 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoReview: Learning Peer Review from the Echoes of Scientific Citations
Jan 31, 2026As the volume of scientific submissions continues to grow rapidly, traditional peer review systems are facing unprecedented scalability pressures, highlighting the urgent need for automated reviewing methods that are both scalable and reliable. Existing supervised fine-tuning approaches based on real review data are fundamentally constrained by single-source of data as well as the inherent subjectivity and inconsistency of human reviews, limiting their ability to support high-quality automated reviewers. To address these issues, we propose EchoReview, a citation-context-driven data synthesis framework that systematically mines implicit collective evaluative signals from academic citations and transforms scientific community's long-term judgments into structured review-style data. Based on this pipeline, we construct EchoReview-16K, the first large-scale, cross-conference, and cross-year citation-driven review dataset, and train an automated reviewer, EchoReviewer-7B. Experimental results demonstrate that EchoReviewer-7B can achieve significant and stable improvements on core review dimensions such as evidence support and review comprehensiveness, validating citation context as a robust and effective data paradigm for reliable automated peer review.
Variation-Bounded Loss for Noise-Tolerant Learning
Nov 15, 2025Mitigating the negative impact of noisy labels has been aperennial issue in supervised learning. Robust loss functions have emerged as a prevalent solution to this problem. In this work, we introduce the Variation Ratio as a novel property related to the robustness of loss functions, and propose a new family of robust loss functions, termed Variation-Bounded Loss (VBL), which is characterized by a bounded variation ratio. We provide theoretical analyses of the variation ratio, proving that a smaller variation ratio would lead to better robustness. Furthermore, we reveal that the variation ratio provides a feasible method to relax the symmetric condition and offers a more concise path to achieve the asymmetric condition. Based on the variation ratio, we reformulate several commonly used loss functions into a variation-bounded form for practical applications. Positive experiments on various datasets exhibit the effectiveness and flexibility of our approach.
Joint Asymmetric Loss for Learning with Noisy Labels
Jul 23, 2025Learning with noisy labels is a crucial task for training accurate deep neural networks. To mitigate label noise, prior studies have proposed various robust loss functions, particularly symmetric losses. Nevertheless, symmetric losses usually suffer from the underfitting issue due to the overly strict constraint. To address this problem, the Active Passive Loss (APL) jointly optimizes an active and a passive loss to mutually enhance the overall fitting ability. Within APL, symmetric losses have been successfully extended, yielding advanced robust loss functions. Despite these advancements, emerging theoretical analyses indicate that asymmetric losses, a new class of robust loss functions, possess superior properties compared to symmetric losses. However, existing asymmetric losses are not compatible with advanced optimization frameworks such as APL, limiting their potential and applicability. Motivated by this theoretical gap and the prospect of asymmetric losses, we extend the asymmetric loss to the more complex passive loss scenario and propose the Asymetric Mean Square Error (AMSE), a novel asymmetric loss. We rigorously establish the necessary and sufficient condition under which AMSE satisfies the asymmetric condition. By substituting the traditional symmetric passive loss in APL with our proposed AMSE, we introduce a novel robust loss framework termed Joint Asymmetric Loss (JAL). Extensive experiments demonstrate the effectiveness of our method in mitigating label noise. Code available at: https://github.com/cswjl/joint-asymmetric-loss
Learning Lossless Compression for High Bit-Depth Volumetric Medical Image
Oct 23, 2024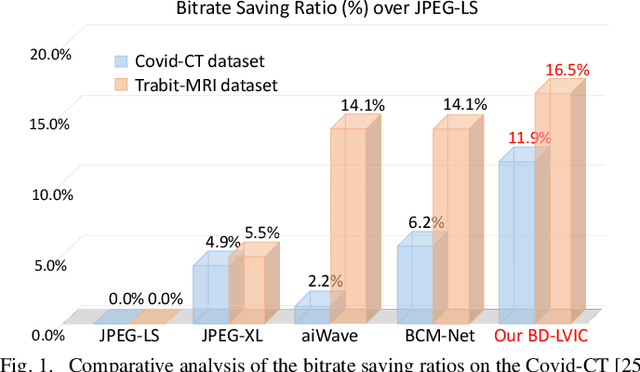
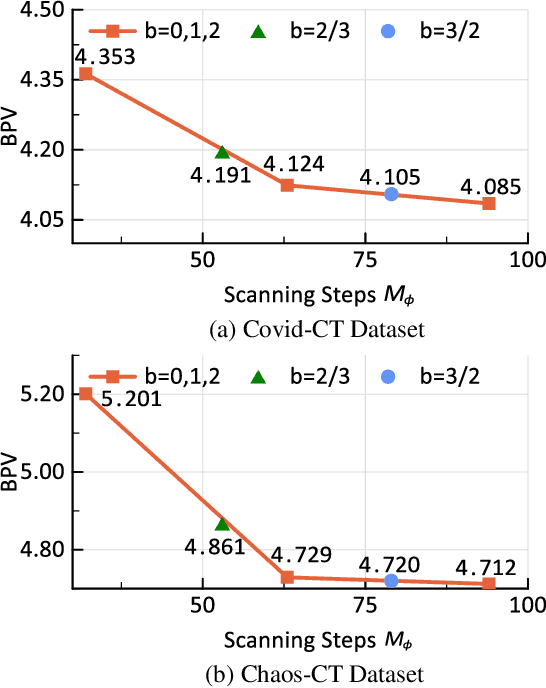
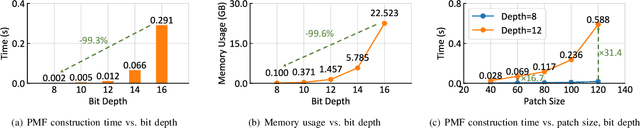
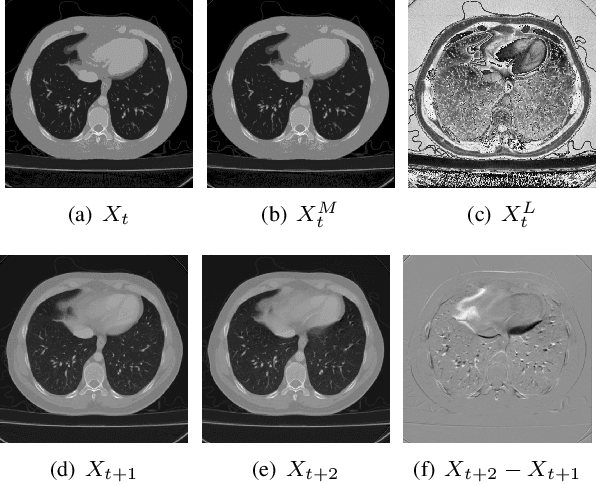
Recent advances in learning-based methods have markedly enhanced the capabilities of image compression. However, these methods struggle with high bit-depth volumetric medical images, facing issues such as degraded performance, increased memory demand, and reduced processing speed. To address these challenges, this paper presents the Bit-Division based Lossless Volumetric Image Compression (BD-LVIC) framework, which is tailored for high bit-depth medical volume compression. The BD-LVIC framework skillfully divides the high bit-depth volume into two lower bit-depth segments: the Most Significant Bit-Volume (MSBV) and the Least Significant Bit-Volume (LSBV). The MSBV concentrates on the most significant bits of the volumetric medical image, capturing vital structural details in a compact manner. This reduction in complexity greatly improves compression efficiency using traditional codecs. Conversely, the LSBV deals with the least significant bits, which encapsulate intricate texture details. To compress this detailed information effectively, we introduce an effective learning-based compression model equipped with a Transformer-Based Feature Alignment Module, which exploits both intra-slice and inter-slice redundancies to accurately align features. Subsequently, a Parallel Autoregressive Coding Module merges these features to precisely estimate the probability distribution of the least significant bit-planes. Our extensive testing demonstrates that the BD-LVIC framework not only sets new performance benchmarks across various datasets but also maintains a competitive coding speed, highlighting its significant potential and practical utility in the realm of volumetric medical image compression.
MCGS: Multiview Consistency Enhancement for Sparse-View 3D Gaussian Radiance Fields
Oct 15, 2024



Radiance fields represented by 3D Gaussians excel at synthesizing novel views, offering both high training efficiency and fast rendering. However, with sparse input views, the lack of multi-view consistency constraints results in poorly initialized point clouds and unreliable heuristics for optimization and densification, leading to suboptimal performance. Existing methods often incorporate depth priors from dense estimation networks but overlook the inherent multi-view consistency in input images. Additionally, they rely on multi-view stereo (MVS)-based initialization, which limits the efficiency of scene representation. To overcome these challenges, we propose a view synthesis framework based on 3D Gaussian Splatting, named MCGS, enabling photorealistic scene reconstruction from sparse input views. The key innovations of MCGS in enhancing multi-view consistency are as follows: i) We introduce an initialization method by leveraging a sparse matcher combined with a random filling strategy, yielding a compact yet sufficient set of initial points. This approach enhances the initial geometry prior, promoting efficient scene representation. ii) We develop a multi-view consistency-guided progressive pruning strategy to refine the Gaussian field by strengthening consistency and eliminating low-contribution Gaussians. These modular, plug-and-play strategies enhance robustness to sparse input views, accelerate rendering, and reduce memory consumption, making MCGS a practical and efficient framework for 3D Gaussian Splatting.
Spatial Annealing Smoothing for Efficient Few-shot Neural Rendering
Jun 12, 2024Neural Radiance Fields (NeRF) with hybrid representations have shown impressive capabilities in reconstructing scenes for view synthesis, delivering high efficiency. Nonetheless, their performance significantly drops with sparse view inputs, due to the issue of overfitting. While various regularization strategies have been devised to address these challenges, they often depend on inefficient assumptions or are not compatible with hybrid models. There is a clear need for a method that maintains efficiency and improves resilience to sparse views within a hybrid framework. In this paper, we introduce an accurate and efficient few-shot neural rendering method named Spatial Annealing smoothing regularized NeRF (SANeRF), which is specifically designed for a pre-filtering-driven hybrid representation architecture. We implement an exponential reduction of the sample space size from an initially large value. This methodology is crucial for stabilizing the early stages of the training phase and significantly contributes to the enhancement of the subsequent process of detail refinement. Our extensive experiments reveal that, by adding merely one line of code, SANeRF delivers superior rendering quality and much faster reconstruction speed compared to current few-shot NeRF methods. Notably, SANeRF outperforms FreeNeRF by 0.3 dB in PSNR on the Blender dataset, while achieving 700x faster reconstruction speed.
Mesh Denoising Transformer
May 10, 2024Mesh denoising, aimed at removing noise from input meshes while preserving their feature structures, is a practical yet challenging task. Despite the remarkable progress in learning-based mesh denoising methodologies in recent years, their network designs often encounter two principal drawbacks: a dependence on single-modal geometric representations, which fall short in capturing the multifaceted attributes of meshes, and a lack of effective global feature aggregation, hindering their ability to fully understand the mesh's comprehensive structure. To tackle these issues, we propose SurfaceFormer, a pioneering Transformer-based mesh denoising framework. Our first contribution is the development of a new representation known as Local Surface Descriptor, which is crafted by establishing polar systems on each mesh face, followed by sampling points from adjacent surfaces using geodesics. The normals of these points are organized into 2D patches, mimicking images to capture local geometric intricacies, whereas the poles and vertex coordinates are consolidated into a point cloud to embody spatial information. This advancement surmounts the hurdles posed by the irregular and non-Euclidean characteristics of mesh data, facilitating a smooth integration with Transformer architecture. Next, we propose a dual-stream structure consisting of a Geometric Encoder branch and a Spatial Encoder branch, which jointly encode local geometry details and spatial information to fully explore multimodal information for mesh denoising. A subsequent Denoising Transformer module receives the multimodal information and achieves efficient global feature aggregation through self-attention operators. Our experimental evaluations demonstrate that this novel approach outperforms existing state-of-the-art methods in both objective and subjective assessments, marking a significant leap forward in mesh denoising.
SGCNeRF: Few-Shot Neural Rendering via Sparse Geometric Consistency Guidance
Apr 01, 2024Neural Radiance Field (NeRF) technology has made significant strides in creating novel viewpoints. However, its effectiveness is hampered when working with sparsely available views, often leading to performance dips due to overfitting. FreeNeRF attempts to overcome this limitation by integrating implicit geometry regularization, which incrementally improves both geometry and textures. Nonetheless, an initial low positional encoding bandwidth results in the exclusion of high-frequency elements. The quest for a holistic approach that simultaneously addresses overfitting and the preservation of high-frequency details remains ongoing. This study introduces a novel feature matching based sparse geometry regularization module. This module excels in pinpointing high-frequency keypoints, thereby safeguarding the integrity of fine details. Through progressive refinement of geometry and textures across NeRF iterations, we unveil an effective few-shot neural rendering architecture, designated as SGCNeRF, for enhanced novel view synthesis. Our experiments demonstrate that SGCNeRF not only achieves superior geometry-consistent outcomes but also surpasses FreeNeRF, with improvements of 0.7 dB and 0.6 dB in PSNR on the LLFF and DTU datasets, respectively.
On the Dynamics Under the Unhinged Loss and Beyond
Dec 13, 2023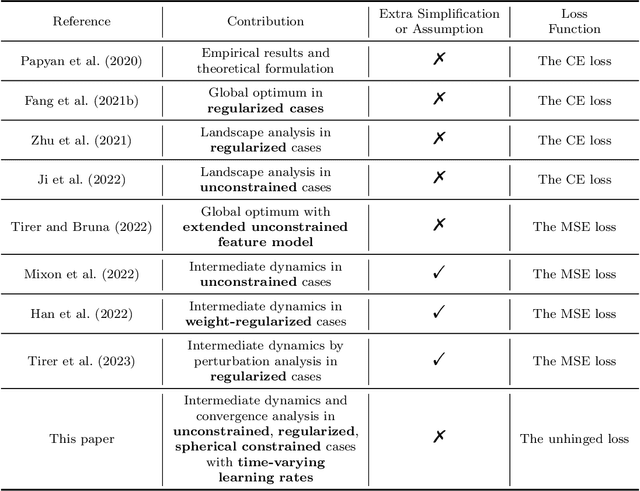


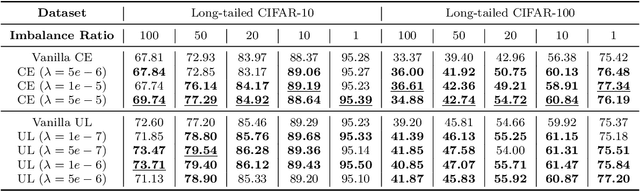
Recent works have studied implicit biases in deep learning, especially the behavior of last-layer features and classifier weights. However, they usually need to simplify the intermediate dynamics under gradient flow or gradient descent due to the intractability of loss functions and model architectures. In this paper, we introduce the unhinged loss, a concise loss function, that offers more mathematical opportunities to analyze the closed-form dynamics while requiring as few simplifications or assumptions as possible. The unhinged loss allows for considering more practical techniques, such as time-vary learning rates and feature normalization. Based on the layer-peeled model that views last-layer features as free optimization variables, we conduct a thorough analysis in the unconstrained, regularized, and spherical constrained cases, as well as the case where the neural tangent kernel remains invariant. To bridge the performance of the unhinged loss to that of Cross-Entropy (CE), we investigate the scenario of fixing classifier weights with a specific structure, (e.g., a simplex equiangular tight frame). Our analysis shows that these dynamics converge exponentially fast to a solution depending on the initialization of features and classifier weights. These theoretical results not only offer valuable insights, including explicit feature regularization and rescaled learning rates for enhancing practical training with the unhinged loss, but also extend their applicability to other loss functions. Finally, we empirically demonstrate these theoretical results and insights through extensive experiments.
Backdoor Attacks Against Incremental Learners: An Empirical Evaluation Study
May 28, 2023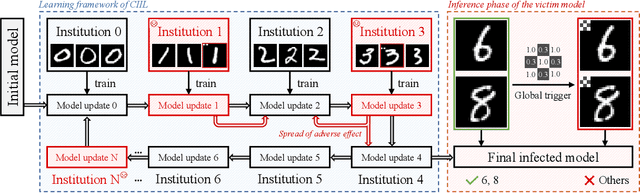
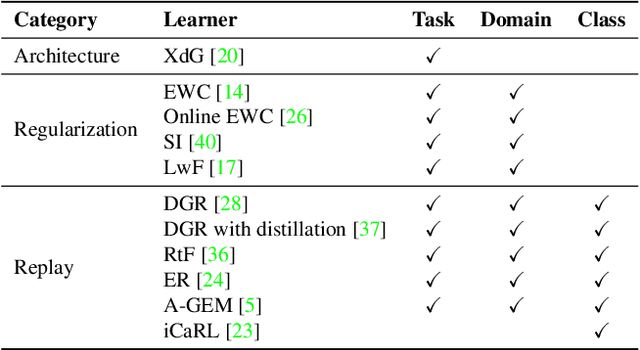
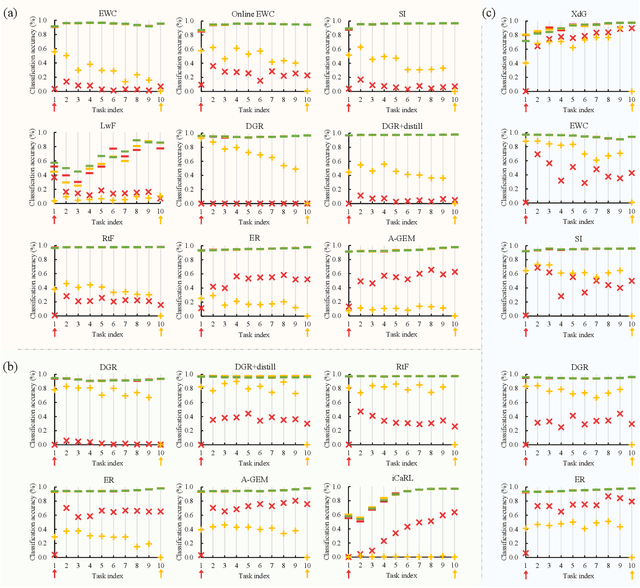

Large amounts of incremental learning algorithms have been proposed to alleviate the catastrophic forgetting issue arises while dealing with sequential data on a time series. However, the adversarial robustness of incremental learners has not been widely verified, leaving potential security risks. Specifically, for poisoning-based backdoor attacks, we argue that the nature of streaming data in IL provides great convenience to the adversary by creating the possibility of distributed and cross-task attacks -- an adversary can affect \textbf{any unknown} previous or subsequent task by data poisoning \textbf{at any time or time series} with extremely small amount of backdoor samples injected (e.g., $0.1\%$ based on our observations). To attract the attention of the research community, in this paper, we empirically reveal the high vulnerability of 11 typical incremental learners against poisoning-based backdoor attack on 3 learning scenarios, especially the cross-task generalization effect of backdoor knowledge, while the poison ratios range from $5\%$ to as low as $0.1\%$. Finally, the defense mechanism based on activation clustering is found to be effective in detecting our trigger pattern to mitigate potential security risks.