 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenMobile: Building Open Mobile Agents with Task and Trajectory Synthesis
Apr 16, 2026Mobile agents powered by vision-language models have demonstrated impressive capabilities in automating mobile tasks, with recent leading models achieving a marked performance leap, e.g., nearly 70% success on AndroidWorld. However, these systems keep their training data closed and remain opaque about their task and trajectory synthesis recipes. We present OpenMobile, an open-source framework that synthesizes high-quality task instructions and agent trajectories, with two key components: (1) The first is a scalable task synthesis pipeline that constructs a global environment memory from exploration, then leverages it to generate diverse and grounded instructions. and (2) a policy-switching strategy for trajectory rollout. By alternating between learner and expert models, it captures essential error-recovery data often missing in standard imitation learning. Agents trained on our data achieve competitive results across three dynamic mobile agent benchmarks: notably, our fine-tuned Qwen2.5-VL and Qwen3-VL reach 51.7% and 64.7% on AndroidWorld, far surpassing existing open-data approaches. Furthermore, we conduct transparent analyses on the overlap between our synthetic instructions and benchmark test sets, and verify that performance gains stem from broad functionality coverage rather than benchmark overfitting. We release data and code at https://njucckevin.github.io/openmobile/ to bridge the data gap and facilitate broader mobile agent research.
GRRM: Group Relative Reward Modeling for Machine Translation
Feb 15, 2026While Group Relative Policy Optimization (GRPO) offers a powerful framework for LLM post-training, its effectiveness in open-ended domains like Machine Translation hinges on accurate intra-group ranking. We identify that standard Scalar Quality Metrics (SQM) fall short in this context; by evaluating candidates in isolation, they lack the comparative context necessary to distinguish fine-grained linguistic nuances. To address this, we introduce the Group Quality Metric (GQM) paradigm and instantiate it via the Group Relative Reward Model (GRRM). Unlike traditional independent scorers, GRRM processes the entire candidate group jointly, leveraging comparative analysis to rigorously resolve relative quality and adaptive granularity. Empirical evaluations confirm that GRRM achieves competitive ranking accuracy among all baselines. Building on this foundation, we integrate GRRM into the GRPO training loop to optimize the translation policy. Experimental results demonstrate that our framework not only improves general translation quality but also unlocks reasoning capabilities comparable to state-of-the-art reasoning models. We release codes, datasets, and model checkpoints at https://github.com/NJUNLP/GRRM.
Enhancing Spatial Reasoning in Large Language Models for Metal-Organic Frameworks Structure Prediction
Jan 14, 2026Metal-organic frameworks (MOFs) are porous crystalline materials with broad applications such as carbon capture and drug delivery, yet accurately predicting their 3D structures remains a significant challenge. While Large Language Models (LLMs) have shown promise in generating crystals, their application to MOFs is hindered by MOFs' high atomic complexity. Inspired by the success of block-wise paradigms in deep generative models, we pioneer the use of LLMs in this domain by introducing MOF-LLM, the first LLM framework specifically adapted for block-level MOF structure prediction. To effectively harness LLMs for this modular assembly task, our training paradigm integrates spatial-aware continual pre-training (CPT), structural supervised fine-tuning (SFT), and matching-driven reinforcement learning (RL). By incorporating explicit spatial priors and optimizing structural stability via Soft Adaptive Policy Optimization (SAPO), our approach substantially enhances the spatial reasoning capability of a Qwen-3 8B model for accurate MOF structure prediction. Comprehensive experiments demonstrate that MOF-LLM outperforms state-of-the-art denoising-based and LLM-based methods while exhibiting superior sampling efficiency.
CapArena: Benchmarking and Analyzing Detailed Image Captioning in the LLM Era
Mar 16, 2025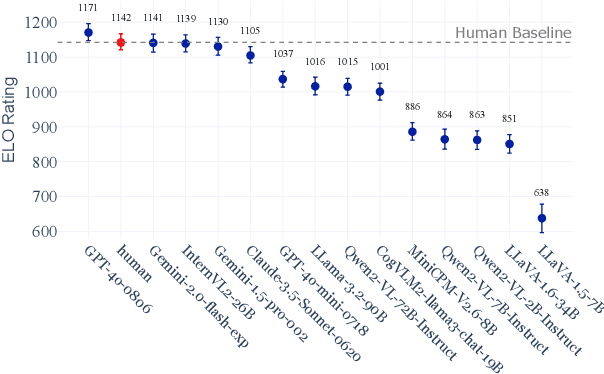

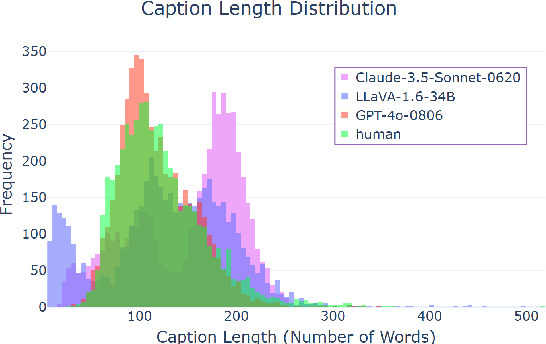
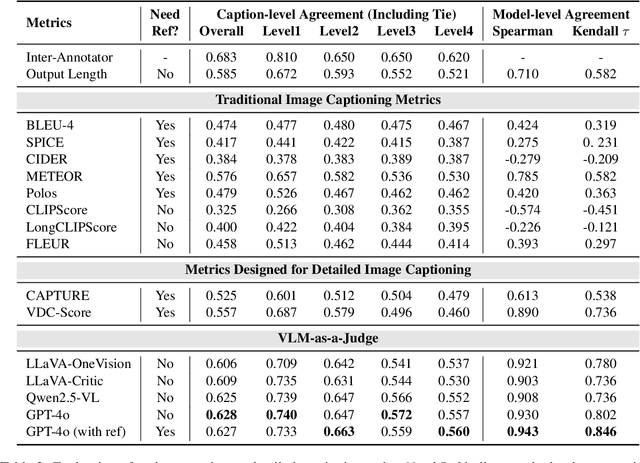
Image captioning has been a longstanding challenge in vision-language research. With the rise of LLMs, modern Vision-Language Models (VLMs) generate detailed and comprehensive image descriptions. However, benchmarking the quality of such captions remains unresolved. This paper addresses two key questions: (1) How well do current VLMs actually perform on image captioning, particularly compared to humans? We built CapArena, a platform with over 6000 pairwise caption battles and high-quality human preference votes. Our arena-style evaluation marks a milestone, showing that leading models like GPT-4o achieve or even surpass human performance, while most open-source models lag behind. (2) Can automated metrics reliably assess detailed caption quality? Using human annotations from CapArena, we evaluate traditional and recent captioning metrics, as well as VLM-as-a-Judge. Our analysis reveals that while some metrics (e.g., METEOR) show decent caption-level agreement with humans, their systematic biases lead to inconsistencies in model ranking. In contrast, VLM-as-a-Judge demonstrates robust discernment at both the caption and model levels. Building on these insights, we release CapArena-Auto, an accurate and efficient automated benchmark for detailed captioning, achieving 94.3% correlation with human rankings at just $4 per test. Data and resources will be open-sourced at https://caparena.github.io.
MoMa: A Modular Deep Learning Framework for Material Property Prediction
Feb 21, 2025



Deep learning methods for material property prediction have been widely explored to advance materials discovery. However, the prevailing pre-train then fine-tune paradigm often fails to address the inherent diversity and disparity of material tasks. To overcome these challenges, we introduce MoMa, a Modular framework for Materials that first trains specialized modules across a wide range of tasks and then adaptively composes synergistic modules tailored to each downstream scenario. Evaluation across 17 datasets demonstrates the superiority of MoMa, with a substantial 14% average improvement over the strongest baseline. Few-shot and continual learning experiments further highlight MoMa's potential for real-world applications. Pioneering a new paradigm of modular material learning, MoMa will be open-sourced to foster broader community collaboration.
A Periodic Bayesian Flow for Material Generation
Feb 04, 2025



Generative modeling of crystal data distribution is an important yet challenging task due to the unique periodic physical symmetry of crystals. Diffusion-based methods have shown early promise in modeling crystal distribution. More recently, Bayesian Flow Networks were introduced to aggregate noisy latent variables, resulting in a variance-reduced parameter space that has been shown to be advantageous for modeling Euclidean data distributions with structural constraints (Song et al., 2023). Inspired by this, we seek to unlock its potential for modeling variables located in non-Euclidean manifolds e.g. those within crystal structures, by overcoming challenging theoretical issues. We introduce CrysBFN, a novel crystal generation method by proposing a periodic Bayesian flow, which essentially differs from the original Gaussian-based BFN by exhibiting non-monotonic entropy dynamics. To successfully realize the concept of periodic Bayesian flow, CrysBFN integrates a new entropy conditioning mechanism and empirically demonstrates its significance compared to time-conditioning. Extensive experiments over both crystal ab initio generation and crystal structure prediction tasks demonstrate the superiority of CrysBFN, which consistently achieves new state-of-the-art on all benchmarks. Surprisingly, we found that CrysBFN enjoys a significant improvement in sampling efficiency, e.g., ~100x speedup 10 v.s. 2000 steps network forwards) compared with previous diffusion-based methods on MP-20 dataset. Code is available at https://github.com/wu-han-lin/CrysBFN.
Rethinking Relation Extraction: Beyond Shortcuts to Generalization with a Debiased Benchmark
Jan 02, 2025



Benchmarks are crucial for evaluating machine learning algorithm performance, facilitating comparison and identifying superior solutions. However, biases within datasets can lead models to learn shortcut patterns, resulting in inaccurate assessments and hindering real-world applicability. This paper addresses the issue of entity bias in relation extraction tasks, where models tend to rely on entity mentions rather than context. We propose a debiased relation extraction benchmark DREB that breaks the pseudo-correlation between entity mentions and relation types through entity replacement. DREB utilizes Bias Evaluator and PPL Evaluator to ensure low bias and high naturalness, providing a reliable and accurate assessment of model generalization in entity bias scenarios. To establish a new baseline on DREB, we introduce MixDebias, a debiasing method combining data-level and model training-level techniques. MixDebias effectively improves model performance on DREB while maintaining performance on the original dataset. Extensive experiments demonstrate the effectiveness and robustness of MixDebias compared to existing methods, highlighting its potential for improving the generalization ability of relation extraction models. We will release DREB and MixDebias publicly.
Vision-Language Models Can Self-Improve Reasoning via Reflection
Oct 30, 2024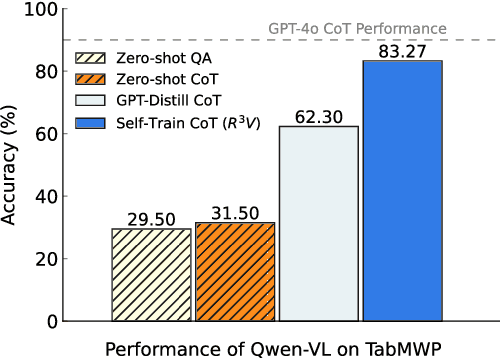
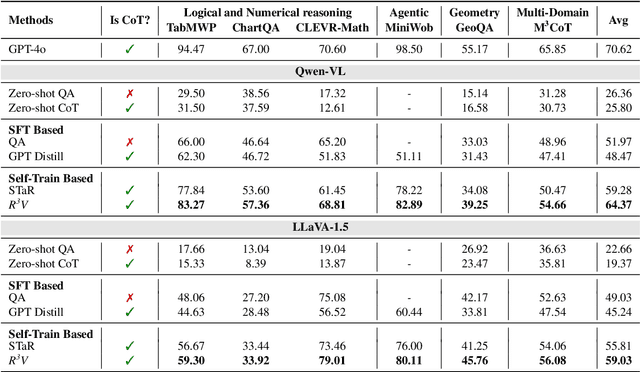
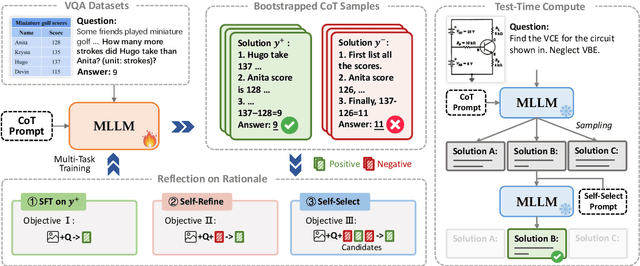
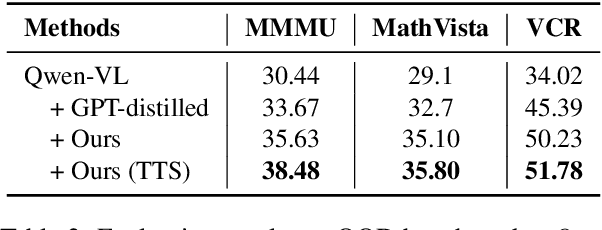
Chain-of-thought (CoT) has proven to improve the reasoning capability of large language models (LLMs). However, due to the complexity of multimodal scenarios and the difficulty in collecting high-quality CoT data, CoT reasoning in multimodal LLMs has been largely overlooked. To this end, we propose a simple yet effective self-training framework, R3V, which iteratively enhances the model's Vision-language Reasoning by Reflecting on CoT Rationales. Our framework consists of two interleaved parts: (1) iteratively bootstrapping positive and negative solutions for reasoning datasets, and (2) reflection on rationale for learning from mistakes. Specifically, we introduce the self-refine and self-select losses, enabling the model to refine flawed rationale and derive the correct answer by comparing rationale candidates. Experiments on a wide range of vision-language tasks show that R3V consistently improves multimodal LLM reasoning, achieving a relative improvement of 23 to 60 percent over GPT-distilled baselines. Additionally, our approach supports self-reflection on generated solutions, further boosting performance through test-time computation.
The Devil is in the Few Shots: Iterative Visual Knowledge Completion for Few-shot Learning
Apr 19, 2024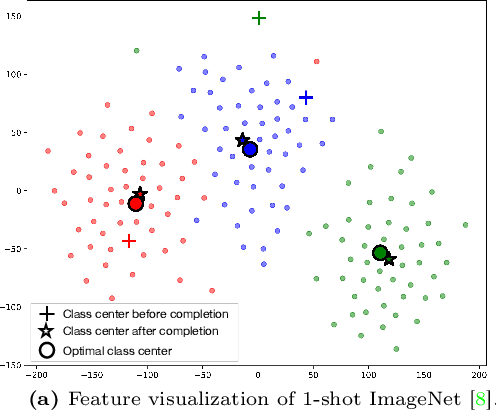
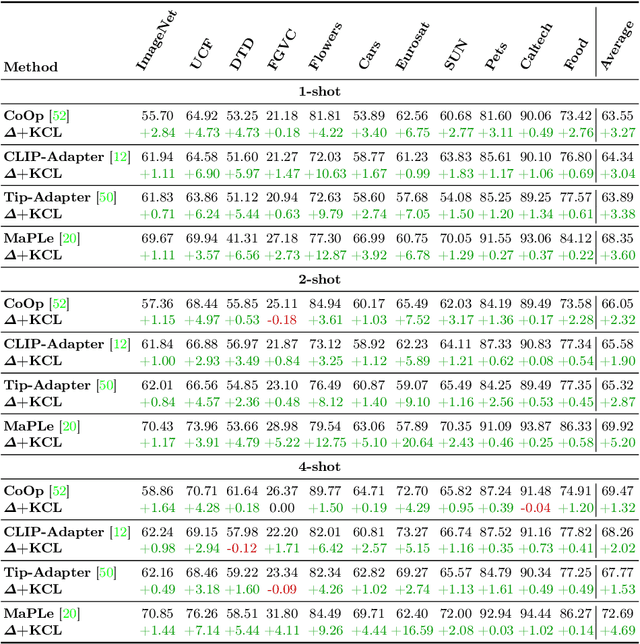
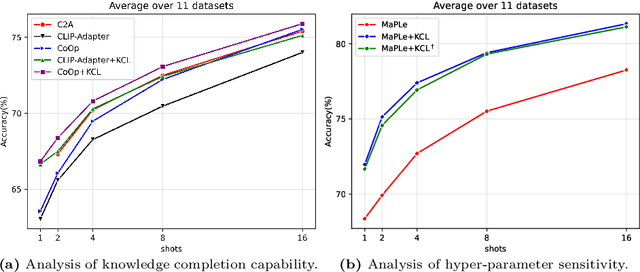
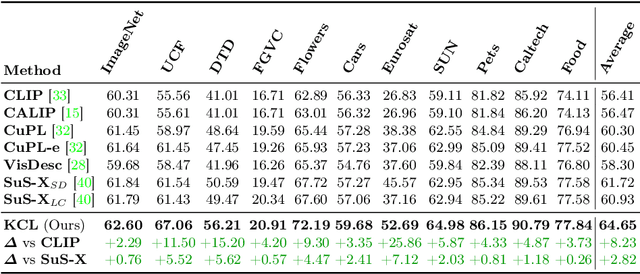
Contrastive Language-Image Pre-training (CLIP) has shown powerful zero-shot learning performance. Few-shot learning aims to further enhance the transfer capability of CLIP by giving few images in each class, aka 'few shots'. Most existing methods either implicitly learn from the few shots by incorporating learnable prompts or adapters, or explicitly embed them in a cache model for inference. However, the narrow distribution of few shots often contains incomplete class information, leading to biased visual knowledge with high risk of misclassification. To tackle this problem, recent methods propose to supplement visual knowledge by generative models or extra databases, which can be costly and time-consuming. In this paper, we propose an Iterative Visual Knowledge CompLetion (KCL) method to complement visual knowledge by properly taking advantages of unlabeled samples without access to any auxiliary or synthetic data. Specifically, KCL first measures the similarities between unlabeled samples and each category. Then, the samples with top confidence to each category is selected and collected by a designed confidence criterion. Finally, the collected samples are treated as labeled ones and added to few shots to jointly re-estimate the remaining unlabeled ones. The above procedures will be repeated for a certain number of iterations with more and more samples being collected until convergence, ensuring a progressive and robust knowledge completion process. Extensive experiments on 11 benchmark datasets demonstrate the effectiveness and efficiency of KCL as a plug-and-play module under both few-shot and zero-shot learning settings. Code is available at https://github.com/Mark-Sky/KCL.
MixRED: A Mix-lingual Relation Extraction Dataset
Mar 23, 2024
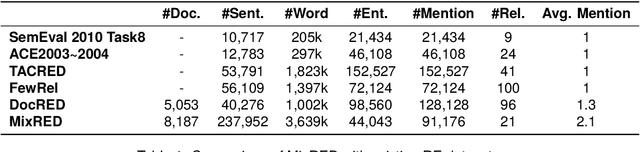
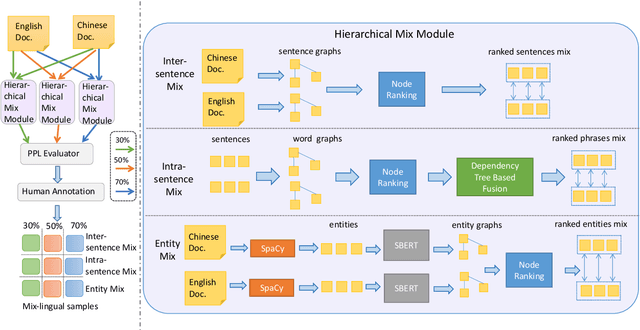
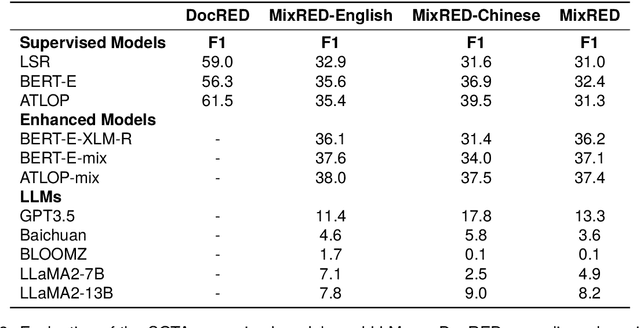
Relation extraction is a critical task in the field of natural language processing with numerous real-world applications. Existing research primarily focuses on monolingual relation extraction or cross-lingual enhancement for relation extraction. Yet, there remains a significant gap in understanding relation extraction in the mix-lingual (or code-switching) scenario, where individuals intermix contents from different languages within sentences, generating mix-lingual content. Due to the lack of a dedicated dataset, the effectiveness of existing relation extraction models in such a scenario is largely unexplored. To address this issue, we introduce a novel task of considering relation extraction in the mix-lingual scenario called MixRE and constructing the human-annotated dataset MixRED to support this task. In addition to constructing the MixRED dataset, we evaluate both state-of-the-art supervised models and large language models (LLMs) on MixRED, revealing their respective advantages and limitations in the mix-lingual scenario. Furthermore, we delve into factors influencing model performance within the MixRE task and uncover promising directions for enhancing the performance of both supervised models and LLMs in this novel task.