 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOFA-VTON: More Fashion Possibilities with Fine-Grained Adaptations in Virtual Try-On
Jun 09, 2026Virtual try-on aims to fit an in-shop clothing image onto a specific human body. An optimal virtual try-on method should provide diverse and flexible dressing options, accurately reflecting the varied wearing styles encountered in real-life scenarios, tailored to individual preferences and fashion aspirations. However, current methods predominantly perform a direct replacement of the original clothing with the target clothing, following the same dressing pattern. This limited control over clothing adaptation may result in fixed and monotonous try-on outputs. To delve into More Fashion Possibilities with Fine-Grained Adaptations in Virtual Try-On, we propose a novel virtual try-on method, termed MOFA-VTON, which allows adjustment for clothing adaptations in try-on results through simple sketches by users. Specifically, we first design a mask construction strategy that transforms user-drawn curve sketches into a dual-region mask, replacing the traditional clothing-agnostic mask and providing fine-grained layout guidance for the subsequent generation process. Further, we propose layout adjustment blocks that utilize the cross-attention mechanism to independently learn layout correspondences for upper and lower regions of the human body, refining the spatial arrangement of the two regions. With these implementations, our method enables flexible and fine-grained adaptations of target clothing, overcoming the constraints of a fixed layout. Extensive experiments on VITON-HD and DressCode datasets demonstrate that our proposed MOFA-VTON outperforms previous state-of-the-art methods and provides more fashion possibilities for virtual try-on.
Graph-GRPO: Dependency-Aware Credit Assignment for Generative E-commerce Search Relevance
May 29, 2026Search relevance modeling is a core task in e-commerce search systems, assessing how well a user query matches candidate products. Rather than relying on a single holistic matching signal, relevance judgment often requires structured reasoning over query understanding, product understanding, and facet-level matching. With large language models (LLMs), this process is increasingly formulated as chain-of-thought (CoT) reasoning and optimized with reinforcement learning (RL). However, existing RL methods mainly rely on outcome-level rewards and treat the entire reasoning chain as a single optimization unit. This makes it difficult to distinguish faulty reasoning steps from correct intermediate ones, leading to misaligned credit assignment. Although process-reward methods provide denser supervision, they often treat reasoning steps independently and ignore dependency-driven error propagation, making responsibility attribution difficult and limiting the optimization of structured relevance reasoning. We propose Graph-GRPO, a graph-structured extension of GRPO for multi-component relevance reasoning. Graph-GRPO constructs a relevance reasoning dependency graph, where CoT steps are modeled as nodes and their logical dependencies as edges. It propagates outcome-level rewards over the graph to derive step-level credit signals, enabling more accurate fine-grained credit assignment. We further introduce a main-loss-driven controller that adaptively adjusts edge-wise credit-propagation coefficients. Together with CoT random masking for supervised policy initialization and graph-node-based multi-head distillation, we build a trainable and deployable framework for generative relevance modeling. Extensive offline evaluations and online A/B tests on a leading e-commerce platform demonstrate that the Graph-GRPO-based framework improves relevance classification metrics and key engagement metrics.
Compositional Multi-hop Factual Error Correction via Decomposition-and-Injection
May 04, 2026Factual Error Correction (FEC) aims to revise inaccurate text into statements that are factually consistent with external evidence. Although recent methods perform well on single-hop correction, they often treat claims as atomic units and struggle with multi-hop cases that require compositional reasoning across multiple evidence sources. This challenge is further amplified by limited paired data and difficulties in locating semantic errors within complex reasoning chains. We present CECoR (Compositional Error Correction via Reasoning-aware Synthesis), a reasoning-aware framework that introduces a Decomposition and Injection paradigm for compositional error correction. CECoR decomposes multi-hop claims into interpretable reasoning steps and injects controlled perturbations to synthesize high-quality training pairs. A two-stage learning strategy combining supervised fine-tuning and reinforcement learning improves factual accuracy and robustness. Comprehensive evaluations show that CECoR achieves strong performance on multi-hop benchmarks, outperforming both distantly supervised methods and few-shot LLM baselines. It also generalizes effectively to single-hop correction and remains stable under noisy evidence, demonstrating its versatility for real-world factual correction.
Gen-Searcher: Reinforcing Agentic Search for Image Generation
Mar 30, 2026Recent image generation models have shown strong capabilities in generating high-fidelity and photorealistic images. However, they are fundamentally constrained by frozen internal knowledge, thus often failing on real-world scenarios that are knowledge-intensive or require up-to-date information. In this paper, we present Gen-Searcher, as the first attempt to train a search-augmented image generation agent, which performs multi-hop reasoning and search to collect the textual knowledge and reference images needed for grounded generation. To achieve this, we construct a tailored data pipeline and curate two high-quality datasets, Gen-Searcher-SFT-10k and Gen-Searcher-RL-6k, containing diverse search-intensive prompts and corresponding ground-truth synthesis images. We further introduce KnowGen, a comprehensive benchmark that explicitly requires search-grounded external knowledge for image generation and evaluates models from multiple dimensions. Based on these resources, we train Gen-Searcher with SFT followed by agentic reinforcement learning with dual reward feedback, which combines text-based and image-based rewards to provide more stable and informative learning signals for GRPO training. Experiments show that Gen-Searcher brings substantial gains, improving Qwen-Image by around 16 points on KnowGen and 15 points on WISE. We hope this work can serve as an open foundation for search agents in image generation, and we fully open-source our data, models, and code.
Non-Adversarial Imitation Learning Provably Free of Compounding Errors: The Role of Bellman Constraints
Mar 24, 2026Adversarial imitation learning (AIL) achieves high-quality imitation by mitigating compounding errors in behavioral cloning (BC), but often exhibits training instability due to adversarial optimization. To avoid this issue, a class of non-adversarial Q-based imitation learning (IL) methods, represented by IQ-Learn, has emerged and is widely believed to outperform BC by leveraging online environment interactions. However, this paper revisits IQ-Learn and demonstrates that it provably reduces to BC and suffers from an imitation gap lower bound with quadratic dependence on horizon, therefore still suffering from compounding errors. Theoretical analysis reveals that, despite using online interactions, IQ-Learn uniformly suppresses the Q-values for all actions on states uncovered by demonstrations, thereby failing to generalize. To address this limitation, we introduce a primal-dual framework for distribution matching, yielding a new Q-based IL method, Dual Q-DM. The key mechanism in Dual Q-DM is incorporating Bellman constraints to propagate high Q-values from visited states to unvisited ones, thereby achieving generalization beyond demonstrations. We prove that Dual Q-DM is equivalent to AIL and can recover expert actions beyond demonstrations, thereby mitigating compounding errors. To the best of our knowledge, Dual Q-DM is the first non-adversarial IL method that is theoretically guaranteed to eliminate compounding errors. Experimental results further corroborate our theoretical results.
Active Inference for Micro-Gesture Recognition: EFE-Guided Temporal Sampling and Adaptive Learning
Mar 08, 2026Micro-gestures are subtle and transient movements triggered by unconscious neural and emotional activities, holding great potential for human-computer interaction and clinical monitoring. However, their low amplitude, short duration, and strong inter-subject variability make existing deep models prone to degradation under low-sample, noisy, and cross-subject conditions. This paper presents an active inference-based framework for micro-gesture recognition, featuring Expected Free Energy (EFE)-guided temporal sampling and uncertainty-aware adaptive learning. The model actively selects the most discriminative temporal segments under EFE guidance, enabling dynamic observation and information gain maximization. Meanwhile, sample weighting driven by predictive uncertainty mitigates the effects of label noise and distribution shift. Experiments on the SMG dataset demonstrate the effectiveness of the proposed method, achieving consistent improvements across multiple mainstream backbones. Ablation studies confirm that both the EFE-guided observation and the adaptive learning mechanism are crucial to the performance gains. This work offers an interpretable and scalable paradigm for temporal behavior modeling under low-resource and noisy conditions, with broad applicability to wearable sensing, HCI, and clinical emotion monitoring.
ForeDiffusion: Foresight-Conditioned Diffusion Policy via Future View Construction for Robot Manipulation
Jan 19, 2026Diffusion strategies have advanced visual motor control by progressively denoising high-dimensional action sequences, providing a promising method for robot manipulation. However, as task complexity increases, the success rate of existing baseline models decreases considerably. Analysis indicates that current diffusion strategies are confronted with two limitations. First, these strategies only rely on short-term observations as conditions. Second, the training objective remains limited to a single denoising loss, which leads to error accumulation and causes grasping deviations. To address these limitations, this paper proposes Foresight-Conditioned Diffusion (ForeDiffusion), by injecting the predicted future view representation into the diffusion process. As a result, the policy is guided to be forward-looking, enabling it to correct trajectory deviations. Following this design, ForeDiffusion employs a dual loss mechanism, combining the traditional denoising loss and the consistency loss of future observations, to achieve the unified optimization. Extensive evaluation on the Adroit suite and the MetaWorld benchmark demonstrates that ForeDiffusion achieves an average success rate of 80% for the overall task, significantly outperforming the existing mainstream diffusion methods by 23% in complex tasks, while maintaining more stable performance across the entire tasks.
A Two-Stage Lightweight Framework for Efficient Land-Air Bimodal Robot Autonomous Navigation
Jul 30, 2025
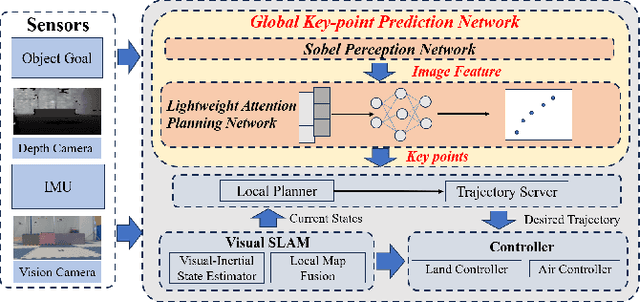
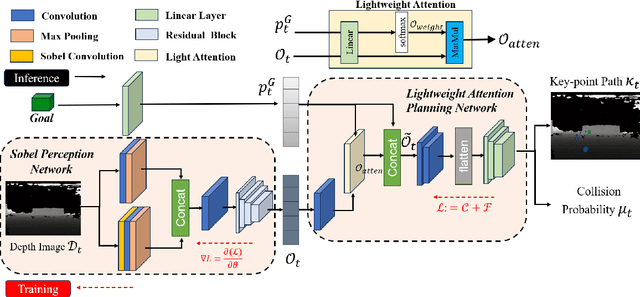
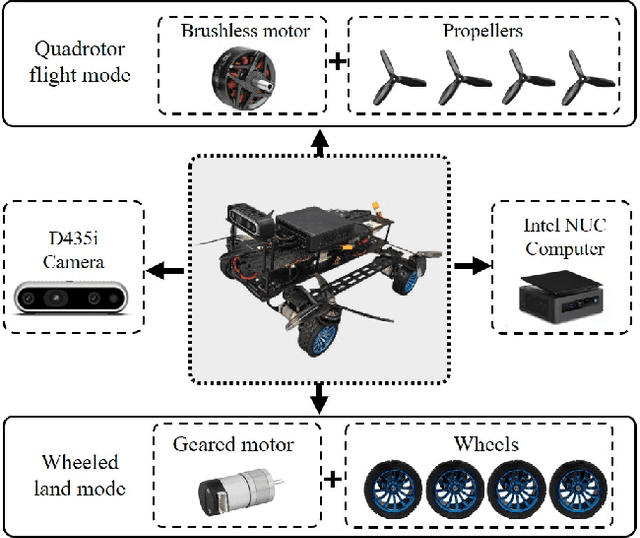
Land-air bimodal robots (LABR) are gaining attention for autonomous navigation, combining high mobility from aerial vehicles with long endurance from ground vehicles. However, existing LABR navigation methods are limited by suboptimal trajectories from mapping-based approaches and the excessive computational demands of learning-based methods. To address this, we propose a two-stage lightweight framework that integrates global key points prediction with local trajectory refinement to generate efficient and reachable trajectories. In the first stage, the Global Key points Prediction Network (GKPN) was used to generate a hybrid land-air keypoint path. The GKPN includes a Sobel Perception Network (SPN) for improved obstacle detection and a Lightweight Attention Planning Network (LAPN) to improves predictive ability by capturing contextual information. In the second stage, the global path is segmented based on predicted key points and refined using a mapping-based planner to create smooth, collision-free trajectories. Experiments conducted on our LABR platform show that our framework reduces network parameters by 14\% and energy consumption during land-air transitions by 35\% compared to existing approaches. The framework achieves real-time navigation without GPU acceleration and enables zero-shot transfer from simulation to reality during
Active Multimodal Distillation for Few-shot Action Recognition
Jun 16, 2025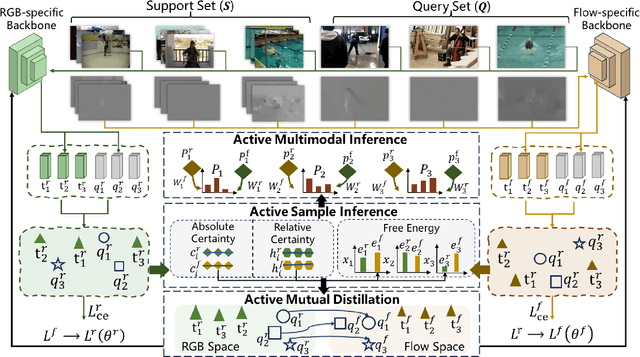
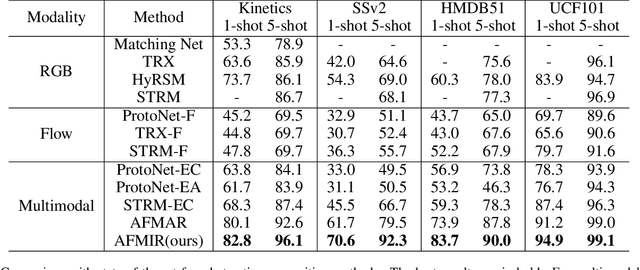
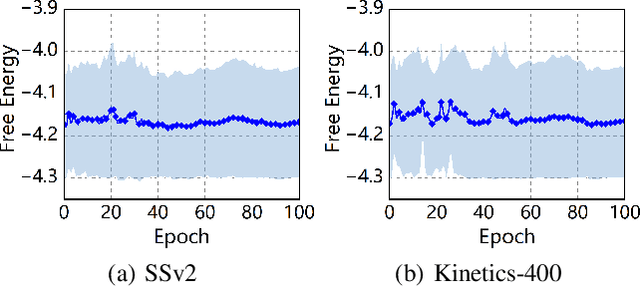
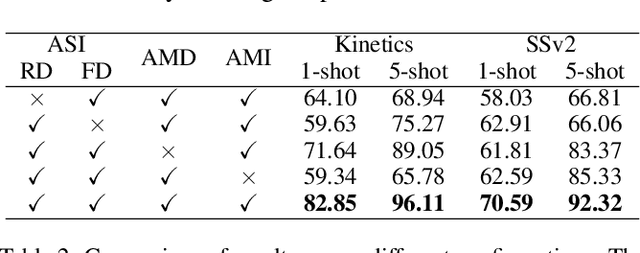
Owing to its rapid progress and broad application prospects, few-shot action recognition has attracted considerable interest. However, current methods are predominantly based on limited single-modal data, which does not fully exploit the potential of multimodal information. This paper presents a novel framework that actively identifies reliable modalities for each sample using task-specific contextual cues, thus significantly improving recognition performance. Our framework integrates an Active Sample Inference (ASI) module, which utilizes active inference to predict reliable modalities based on posterior distributions and subsequently organizes them accordingly. Unlike reinforcement learning, active inference replaces rewards with evidence-based preferences, making more stable predictions. Additionally, we introduce an active mutual distillation module that enhances the representation learning of less reliable modalities by transferring knowledge from more reliable ones. Adaptive multimodal inference is employed during the meta-test to assign higher weights to reliable modalities. Extensive experiments across multiple benchmarks demonstrate that our method significantly outperforms existing approaches.
RT-VC: Real-Time Zero-Shot Voice Conversion with Speech Articulatory Coding
Jun 12, 2025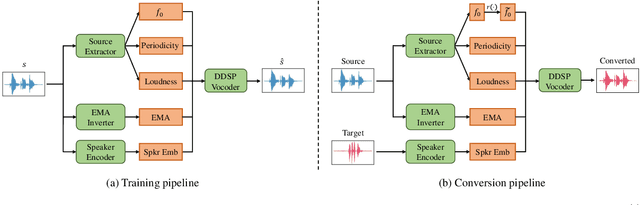


Voice conversion has emerged as a pivotal technology in numerous applications ranging from assistive communication to entertainment. In this paper, we present RT-VC, a zero-shot real-time voice conversion system that delivers ultra-low latency and high-quality performance. Our approach leverages an articulatory feature space to naturally disentangle content and speaker characteristics, facilitating more robust and interpretable voice transformations. Additionally, the integration of differentiable digital signal processing (DDSP) enables efficient vocoding directly from articulatory features, significantly reducing conversion latency. Experimental evaluations demonstrate that, while maintaining synthesis quality comparable to the current state-of-the-art (SOTA) method, RT-VC achieves a CPU latency of 61.4 ms, representing a 13.3\% reduction in latency.