 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Latent Optimization of Diffusion Models for Full Waveform Inversion
Jun 12, 2026Full waveform inversion (FWI) recovers subsurface velocity from seismic recordings by solving a severely ill-posed, nonconvex PDE-constrained optimization. Classical regularizers stabilize the inversion but fail to reproduce realistic geological structures; recent diffusion-prior methods improve realism at the cost of a fragile trade-off between data fidelity and prior consistency. We propose Decoupled Latent Optimization (DLO), which relaxes the standard latent-optimization formulation into a quadratic-penalty objective over an auxiliary physical variable and a latent variable. The data-fidelity gradient acts in physical space, the diffusion sampler contributes only through a decoded prior sample, and the standard smoothed-velocity initialization of classical FWI is preserved. On the OpenFWI benchmark, DLO outperforms classical regularizers and existing diffusion-based methods under clean, noisy, and missing-trace acquisitions. The prior, trained on 70*70 OpenFWI models, transfers directly to the Marmousi and Overthrust benchmarks, where DLO recovers intricate fault structures and remains robust to initialization smoothing and measurement noise.
GraphPI: Efficient Protein Inference with Graph Neural Networks
May 06, 2026The integration of deep learning approaches in biomedical research has been transformative, enabling breakthroughs in various applications. Despite these strides, its application in protein inference is impeded by the scarcity of extensively labeled datasets, a challenge compounded by the high costs and complexities of accurate protein annotation. In this study, we introduce GraphPI, a novel framework that treats protein inference as a node classification problem. We treat proteins as interconnected nodes within a protein-peptide-PSM graph, utilizing a Graph Neural Network-based architecture to elucidate their interrelations. To address label scarcity, we train the model on a set of unlabeled public protein datasets with pseudo-labels derived from an existing protein inference algorithm, enhanced by self-training to iteratively refine labels based on confidence scores. Contrary to prevalent methodologies necessitating dataset-specific training, our research illustrates that GraphPI, due to the well normalized nature of Percolator features, exhibits universal applicability without dataset-specific fine-tuning, a feature that not only mitigates the risk of overfitting but also enhances computational efficiency. Our empirical experiments reveal notable performance on various test datasets and deliver significantly reduced computation times compared to common protein inference algorithms.
OpenMobile: Building Open Mobile Agents with Task and Trajectory Synthesis
Apr 16, 2026Mobile agents powered by vision-language models have demonstrated impressive capabilities in automating mobile tasks, with recent leading models achieving a marked performance leap, e.g., nearly 70% success on AndroidWorld. However, these systems keep their training data closed and remain opaque about their task and trajectory synthesis recipes. We present OpenMobile, an open-source framework that synthesizes high-quality task instructions and agent trajectories, with two key components: (1) The first is a scalable task synthesis pipeline that constructs a global environment memory from exploration, then leverages it to generate diverse and grounded instructions. and (2) a policy-switching strategy for trajectory rollout. By alternating between learner and expert models, it captures essential error-recovery data often missing in standard imitation learning. Agents trained on our data achieve competitive results across three dynamic mobile agent benchmarks: notably, our fine-tuned Qwen2.5-VL and Qwen3-VL reach 51.7% and 64.7% on AndroidWorld, far surpassing existing open-data approaches. Furthermore, we conduct transparent analyses on the overlap between our synthetic instructions and benchmark test sets, and verify that performance gains stem from broad functionality coverage rather than benchmark overfitting. We release data and code at https://njucckevin.github.io/openmobile/ to bridge the data gap and facilitate broader mobile agent research.
FailureMem: A Failure-Aware Multimodal Framework for Autonomous Software Repair
Mar 18, 2026Multimodal Automated Program Repair (MAPR) extends traditional program repair by requiring models to jointly reason over source code, textual issue descriptions, and visual artifacts such as GUI screenshots. While recent LLM-based repair systems have shown promising results, existing approaches face several limitations: rigid workflow pipelines restrict exploration during debugging, visual reasoning is often performed over full-page screenshots without localized grounding, and failed repair attempts are rarely transformed into reusable knowledge. To address these challenges, we propose FailureMem, a multimodal repair framework that integrates three key mechanisms: a hybrid workflow-agent architecture that balances structured localization with flexible reasoning, active perception tools that enable region-level visual grounding, and a Failure Memory Bank that converts past repair attempts into reusable guidance. Experiments on SWE-bench Multimodal demonstrate FailureMem improves the resolved rate over GUIRepair by 3.7%.
Robust Physics-Guided Diffusion for Full-Waveform Inversion
Mar 17, 2026We develop a robust physics-guided diffusion framework for full-waveform inversion that combines a score-based generative prior with likelihood guidance computed through wave-equation simulations. We adopt a transport-based data-consistency potential (Wasserstein-2), incorporating wavefield enhancement via bounded weighting and observation-dependent normalization, thereby improving robustness to amplitude imbalance and time/phase misalignment. On the inference side, we introduce a preconditioned guided reverse-diffusion scheme that adapts the guidance strength and spatial scaling throughout the reverse-time dynamics, yielding a more stable and effective data-consistency guidance step than standard diffusion posterior sampling (DPS). Numerical experiments on OpenFWI datasets demonstrate improved reconstruction quality over deterministic optimization baselines and standard DPS under comparable computational budgets.
SSI-DM: Singularity Skipping Inversion of Diffusion Models
Feb 02, 2026Inverting real images into the noise space is essential for editing tasks using diffusion models, yet existing methods produce non-Gaussian noise with poor editability due to the inaccuracy in early noising steps. We identify the root cause: a mathematical singularity that renders inversion fundamentally ill-posed. We propose Singularity Skipping Inversion of Diffusion Models (SSI-DM), which bypasses this singular region by adding small noise before standard inversion. This simple approach produces inverted noise with natural Gaussian properties while maintaining reconstruction fidelity. As a plug-and-play technique compatible with general diffusion models, our method achieves superior performance on public image datasets for reconstruction and interpolation tasks, providing a principled and efficient solution to diffusion model inversion.
Empowering Small Language Models with Factual Hallucination-Aware Reasoning for Financial Classification
Jan 04, 2026Small language models (SLMs) are increasingly used for financial classification due to their fast inference and local deployability. However, compared with large language models, SLMs are more prone to factual hallucinations in reasoning and exhibit weaker classification performance. This raises a natural question: Can mitigating factual hallucinations improve SLMs' financial classification? To address this, we propose a three-step pipeline named AAAI (Association Identification, Automated Detection, and Adaptive Inference). Experiments on three representative SLMs reveal that: (1) factual hallucinations are positively correlated with misclassifications; (2) encoder-based verifiers effectively detect factual hallucinations; and (3) incorporating feedback on factual errors enables SLMs' adaptive inference that enhances classification performance. We hope this pipeline contributes to trustworthy and effective applications of SLMs in finance.
Towards Multiple Missing Values-resistant Unsupervised Graph Anomaly Detection
Nov 13, 2025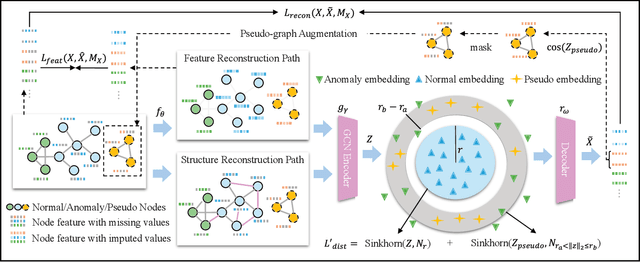
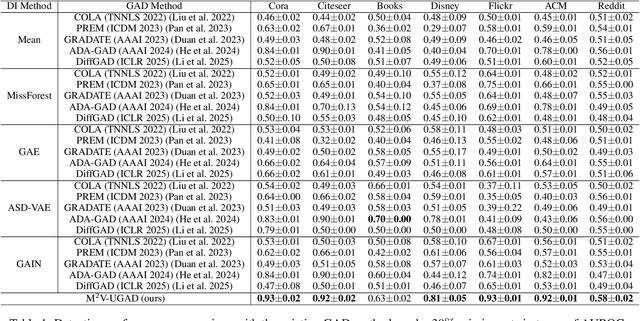
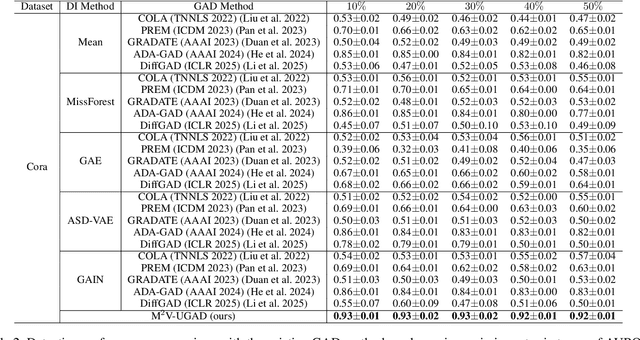

Unsupervised graph anomaly detection (GAD) has received increasing attention in recent years, which aims to identify data anomalous patterns utilizing only unlabeled node information from graph-structured data. However, prevailing unsupervised GAD methods typically presuppose complete node attributes and structure information, a condition hardly satisfied in real-world scenarios owing to privacy, collection errors or dynamic node arrivals. Existing standard imputation schemes risk "repairing" rare anomalous nodes so that they appear normal, thereby introducing imputation bias into the detection process. In addition, when both node attributes and edges are missing simultaneously, estimation errors in one view can contaminate the other, causing cross-view interference that further undermines the detection performance. To overcome these challenges, we propose M$^2$V-UGAD, a multiple missing values-resistant unsupervised GAD framework on incomplete graphs. Specifically, a dual-pathway encoder is first proposed to independently reconstruct missing node attributes and graph structure, thereby preventing errors in one view from propagating to the other. The two pathways are then fused and regularized in a joint latent space so that normals occupy a compact inner manifold while anomalies reside on an outer shell. Lastly, to mitigate imputation bias, we sample latent codes just outside the normal region and decode them into realistic node features and subgraphs, providing hard negative examples that sharpen the decision boundary. Experiments on seven public benchmarks demonstrate that M$^2$V-UGAD consistently outperforms existing unsupervised GAD methods across varying missing rates.
Towards Effective Open-set Graph Class-incremental Learning
Jul 23, 2025Graph class-incremental learning (GCIL) allows graph neural networks (GNNs) to adapt to evolving graph analytical tasks by incrementally learning new class knowledge while retaining knowledge of old classes. Existing GCIL methods primarily focus on a closed-set assumption, where all test samples are presumed to belong to previously known classes. Such an assumption restricts their applicability in real-world scenarios, where unknown classes naturally emerge during inference, and are absent during training. In this paper, we explore a more challenging open-set graph class-incremental learning scenario with two intertwined challenges: catastrophic forgetting of old classes, which impairs the detection of unknown classes, and inadequate open-set recognition, which destabilizes the retention of learned knowledge. To address the above problems, a novel OGCIL framework is proposed, which utilizes pseudo-sample embedding generation to effectively mitigate catastrophic forgetting and enable robust detection of unknown classes. To be specific, a prototypical conditional variational autoencoder is designed to synthesize node embeddings for old classes, enabling knowledge replay without storing raw graph data. To handle unknown classes, we employ a mixing-based strategy to generate out-of-distribution (OOD) samples from pseudo in-distribution and current node embeddings. A novel prototypical hypersphere classification loss is further proposed, which anchors in-distribution embeddings to their respective class prototypes, while repelling OOD embeddings away. Instead of assigning all unknown samples into one cluster, our proposed objective function explicitly models them as outliers through prototype-aware rejection regions, ensuring a robust open-set recognition. Extensive experiments on five benchmarks demonstrate the effectiveness of OGCIL over existing GCIL and open-set GNN methods.
Cognitive-Radio Functionality: A Novel Configuration for STAR-RIS assisted RSMA Networks
May 30, 2025Cognitive radio rate-splitting multiple access (CR-RSMA) has emerged as a promising multiple access framework that can efficiently manage interference and adapt dynamically to heterogeneous quality-of-service (QoS) requirements. To effectively support such demanding access schemes, programmable wireless environments have attracted considerable attention, especially through simultaneously transmitting and reflecting reconfigurable intelligent surfaces (STAR-RISs), which can enable full-space control of signal propagation in asymmetric user deployments. In this paper, we propose the cognitive radio (CR) functionality for STAR-RIS-assisted CR-RSMA systems, leveraging the unique capability of the STAR-RIS to combine element and power splitting for adaptive control of transmission and reflection in CR scenarios. Specifically, the proposed CR functionality partitions the STAR-RIS into two regions independently controlling the transmission and reflection of signals, simultaneously ensuring the required QoS for the primary user and enhancing the performance of the secondary user. To accurately characterize the system performance, we derive analytical expressions for the ergodic rate of the secondary user and the outage rate of the primary user under Nakagami-m fading. Finally, simulation results show that the proposed approach effectively manages interference, guarantees the QoS of the primary user, and significantly improves the throughput of the secondary user, highlighting STAR-RIS as an efficient solution for CR-RSMA-based services.