 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Mechanism of Catastrophic Forgetting: A Perspective from Gradient Similarity
Jan 29, 2026Catastrophic forgetting during knowledge injection severely undermines the continual learning capability of large language models (LLMs). Although existing methods attempt to mitigate this issue, they often lack a foundational theoretical explanation. We establish a gradient-based theoretical framework to explain catastrophic forgetting. We first prove that strongly negative gradient similarity is a fundamental cause of forgetting. We then use gradient similarity to identify two types of neurons: conflicting neurons that induce forgetting and account for 50%-75% of neurons, and collaborative neurons that mitigate forgetting and account for 25%-50%. Based on this analysis, we propose a knowledge injection method, Collaborative Neural Learning (CNL). By freezing conflicting neurons and updating only collaborative neurons, CNL theoretically eliminates catastrophic forgetting under an infinitesimal learning rate eta and an exactly known mastered set. Experiments on five LLMs, four datasets, and four optimizers show that CNL achieves zero forgetting in in-set settings and reduces forgetting by 59.1%-81.7% in out-of-set settings.
How Particle-System Random Batch Methods Enhance Graph Transformer: Memory Efficiency and Parallel Computing Strategy
Nov 08, 2025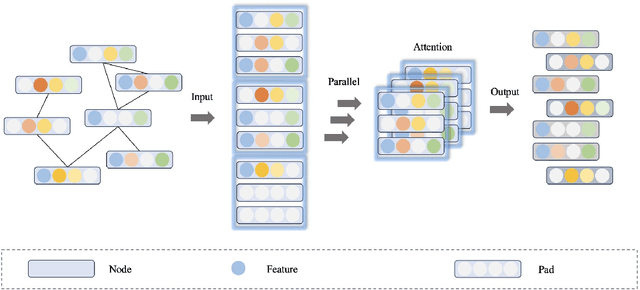


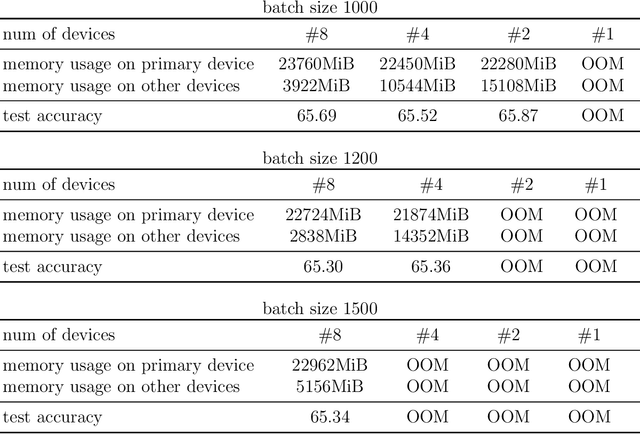
Attention mechanism is a significant part of Transformer models. It helps extract features from embedded vectors by adding global information and its expressivity has been proved to be powerful. Nevertheless, the quadratic complexity restricts its practicability. Although several researches have provided attention mechanism in sparse form, they are lack of theoretical analysis about the expressivity of their mechanism while reducing complexity. In this paper, we put forward Random Batch Attention (RBA), a linear self-attention mechanism, which has theoretical support of the ability to maintain its expressivity. Random Batch Attention has several significant strengths as follows: (1) Random Batch Attention has linear time complexity. Other than this, it can be implemented in parallel on a new dimension, which contributes to much memory saving. (2) Random Batch Attention mechanism can improve most of the existing models by replacing their attention mechanisms, even many previously improved attention mechanisms. (3) Random Batch Attention mechanism has theoretical explanation in convergence, as it comes from Random Batch Methods on computation mathematics. Experiments on large graphs have proved advantages mentioned above. Also, the theoretical modeling of self-attention mechanism is a new tool for future research on attention-mechanism analysis.
Progressive Residual Extraction based Pre-training for Speech Representation Learning
Aug 31, 2024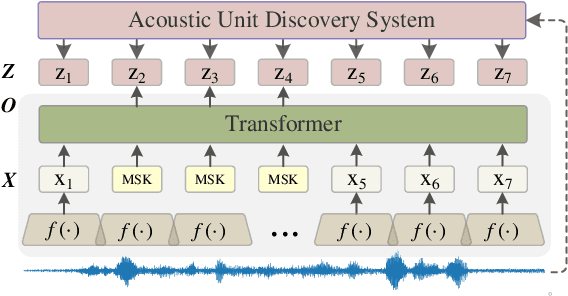
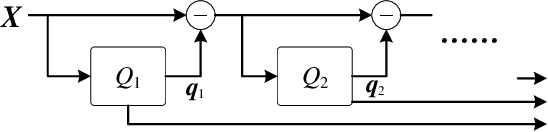
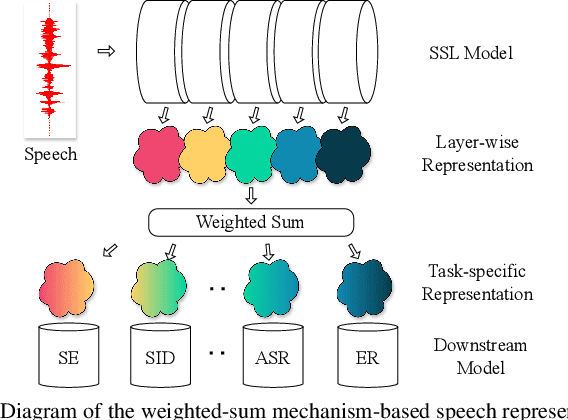
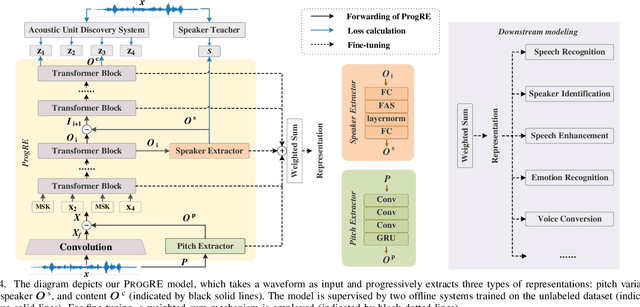
Self-supervised learning (SSL) has garnered significant attention in speech processing, excelling in linguistic tasks such as speech recognition. However, jointly improving the performance of pre-trained models on various downstream tasks, each requiring different speech information, poses significant challenges. To this purpose, we propose a progressive residual extraction based self-supervised learning method, named ProgRE. Specifically, we introduce two lightweight and specialized task modules into an encoder-style SSL backbone to enhance its ability to extract pitch variation and speaker information from speech. Furthermore, to prevent the interference of reinforced pitch variation and speaker information with irrelevant content information learning, we residually remove the information extracted by these two modules from the main branch. The main branch is then trained using HuBERT's speech masking prediction to ensure the performance of the Transformer's deep-layer features on content tasks. In this way, we can progressively extract pitch variation, speaker, and content representations from the input speech. Finally, we can combine multiple representations with diverse speech information using different layer weights to obtain task-specific representations for various downstream tasks. Experimental results indicate that our proposed method achieves joint performance improvements on various tasks, such as speaker identification, speech recognition, emotion recognition, speech enhancement, and voice conversion, compared to excellent SSL methods such as wav2vec2.0, HuBERT, and WavLM.
GROD: Enhancing Generalization of Transformer with Out-of-Distribution Detection
Jun 13, 2024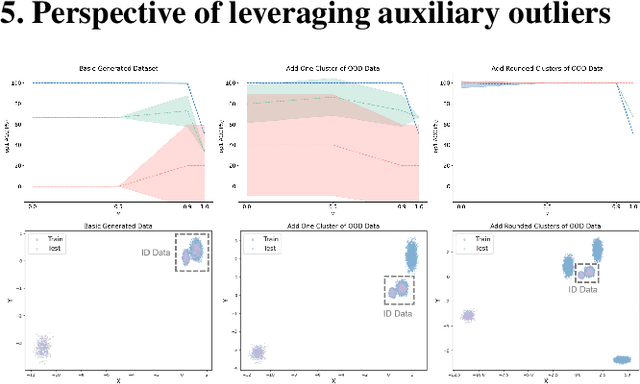
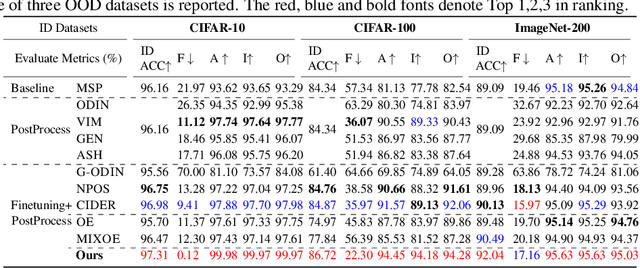
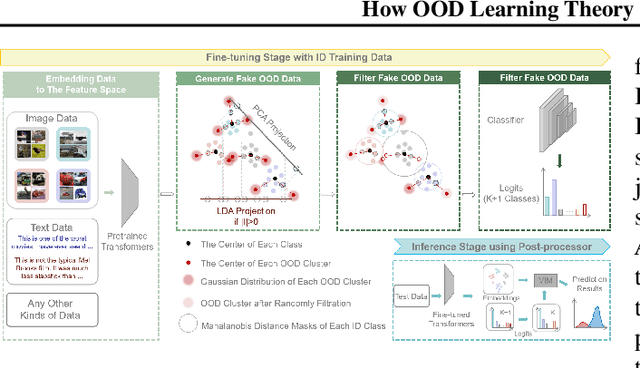

Transformer networks excel in natural language processing (NLP) and computer vision (CV) tasks. However, they face challenges in generalizing to Out-of-Distribution (OOD) datasets, that is, data whose distribution differs from that seen during training. The OOD detection aims to distinguish data that deviates from the expected distribution, while maintaining optimal performance on in-distribution (ID) data. This paper introduces a novel approach based on OOD detection, termed the Generate Rounded OOD Data (GROD) algorithm, which significantly bolsters the generalization performance of transformer networks across various tasks. GROD is motivated by our new OOD detection Probably Approximately Correct (PAC) Theory for transformer. The transformer has learnability in terms of OOD detection that is, when the data is sufficient the outlier can be well represented. By penalizing the misclassification of OOD data within the loss function and generating synthetic outliers, GROD guarantees learnability and refines the decision boundaries between inlier and outlier. This strategy demonstrates robust adaptability and general applicability across different data types. Evaluated across diverse OOD detection tasks in NLP and CV, GROD achieves SOTA regardless of data format. On average, it reduces the SOTA FPR@95 from 21.97% to 0.12%, and improves AUROC from 93.62% to 99.98% on image classification tasks, and the SOTA FPR@95 by 12.89% and AUROC by 2.27% in detecting semantic text outliers. The code is available at https://anonymous.4open.science/r/GROD-OOD-Detection-with-transformers-B70F.
Can neural networks learn persistent homology features?
Nov 30, 2020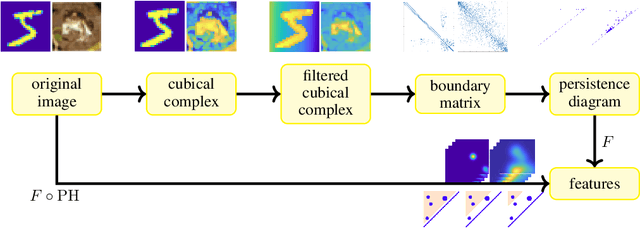
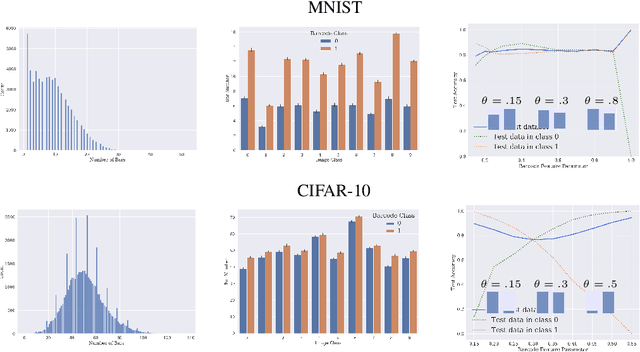
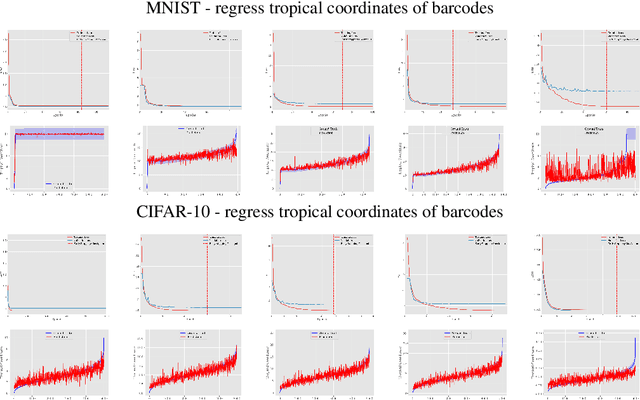
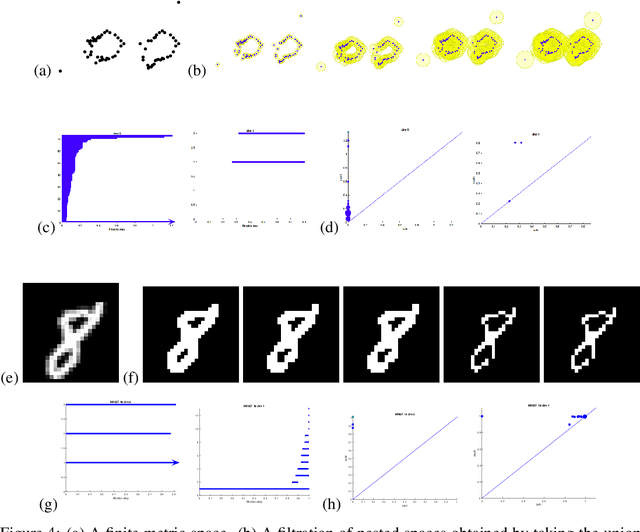
Topological data analysis uses tools from topology -- the mathematical area that studies shapes -- to create representations of data. In particular, in persistent homology, one studies one-parameter families of spaces associated with data, and persistence diagrams describe the lifetime of topological invariants, such as connected components or holes, across the one-parameter family. In many applications, one is interested in working with features associated with persistence diagrams rather than the diagrams themselves. In our work, we explore the possibility of learning several types of features extracted from persistence diagrams using neural networks.
PAN: Path Integral Based Convolution for Deep Graph Neural Networks
Apr 24, 2019
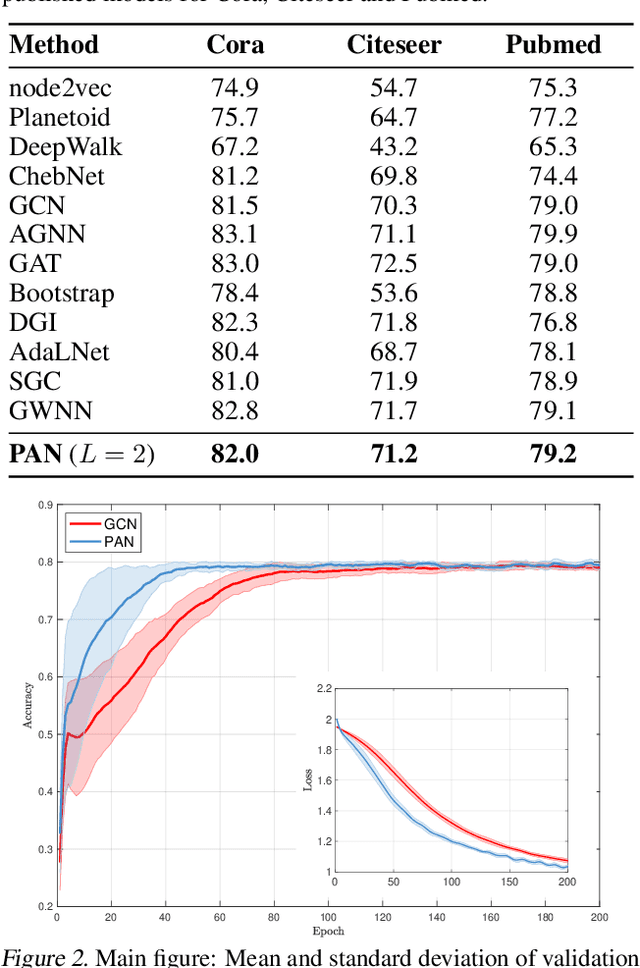
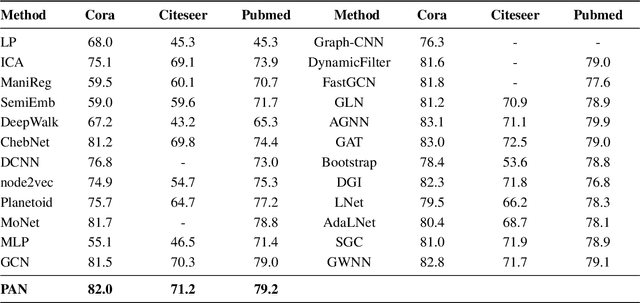
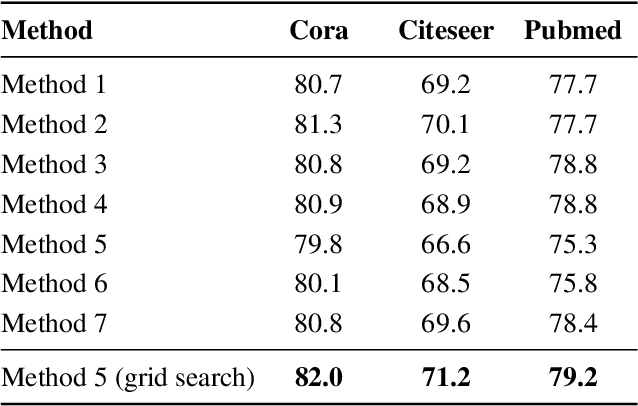
Convolution operations designed for graph-structured data usually utilize the graph Laplacian, which can be seen as message passing between the adjacent neighbors through a generic random walk. In this paper, we propose PAN, a new graph convolution framework that involves every path linking the message sender and receiver with learnable weights depending on the path length, which corresponds to the maximal entropy random walk. PAN generalizes the graph Laplacian to a new transition matrix we call \emph{maximal entropy transition} (MET) matrix derived from a path integral formalism. Most previous graph convolutional network architectures can be adapted to our framework, and many variations and derivatives based on the path integral idea can be developed. Experimental results show that the path integral based graph neural networks have great learnability and fast convergence rate, and achieve state-of-the-art performance on benchmark tasks.
A study on effectiveness of extreme learning machine
Sep 13, 2014
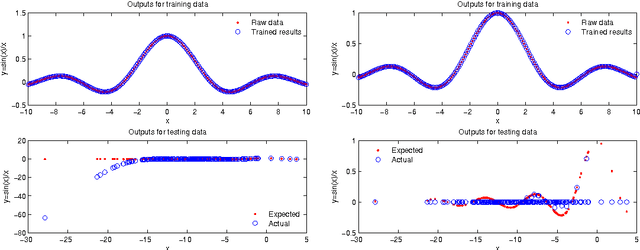


Extreme learning machine (ELM), proposed by Huang et al., has been shown a promising learning algorithm for single-hidden layer feedforward neural networks (SLFNs). Nevertheless, because of the random choice of input weights and biases, the ELM algorithm sometimes makes the hidden layer output matrix H of SLFN not full column rank, which lowers the effectiveness of ELM. This paper discusses the effectiveness of ELM and proposes an improved algorithm called EELM that makes a proper selection of the input weights and bias before calculating the output weights, which ensures the full column rank of H in theory. This improves to some extend the learning rate (testing accuracy, prediction accuracy, learning time) and the robustness property of the networks. The experimental results based on both the benchmark function approximation and real-world problems including classification and regression applications show the good performances of EELM.