 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization-Guided Diffusion for Interactive Scene Generation
Dec 11, 2025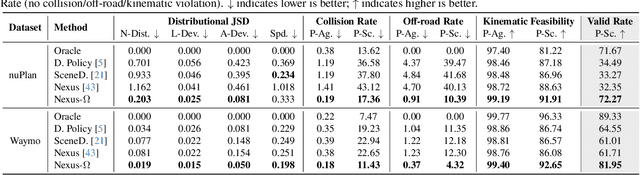
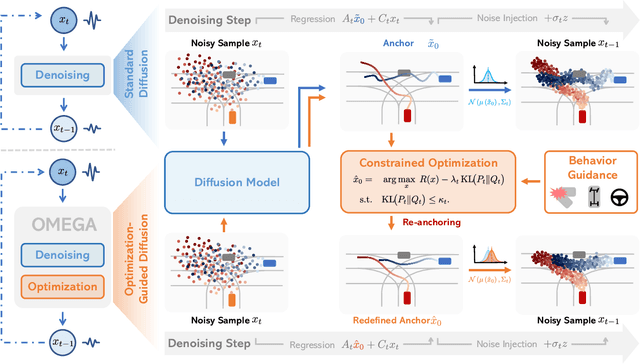
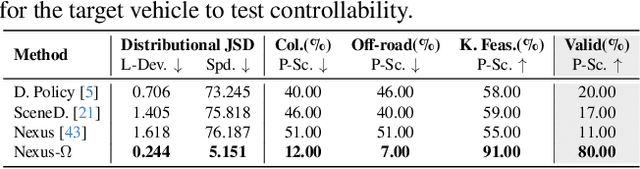
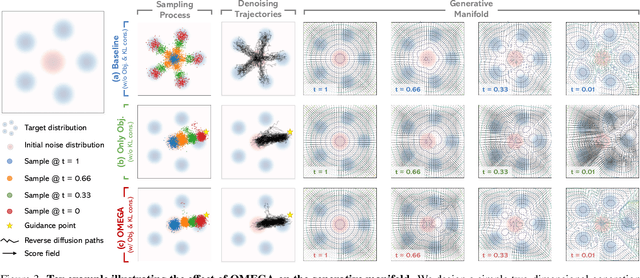
Realistic and diverse multi-agent driving scenes are crucial for evaluating autonomous vehicles, but safety-critical events which are essential for this task are rare and underrepresented in driving datasets. Data-driven scene generation offers a low-cost alternative by synthesizing complex traffic behaviors from existing driving logs. However, existing models often lack controllability or yield samples that violate physical or social constraints, limiting their usability. We present OMEGA, an optimization-guided, training-free framework that enforces structural consistency and interaction awareness during diffusion-based sampling from a scene generation model. OMEGA re-anchors each reverse diffusion step via constrained optimization, steering the generation towards physically plausible and behaviorally coherent trajectories. Building on this framework, we formulate ego-attacker interactions as a game-theoretic optimization in the distribution space, approximating Nash equilibria to generate realistic, safety-critical adversarial scenarios. Experiments on nuPlan and Waymo show that OMEGA improves generation realism, consistency, and controllability, increasing the ratio of physically and behaviorally valid scenes from 32.35% to 72.27% for free exploration capabilities, and from 11% to 80% for controllability-focused generation. Our approach can also generate $5\times$ more near-collision frames with a time-to-collision under three seconds while maintaining the overall scene realism.
IoT-LLM: Enhancing Real-World IoT Task Reasoning with Large Language Models
Oct 03, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities across textual and visual domains but often generate outputs that violate physical laws, revealing a gap in their understanding of the physical world. Inspired by human cognition, where perception is fundamental to reasoning, we explore augmenting LLMs with enhanced perception abilities using Internet of Things (IoT) sensor data and pertinent knowledge for IoT task reasoning in the physical world. In this work, we systematically study LLMs capability to address real-world IoT tasks by augmenting their perception and knowledge base, and then propose a unified framework, IoT-LLM, to enhance such capability. In IoT-LLM, we customize three steps for LLMs: preprocessing IoT data into formats amenable to LLMs, activating their commonsense knowledge through chain-of-thought prompting and specialized role definitions, and expanding their understanding via IoT-oriented retrieval-augmented generation based on in-context learning. To evaluate the performance, We design a new benchmark with five real-world IoT tasks with different data types and reasoning difficulties and provide the benchmarking results on six open-source and close-source LLMs. Experimental results demonstrate the limitations of existing LLMs with naive textual inputs that cannot perform these tasks effectively. We show that IoT-LLM significantly enhances the performance of IoT tasks reasoning of LLM, such as GPT-4, achieving an average improvement of 65% across various tasks against previous methods. The results also showcase LLMs ability to comprehend IoT data and the physical law behind data by providing a reasoning process. Limitations of our work are claimed to inspire future research in this new era.
EFUF: Efficient Fine-grained Unlearning Framework for Mitigating Hallucinations in Multimodal Large Language Models
Feb 15, 2024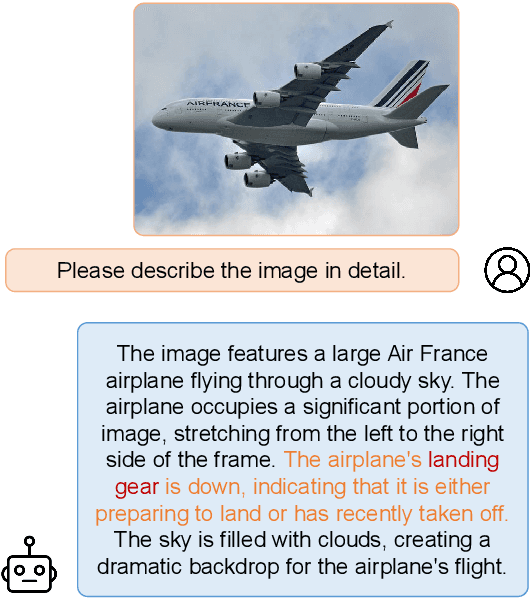
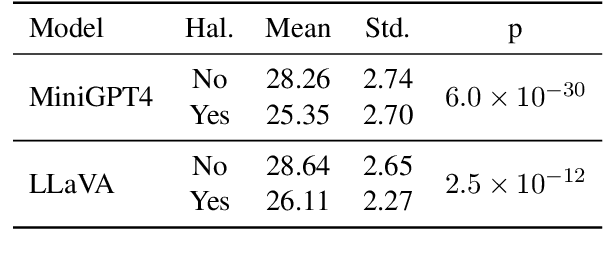
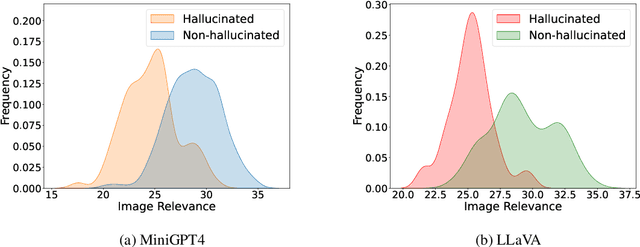

Multimodal large language models (MLLMs) have attracted increasing attention in the past few years, but they may still generate descriptions that include objects not present in the corresponding images, a phenomenon known as object hallucination. To eliminate hallucinations, existing methods manually annotate paired responses with and without hallucinations, and then employ various alignment algorithms to improve the alignment capability between images and text. However, they not only demand considerable computation resources during the finetuning stage but also require expensive human annotation to construct paired data needed by the alignment algorithms. To address these issues, we borrow the idea of unlearning and propose an efficient fine-grained unlearning framework (EFUF), which can eliminate hallucinations without the need for paired data. Extensive experiments show that our method consistently reduces hallucinations while preserving the generation quality with modest computational overhead. Our code and datasets will be publicly available.