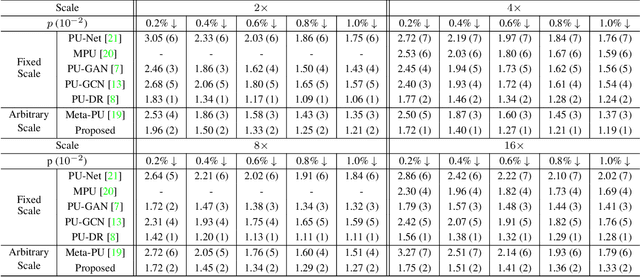
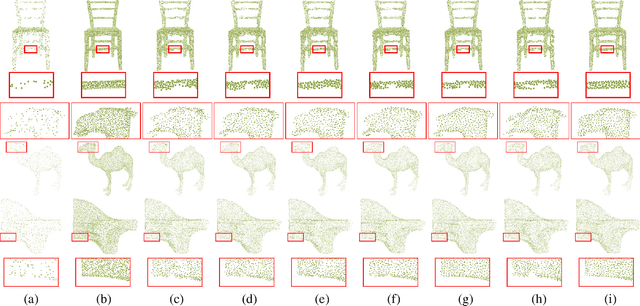
Point clouds upsampling is a challenging issue to generate dense and uniform point clouds from the given sparse input. Most existing methods either take the end-to-end supervised learning based manner, where large amounts of pairs of sparse input and dense ground-truth are exploited as supervision information; or treat up-scaling of different scale factors as independent tasks, and have to build multiple networks to handle upsampling with varying factors. In this paper, we propose a novel approach that achieves self-supervised and magnification-flexible point clouds upsampling simultaneously. We formulate point clouds upsampling as the task of seeking nearest projection points on the implicit surface for seed points. To this end, we define two implicit neural functions to estimate projection direction and distance respectively, which can be trained by two pretext learning tasks. Experimental results demonstrate that our self-supervised learning based scheme achieves competitive or even better performance than supervised learning based state-of-the-art methods. The source code is publicly available at https://github.com/xnowbzhao/sapcu.
Deep Attentional Guided Image Filtering
Dec 13, 2021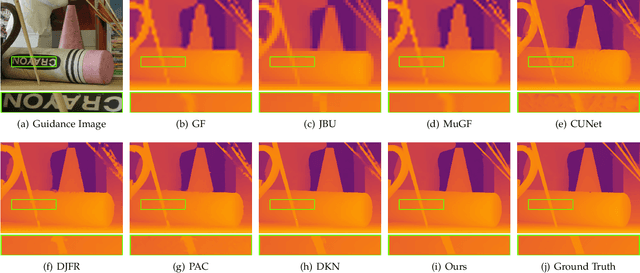
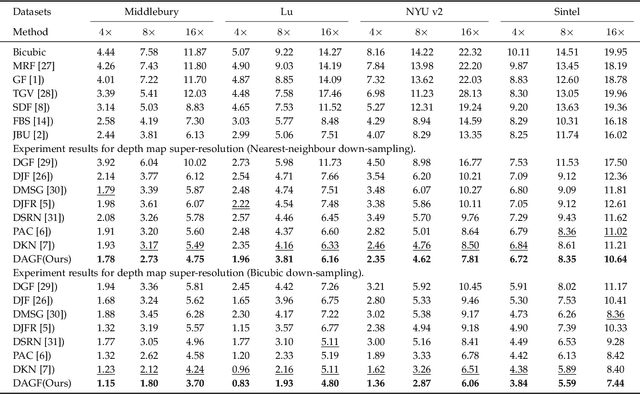
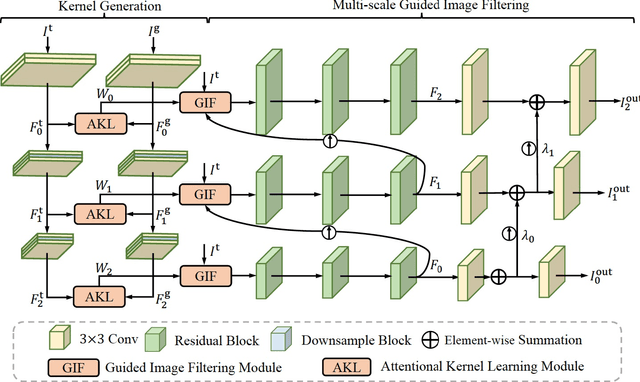

Guided filter is a fundamental tool in computer vision and computer graphics which aims to transfer structure information from guidance image to target image. Most existing methods construct filter kernels from the guidance itself without considering the mutual dependency between the guidance and the target. However, since there typically exist significantly different edges in the two images, simply transferring all structural information of the guidance to the target would result in various artifacts. To cope with this problem, we propose an effective framework named deep attentional guided image filtering, the filtering process of which can fully integrate the complementary information contained in both images. Specifically, we propose an attentional kernel learning module to generate dual sets of filter kernels from the guidance and the target, respectively, and then adaptively combine them by modeling the pixel-wise dependency between the two images. Meanwhile, we propose a multi-scale guided image filtering module to progressively generate the filtering result with the constructed kernels in a coarse-to-fine manner. Correspondingly, a multi-scale fusion strategy is introduced to reuse the intermediate results in the coarse-to-fine process. Extensive experiments show that the proposed framework compares favorably with the state-of-the-art methods in a wide range of guided image filtering applications, such as guided super-resolution, cross-modality restoration, texture removal, and semantic segmentation.
High-resolution Depth Maps Imaging via Attention-based Hierarchical Multi-modal Fusion
Apr 13, 2021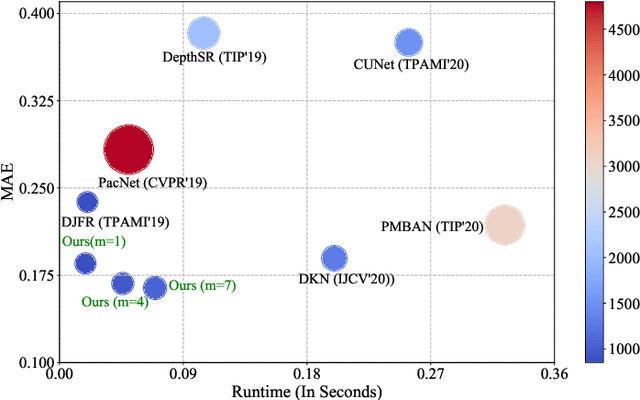

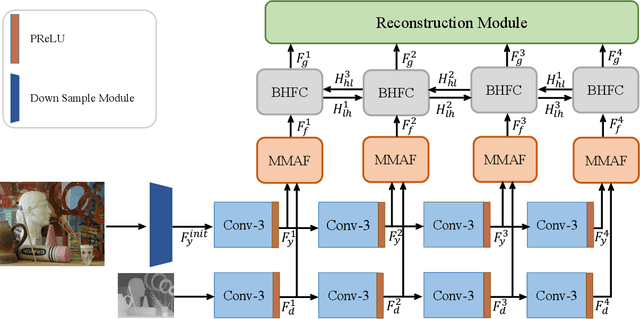
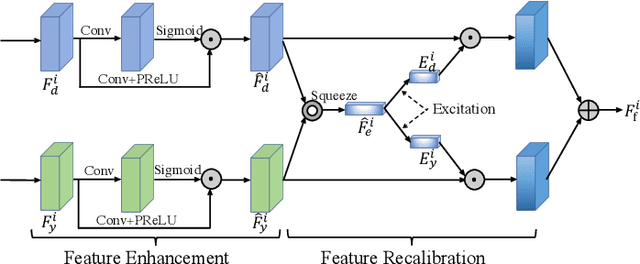
Depth map records distance between the viewpoint and objects in the scene, which plays a critical role in many real-world applications. However, depth map captured by consumer-grade RGB-D cameras suffers from low spatial resolution. Guided depth map super-resolution (DSR) is a popular approach to address this problem, which attempts to restore a high-resolution (HR) depth map from the input low-resolution (LR) depth and its coupled HR RGB image that serves as the guidance. The most challenging problems for guided DSR are how to correctly select consistent structures and propagate them, and properly handle inconsistent ones. In this paper, we propose a novel attention-based hierarchical multi-modal fusion (AHMF) network for guided DSR. Specifically, to effectively extract and combine relevant information from LR depth and HR guidance, we propose a multi-modal attention based fusion (MMAF) strategy for hierarchical convolutional layers, including a feature enhance block to select valuable features and a feature recalibration block to unify the similarity metrics of modalities with different appearance characteristics. Furthermore, we propose a bi-directional hierarchical feature collaboration (BHFC) module to fully leverage low-level spatial information and high-level structure information among multi-scale features. Experimental results show that our approach outperforms state-of-the-art methods in terms of reconstruction accuracy, running speed and memory efficiency.