 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyprefer: An Agentic Framework for Preference Data Synthesis
Apr 27, 2025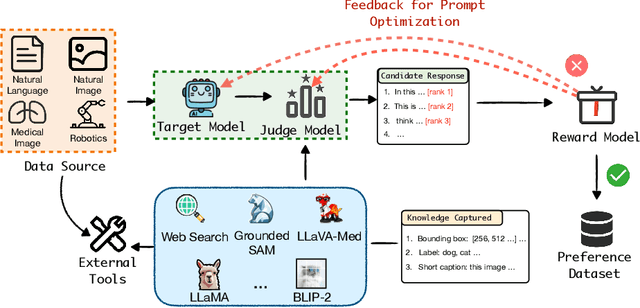
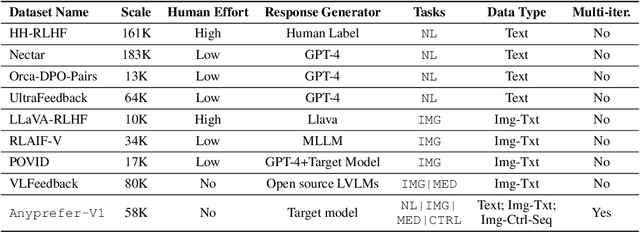
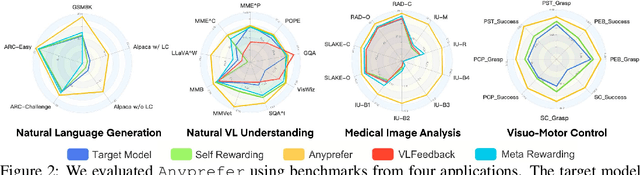
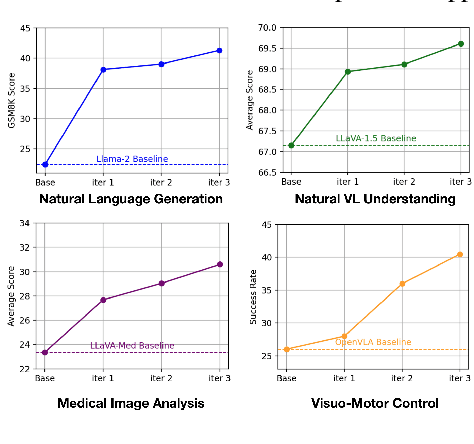
High-quality preference data is essential for aligning foundation models with human values through preference learning. However, manual annotation of such data is often time-consuming and costly. Recent methods often adopt a self-rewarding approach, where the target model generates and annotates its own preference data, but this can lead to inaccuracies since the reward model shares weights with the target model, thereby amplifying inherent biases. To address these issues, we propose Anyprefer, a framework designed to synthesize high-quality preference data for aligning the target model. Anyprefer frames the data synthesis process as a cooperative two-player Markov Game, where the target model and the judge model collaborate together. Here, a series of external tools are introduced to assist the judge model in accurately rewarding the target model's responses, mitigating biases in the rewarding process. In addition, a feedback mechanism is introduced to optimize prompts for both models, enhancing collaboration and improving data quality. The synthesized data is compiled into a new preference dataset, Anyprefer-V1, consisting of 58K high-quality preference pairs. Extensive experiments show that Anyprefer significantly improves model alignment performance across four main applications, covering 21 datasets, achieving average improvements of 18.55% in five natural language generation datasets, 3.66% in nine vision-language understanding datasets, 30.05% in three medical image analysis datasets, and 16.00% in four visuo-motor control tasks.
GePBench: Evaluating Fundamental Geometric Perception for Multimodal Large Language Models
Dec 30, 2024
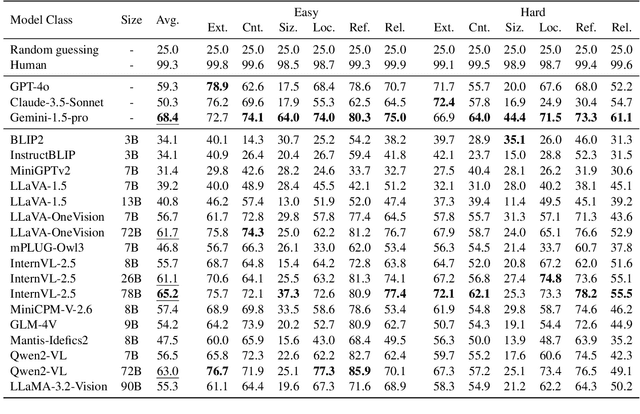


Multimodal large language models (MLLMs) have achieved significant advancements in integrating visual and linguistic understanding. While existing benchmarks evaluate these models in context-rich, real-life scenarios, they often overlook fundamental perceptual skills essential for environments deviating from everyday realism. In particular, geometric perception, the ability to interpret spatial relationships and abstract visual patterns, remains underexplored. To address this limitation, we introduce GePBench, a novel benchmark designed to assess the geometric perception capabilities of MLLMs. Results from extensive evaluations reveal that current state-of-the-art MLLMs exhibit significant deficiencies in such tasks. Additionally, we demonstrate that models trained with data sourced from GePBench show notable improvements on a wide range of downstream tasks, underscoring the importance of geometric perception as a foundation for advanced multimodal applications. Our code and datasets will be publicly available.
AlignGPT: Multi-modal Large Language Models with Adaptive Alignment Capability
May 23, 2024

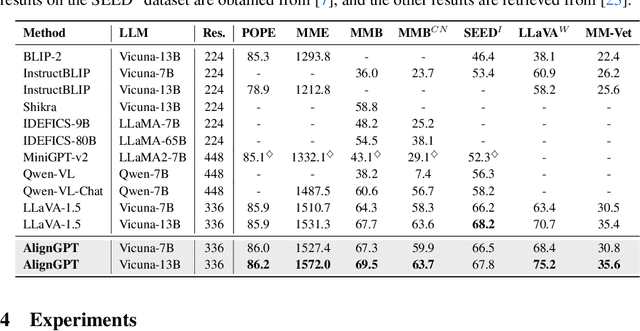
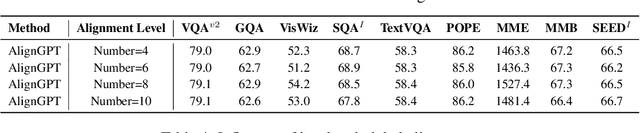
Multimodal Large Language Models (MLLMs) are widely regarded as crucial in the exploration of Artificial General Intelligence (AGI). The core of MLLMs lies in their capability to achieve cross-modal alignment. To attain this goal, current MLLMs typically follow a two-phase training paradigm: the pre-training phase and the instruction-tuning phase. Despite their success, there are shortcomings in the modeling of alignment capabilities within these models. Firstly, during the pre-training phase, the model usually assumes that all image-text pairs are uniformly aligned, but in fact the degree of alignment between different image-text pairs is inconsistent. Secondly, the instructions currently used for finetuning incorporate a variety of tasks, different tasks's instructions usually require different levels of alignment capabilities, but previous MLLMs overlook these differentiated alignment needs. To tackle these issues, we propose a new multimodal large language model AlignGPT. In the pre-training stage, instead of treating all image-text pairs equally, we assign different levels of alignment capabilities to different image-text pairs. Then, in the instruction-tuning phase, we adaptively combine these different levels of alignment capabilities to meet the dynamic alignment needs of different instructions. Extensive experimental results show that our model achieves competitive performance on 12 benchmarks.
EFUF: Efficient Fine-grained Unlearning Framework for Mitigating Hallucinations in Multimodal Large Language Models
Feb 15, 2024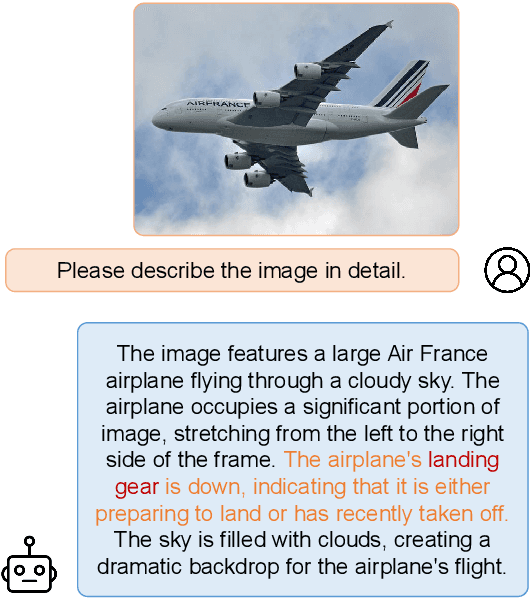
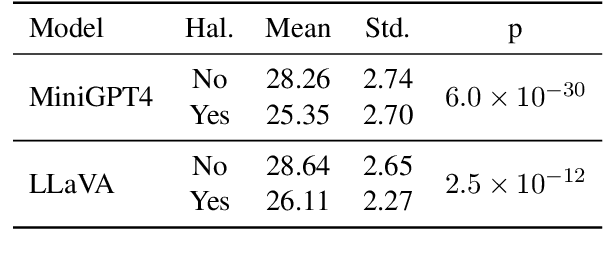
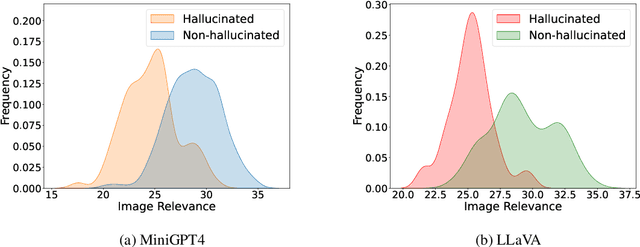

Multimodal large language models (MLLMs) have attracted increasing attention in the past few years, but they may still generate descriptions that include objects not present in the corresponding images, a phenomenon known as object hallucination. To eliminate hallucinations, existing methods manually annotate paired responses with and without hallucinations, and then employ various alignment algorithms to improve the alignment capability between images and text. However, they not only demand considerable computation resources during the finetuning stage but also require expensive human annotation to construct paired data needed by the alignment algorithms. To address these issues, we borrow the idea of unlearning and propose an efficient fine-grained unlearning framework (EFUF), which can eliminate hallucinations without the need for paired data. Extensive experiments show that our method consistently reduces hallucinations while preserving the generation quality with modest computational overhead. Our code and datasets will be publicly available.
DRIN: Dynamic Relation Interactive Network for Multimodal Entity Linking
Oct 09, 2023
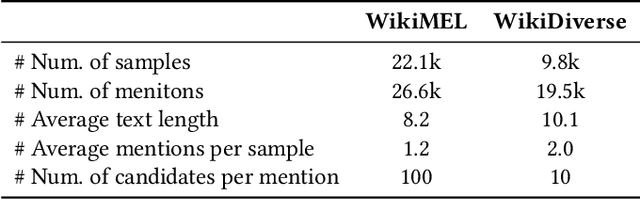
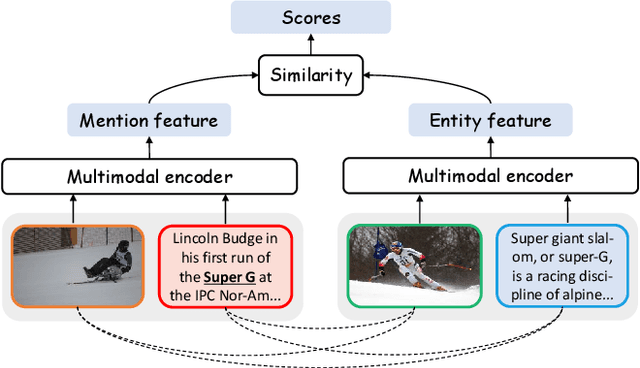
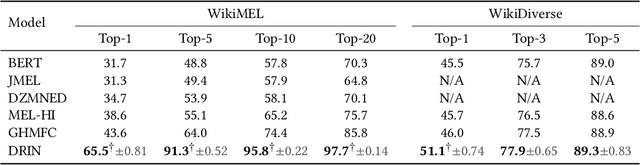
Multimodal Entity Linking (MEL) is a task that aims to link ambiguous mentions within multimodal contexts to referential entities in a multimodal knowledge base. Recent methods for MEL adopt a common framework: they first interact and fuse the text and image to obtain representations of the mention and entity respectively, and then compute the similarity between them to predict the correct entity. However, these methods still suffer from two limitations: first, as they fuse the features of text and image before matching, they cannot fully exploit the fine-grained alignment relations between the mention and entity. Second, their alignment is static, leading to low performance when dealing with complex and diverse data. To address these issues, we propose a novel framework called Dynamic Relation Interactive Network (DRIN) for MEL tasks. DRIN explicitly models four different types of alignment between a mention and entity and builds a dynamic Graph Convolutional Network (GCN) to dynamically select the corresponding alignment relations for different input samples. Experiments on two datasets show that DRIN outperforms state-of-the-art methods by a large margin, demonstrating the effectiveness of our approach.