 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Expressive Appropriateness of Speech in Rich Contexts
May 10, 2026Evaluating expressive speech remains challenging, as existing methods mainly assess emotional intensity and overlook whether a speech sample is expressively appropriate for its contextual setting. This limitation hinders reliable evaluation of speech systems used in narrative-driven and interactive applications, such as audiobooks and conversational agents. We introduce CEAEval, a Context-rich framework for Evaluating Expressive Appropriateness in speech, which assesses whether a speech sample expressively aligns with the underlying communicative intent implied by its discourse-level narrative context. To support this task, we construct CEAEval-D, the first context-rich speech dataset with real human performances in Mandarin conversational speech, providing narrative descriptions together with fifteen dimensions of human annotations covering expressive attributes and expressive appropriateness. We further develop CEAEval-M, a model that integrates knowledge distillation, planner-based multi-model collaboration, adaptive audio attention bias, and reinforcement learning to perform context-rich expressive appropriateness evaluation. Experiments on a human-annotated test set demonstrate that CEAEval-M substantially outperforms existing speech evaluation and analysis systems.
Compositional Multi-hop Factual Error Correction via Decomposition-and-Injection
May 04, 2026Factual Error Correction (FEC) aims to revise inaccurate text into statements that are factually consistent with external evidence. Although recent methods perform well on single-hop correction, they often treat claims as atomic units and struggle with multi-hop cases that require compositional reasoning across multiple evidence sources. This challenge is further amplified by limited paired data and difficulties in locating semantic errors within complex reasoning chains. We present CECoR (Compositional Error Correction via Reasoning-aware Synthesis), a reasoning-aware framework that introduces a Decomposition and Injection paradigm for compositional error correction. CECoR decomposes multi-hop claims into interpretable reasoning steps and injects controlled perturbations to synthesize high-quality training pairs. A two-stage learning strategy combining supervised fine-tuning and reinforcement learning improves factual accuracy and robustness. Comprehensive evaluations show that CECoR achieves strong performance on multi-hop benchmarks, outperforming both distantly supervised methods and few-shot LLM baselines. It also generalizes effectively to single-hop correction and remains stable under noisy evidence, demonstrating its versatility for real-world factual correction.
MSR-HuBERT: Self-supervised Pre-training for Adaptation to Multiple Sampling Rates
Mar 24, 2026Self-supervised learning (SSL) has advanced speech processing. However, existing speech SSL methods typically assume a single sampling rate and struggle with mixed-rate data due to temporal resolution mismatch. To address this limitation, we propose MSRHuBERT, a multi-sampling-rate adaptive pre-training method. Building on HuBERT, we replace its single-rate downsampling CNN with a multi-sampling-rate adaptive downsampling CNN that maps raw waveforms from different sampling rates to a shared temporal resolution without resampling. This design enables unified mixed-rate pre-training and fine-tuning. In experiments spanning 16 to 48 kHz, MSRHuBERT outperforms HuBERT on speech recognition and full-band speech reconstruction, preserving high-frequency detail while modeling low-frequency semantic structure. Moreover, MSRHuBERT retains HuBERT's mask-prediction objective and Transformer encoder, so existing analyses and improvements that were developed for HuBERT can apply directly.
From Subtle to Significant: Prompt-Driven Self-Improving Optimization in Test-Time Graph OOD Detection
Feb 19, 2026Graph Out-of-Distribution (OOD) detection aims to identify whether a test graph deviates from the distribution of graphs observed during training, which is critical for ensuring the reliability of Graph Neural Networks (GNNs) when deployed in open-world scenarios. Recent advances in graph OOD detection have focused on test-time training techniques that facilitate OOD detection without accessing potential supervisory information (e.g., training data). However, most of these methods employ a one-pass inference paradigm, which prevents them from progressively correcting erroneous predictions to amplify OOD signals. To this end, we propose a \textbf{S}elf-\textbf{I}mproving \textbf{G}raph \textbf{O}ut-\textbf{o}f-\textbf{D}istribution detector (SIGOOD), which is an unsupervised framework that integrates continuous self-learning with test-time training for effective graph OOD detection. Specifically, SIGOOD generates a prompt to construct a prompt-enhanced graph that amplifies potential OOD signals. To optimize prompts, SIGOOD introduces an Energy Preference Optimization (EPO) loss, which leverages energy variations between the original test graph and the prompt-enhanced graph. By iteratively optimizing the prompt by involving it into the detection model in a self-improving loop, the resulting optimal prompt-enhanced graph is ultimately used for OOD detection. Comprehensive evaluations on 21 real-world datasets confirm the effectiveness and outperformance of our SIGOOD method. The code is at https://github.com/Ee1s/SIGOOD.
Breaking Data Efficiency Dilemma: A Federated and Augmented Learning Framework For Alzheimer's Disease Detection via Speech
Feb 16, 2026Early diagnosis of Alzheimer's Disease (AD) is crucial for delaying its progression. While AI-based speech detection is non-invasive and cost-effective, it faces a critical data efficiency dilemma due to medical data scarcity and privacy barriers. Therefore, we propose FAL-AD, a novel framework that synergistically integrates federated learning with data augmentation to systematically optimize data efficiency. Our approach delivers three key breakthroughs: First, absolute efficiency improvement through voice conversion-based augmentation, which generates diverse pathological speech samples via cross-category voice-content recombination. Second, collaborative efficiency breakthrough via an adaptive federated learning paradigm, maximizing cross-institutional benefits under privacy constraints. Finally, representational efficiency optimization by an attentive cross-modal fusion model, which achieves fine-grained word-level alignment and acoustic-textual interaction. Evaluated on ADReSSo, FAL-AD achieves a state-of-the-art multi-modal accuracy of 91.52%, outperforming all centralized baselines and demonstrating a practical solution to the data efficiency dilemma. Our source code is publicly available at https://github.com/smileix/fal-ad.
One Prompt Fits All: Universal Graph Adaptation for Pretrained Models
Sep 26, 2025Graph Prompt Learning (GPL) has emerged as a promising paradigm that bridges graph pretraining models and downstream scenarios, mitigating label dependency and the misalignment between upstream pretraining and downstream tasks. Although existing GPL studies explore various prompt strategies, their effectiveness and underlying principles remain unclear. We identify two critical limitations: (1) Lack of consensus on underlying mechanisms: Despite current GPLs have advanced the field, there is no consensus on how prompts interact with pretrained models, as different strategies intervene at varying spaces within the model, i.e., input-level, layer-wise, and representation-level prompts. (2) Limited scenario adaptability: Most methods fail to generalize across diverse downstream scenarios, especially under data distribution shifts (e.g., homophilic-to-heterophilic graphs). To address these issues, we theoretically analyze existing GPL approaches and reveal that representation-level prompts essentially function as fine-tuning a simple downstream classifier, proposing that graph prompt learning should focus on unleashing the capability of pretrained models, and the classifier adapts to downstream scenarios. Based on our findings, we propose UniPrompt, a novel GPL method that adapts any pretrained models, unleashing the capability of pretrained models while preserving the structure of the input graph. Extensive experiments demonstrate that our method can effectively integrate with various pretrained models and achieve strong performance across in-domain and cross-domain scenarios.
Active Multimodal Distillation for Few-shot Action Recognition
Jun 16, 2025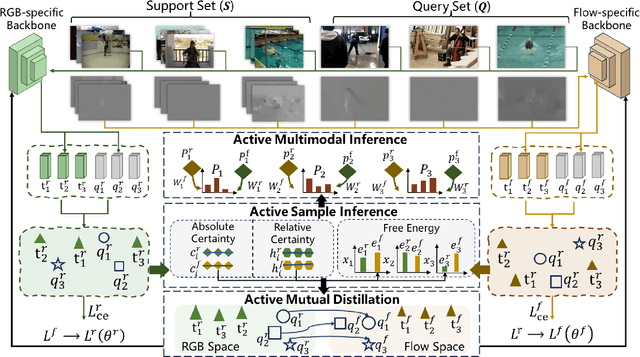
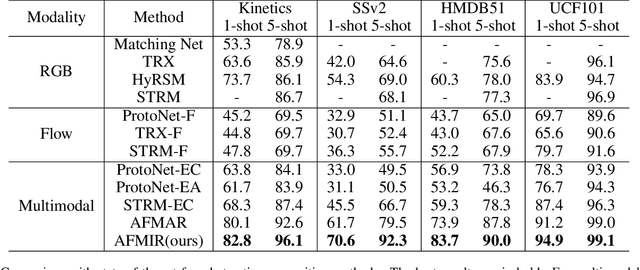
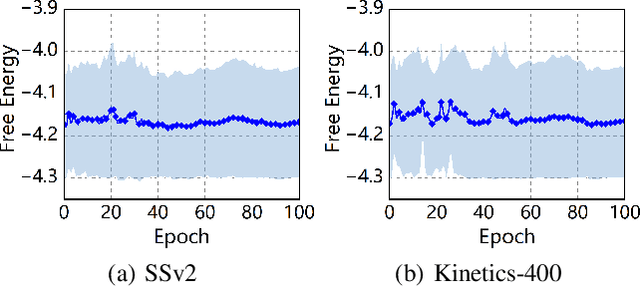
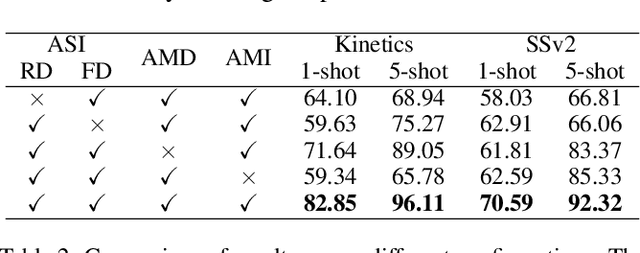
Owing to its rapid progress and broad application prospects, few-shot action recognition has attracted considerable interest. However, current methods are predominantly based on limited single-modal data, which does not fully exploit the potential of multimodal information. This paper presents a novel framework that actively identifies reliable modalities for each sample using task-specific contextual cues, thus significantly improving recognition performance. Our framework integrates an Active Sample Inference (ASI) module, which utilizes active inference to predict reliable modalities based on posterior distributions and subsequently organizes them accordingly. Unlike reinforcement learning, active inference replaces rewards with evidence-based preferences, making more stable predictions. Additionally, we introduce an active mutual distillation module that enhances the representation learning of less reliable modalities by transferring knowledge from more reliable ones. Adaptive multimodal inference is employed during the meta-test to assign higher weights to reliable modalities. Extensive experiments across multiple benchmarks demonstrate that our method significantly outperforms existing approaches.
Single-Node Trigger Backdoor Attacks in Graph-Based Recommendation Systems
Jun 10, 2025Graph recommendation systems have been widely studied due to their ability to effectively capture the complex interactions between users and items. However, these systems also exhibit certain vulnerabilities when faced with attacks. The prevailing shilling attack methods typically manipulate recommendation results by injecting a large number of fake nodes and edges. However, such attack strategies face two primary challenges: low stealth and high destructiveness. To address these challenges, this paper proposes a novel graph backdoor attack method that aims to enhance the exposure of target items to the target user in a covert manner, without affecting other unrelated nodes. Specifically, we design a single-node trigger generator, which can effectively expose multiple target items to the target user by inserting only one fake user node. Additionally, we introduce constraint conditions between the target nodes and irrelevant nodes to mitigate the impact of fake nodes on the recommendation system's performance. Experimental results show that the exposure of the target items reaches no less than 50% in 99% of the target users, while the impact on the recommendation system's performance is controlled within approximately 5%.
Integration of Old and New Knowledge for Generalized Intent Discovery: A Consistency-driven Prototype-Prompting Framework
Jun 10, 2025Intent detection aims to identify user intents from natural language inputs, where supervised methods rely heavily on labeled in-domain (IND) data and struggle with out-of-domain (OOD) intents, limiting their practical applicability. Generalized Intent Discovery (GID) addresses this by leveraging unlabeled OOD data to discover new intents without additional annotation. However, existing methods focus solely on clustering unsupervised data while neglecting domain adaptation. Therefore, we propose a consistency-driven prototype-prompting framework for GID from the perspective of integrating old and new knowledge, which includes a prototype-prompting framework for transferring old knowledge from external sources, and a hierarchical consistency constraint for learning new knowledge from target domains. We conducted extensive experiments and the results show that our method significantly outperforms all baseline methods, achieving state-of-the-art results, which strongly demonstrates the effectiveness and generalization of our methods. Our source code is publicly available at https://github.com/smileix/cpp.
Rethinking Contrastive Learning in Graph Anomaly Detection: A Clean-View Perspective
May 23, 2025Graph anomaly detection aims to identify unusual patterns in graph-based data, with wide applications in fields such as web security and financial fraud detection. Existing methods typically rely on contrastive learning, assuming that a lower similarity between a node and its local subgraph indicates abnormality. However, these approaches overlook a crucial limitation: the presence of interfering edges invalidates this assumption, since it introduces disruptive noise that compromises the contrastive learning process. Consequently, this limitation impairs the ability to effectively learn meaningful representations of normal patterns, leading to suboptimal detection performance. To address this issue, we propose a Clean-View Enhanced Graph Anomaly Detection framework (CVGAD), which includes a multi-scale anomaly awareness module to identify key sources of interference in the contrastive learning process. Moreover, to mitigate bias from the one-step edge removal process, we introduce a novel progressive purification module. This module incrementally refines the graph by iteratively identifying and removing interfering edges, thereby enhancing model performance. Extensive experiments on five benchmark datasets validate the effectiveness of our approach.