 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Data Efficiency Dilemma: A Federated and Augmented Learning Framework For Alzheimer's Disease Detection via Speech
Feb 16, 2026Early diagnosis of Alzheimer's Disease (AD) is crucial for delaying its progression. While AI-based speech detection is non-invasive and cost-effective, it faces a critical data efficiency dilemma due to medical data scarcity and privacy barriers. Therefore, we propose FAL-AD, a novel framework that synergistically integrates federated learning with data augmentation to systematically optimize data efficiency. Our approach delivers three key breakthroughs: First, absolute efficiency improvement through voice conversion-based augmentation, which generates diverse pathological speech samples via cross-category voice-content recombination. Second, collaborative efficiency breakthrough via an adaptive federated learning paradigm, maximizing cross-institutional benefits under privacy constraints. Finally, representational efficiency optimization by an attentive cross-modal fusion model, which achieves fine-grained word-level alignment and acoustic-textual interaction. Evaluated on ADReSSo, FAL-AD achieves a state-of-the-art multi-modal accuracy of 91.52%, outperforming all centralized baselines and demonstrating a practical solution to the data efficiency dilemma. Our source code is publicly available at https://github.com/smileix/fal-ad.
Integration of Old and New Knowledge for Generalized Intent Discovery: A Consistency-driven Prototype-Prompting Framework
Jun 10, 2025Intent detection aims to identify user intents from natural language inputs, where supervised methods rely heavily on labeled in-domain (IND) data and struggle with out-of-domain (OOD) intents, limiting their practical applicability. Generalized Intent Discovery (GID) addresses this by leveraging unlabeled OOD data to discover new intents without additional annotation. However, existing methods focus solely on clustering unsupervised data while neglecting domain adaptation. Therefore, we propose a consistency-driven prototype-prompting framework for GID from the perspective of integrating old and new knowledge, which includes a prototype-prompting framework for transferring old knowledge from external sources, and a hierarchical consistency constraint for learning new knowledge from target domains. We conducted extensive experiments and the results show that our method significantly outperforms all baseline methods, achieving state-of-the-art results, which strongly demonstrates the effectiveness and generalization of our methods. Our source code is publicly available at https://github.com/smileix/cpp.
LAPP: Large Language Model Feedback for Preference-Driven Reinforcement Learning
Apr 21, 2025



We introduce Large Language Model-Assisted Preference Prediction (LAPP), a novel framework for robot learning that enables efficient, customizable, and expressive behavior acquisition with minimum human effort. Unlike prior approaches that rely heavily on reward engineering, human demonstrations, motion capture, or expensive pairwise preference labels, LAPP leverages large language models (LLMs) to automatically generate preference labels from raw state-action trajectories collected during reinforcement learning (RL). These labels are used to train an online preference predictor, which in turn guides the policy optimization process toward satisfying high-level behavioral specifications provided by humans. Our key technical contribution is the integration of LLMs into the RL feedback loop through trajectory-level preference prediction, enabling robots to acquire complex skills including subtle control over gait patterns and rhythmic timing. We evaluate LAPP on a diverse set of quadruped locomotion and dexterous manipulation tasks and show that it achieves efficient learning, higher final performance, faster adaptation, and precise control of high-level behaviors. Notably, LAPP enables robots to master highly dynamic and expressive tasks such as quadruped backflips, which remain out of reach for standard LLM-generated or handcrafted rewards. Our results highlight LAPP as a promising direction for scalable preference-driven robot learning.
ApolloRL: a Reinforcement Learning Platform for Autonomous Driving
Jan 29, 2022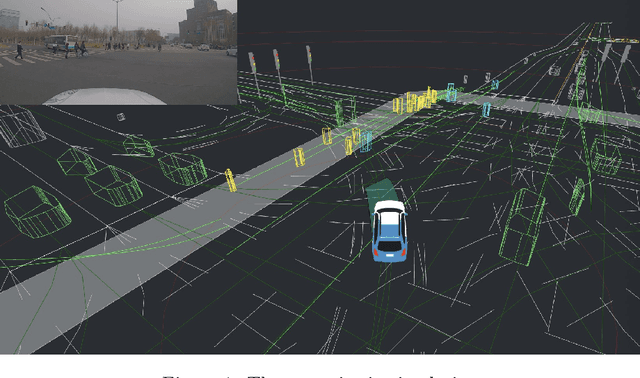
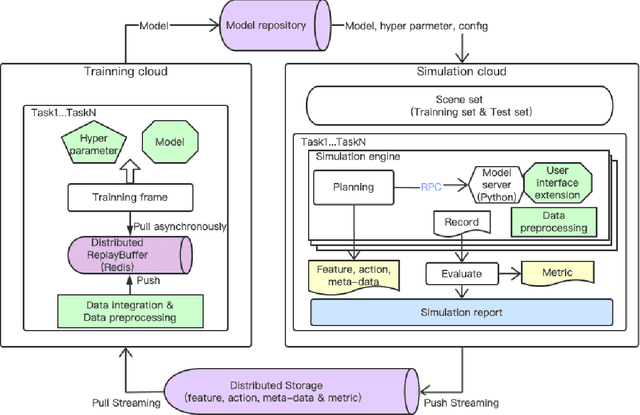
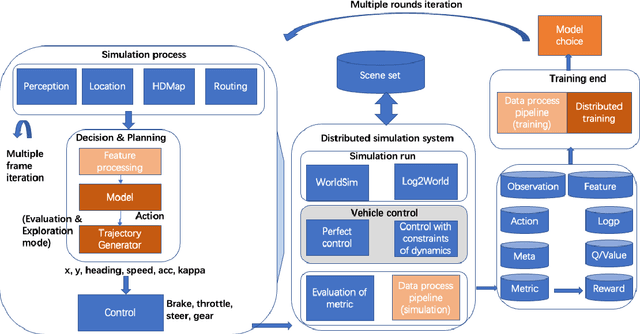

We introduce ApolloRL, an open platform for research in reinforcement learning for autonomous driving. The platform provides a complete closed-loop pipeline with training, simulation, and evaluation components. It comes with 300 hours of real-world data in driving scenarios and popular baselines such as Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC) agents. We elaborate in this paper on the architecture and the environment defined in the platform. In addition, we discuss the performance of the baseline agents in the ApolloRL environment.
Deep Active Learning for Efficient Training of a LiDAR 3D Object Detector
Jan 29, 2019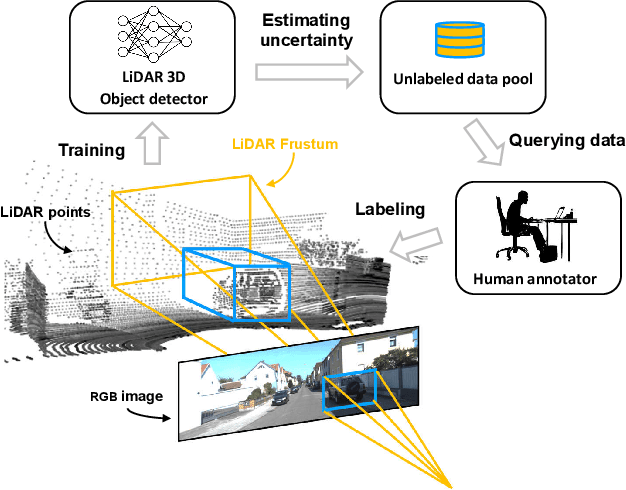
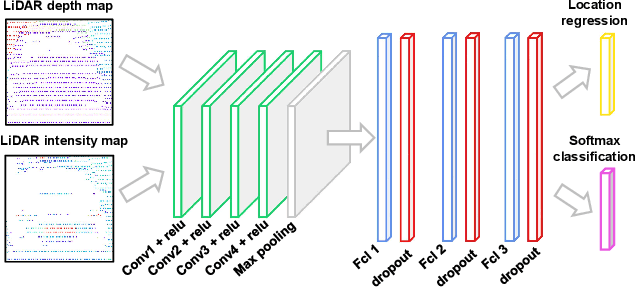
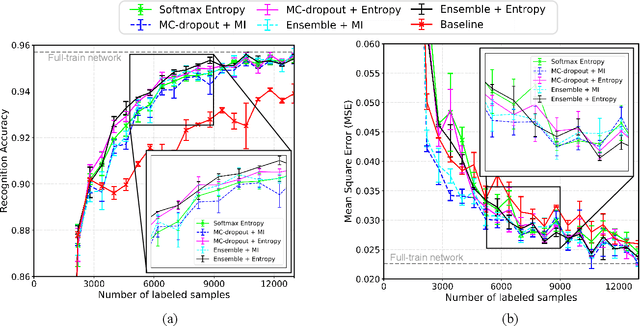

Training a deep object detector for autonomous driving requires a huge amount of labeled data. While recording data via on-board sensors such as camera or LiDAR is relatively easy, annotating data is very tedious and time-consuming, especially when dealing with 3D LiDAR points or radar data. Active learning has the potential to minimize human annotation efforts while maximizing the object detector's performance. In this work, we propose an active learning method to train a LiDAR 3D object detector with the least amount of labeled training data necessary. The detector leverages 2D region proposals generated from the RGB images to reduce the search space of objects and speed up the learning process. Experiments show that our proposed method works under different uncertainty estimations and query functions, and can save up to 60% of the labeling efforts while reaching the same network performance.
To Know Where We Are: Vision-Based Positioning in Outdoor Environments
Jun 19, 2015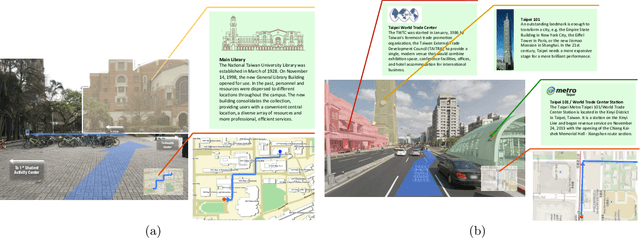
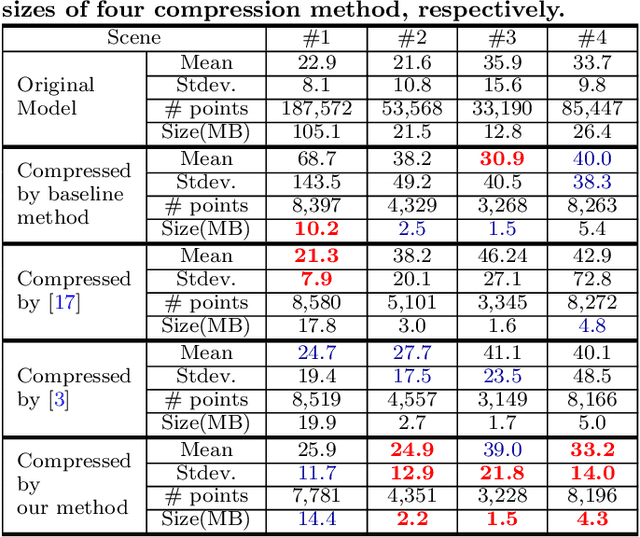
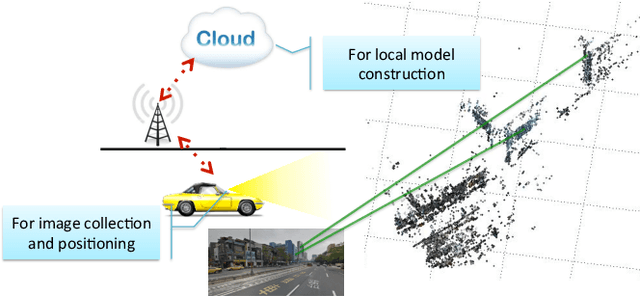
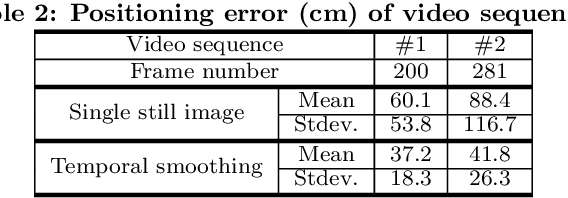
Augmented reality (AR) displays become more and more popular recently, because of its high intuitiveness for humans and high-quality head-mounted display have rapidly developed. To achieve such displays with augmented information, highly accurate image registration or ego-positioning are required, but little attention have been paid for out-door environments. This paper presents a method for ego-positioning in outdoor environments with low cost monocular cameras. To reduce the computational and memory requirements as well as the communication overheads, we formulate the model compression algorithm as a weighted k-cover problem for better preserving model structures. Specifically for real-world vision-based positioning applications, we consider the issues with large scene change and propose a model update algorithm to tackle these problems. A long- term positioning dataset with more than one month, 106 sessions, and 14,275 images is constructed. Based on both local and up-to-date models constructed in our approach, extensive experimental results show that high positioning accuracy (mean ~ 30.9cm, stdev. ~ 15.4cm) can be achieved, which outperforms existing vision-based algorithms.