 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanar-Sector LOS Guidance for Interception of Agile Targets with Lifting-Wing Quadcopters
Jun 09, 2026Autonomous visual interception of agile aerial targets is challenging due to unpredictable target motion, limited sensing, and the strong coupling between target visibility and interceptor maneuverability. Most existing strapdown-camera interception methods preserve visibility using conic line-of-sight (LOS) constraints that keep the target near the image center. While safe, such symmetric constraints unnecessarily restrict maneuverability and can significantly reduce the usable thrust for pursuit. Motivated by the observation that aggressive FPV pilots do not maintain equal visibility margins in all image directions, this paper proposes a Planar-Sector Line-of-Sight (PS-LOS) guidance framework for autonomous interception using a lifting-wing quadcopter equipped with only a strapdown monocular camera. PS-LOS tightly constrains lateral image error while relaxing longitudinal image error within a safe field-of-view margin, preserving visibility while releasing maneuverability for acceleration-intensive pursuit. Under the lifting-wing quadcopter model, PS-LOS provides nearly 50% more available thrust near the LOS direction than conventional conic LOS constraints. To realize LOS-only interception without direct depth measurements, a delay-compensated state-estimation framework and a nonlinear guidance-and-control architecture are developed for lifting-wing quadcopters. Extensive outdoor flight experiments demonstrate autonomous interception of agile targets exhibiting large-amplitude, high-frequency, and unpredictable motion under real wind disturbances. The proposed system achieves successful interceptions at ranges up to 138 m while maintaining continuous visual tracking throughout the engagement. The results validate PS-LOS as a visibility-preserving, maneuverability-aware guidance framework for long-range visual interception of agile aerial targets.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
SketchAssist: A Practical Assistant for Semantic Edits and Precise Local Redrawing
Dec 16, 2025
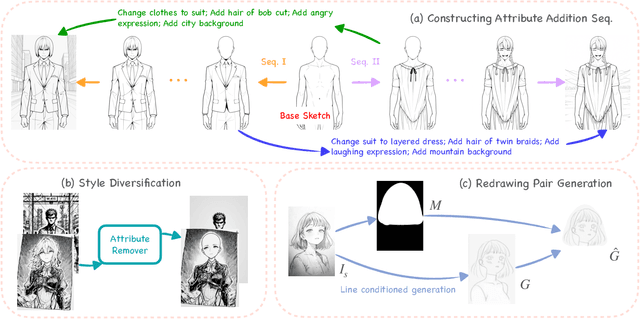
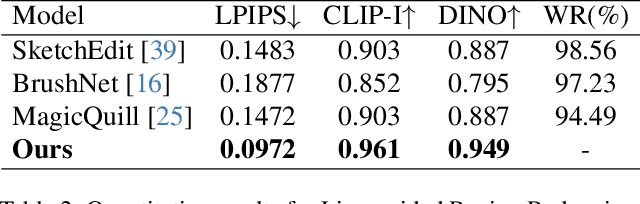
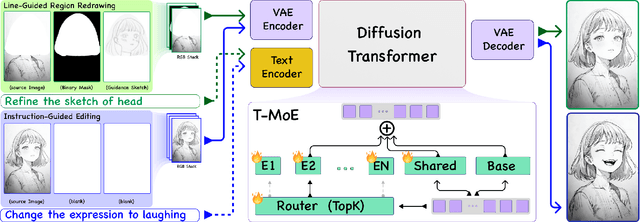
Sketch editing is central to digital illustration, yet existing image editing systems struggle to preserve the sparse, style-sensitive structure of line art while supporting both high-level semantic changes and precise local redrawing. We present SketchAssist, an interactive sketch drawing assistant that accelerates creation by unifying instruction-guided global edits with line-guided region redrawing, while keeping unrelated regions and overall composition intact. To enable this assistant at scale, we introduce a controllable data generation pipeline that (i) constructs attribute-addition sequences from attribute-free base sketches, (ii) forms multi-step edit chains via cross-sequence sampling, and (iii) expands stylistic coverage with a style-preserving attribute-removal model applied to diverse sketches. Building on this data, SketchAssist employs a unified sketch editing framework with minimal changes to DiT-based editors. We repurpose the RGB channels to encode the inputs, enabling seamless switching between instruction-guided edits and line-guided redrawing within a single input interface. To further specialize behavior across modes, we integrate a task-guided mixture-of-experts into LoRA layers, routing by text and visual cues to improve semantic controllability, structural fidelity, and style preservation. Extensive experiments show state-of-the-art results on both tasks, with superior instruction adherence and style/structure preservation compared to recent baselines. Together, our dataset and SketchAssist provide a practical, controllable assistant for sketch creation and revision.
Geometry-Aware Scene-Consistent Image Generation
Dec 14, 2025We study geometry-aware scene-consistent image generation: given a reference scene image and a text condition specifying an entity to be generated in the scene and its spatial relation to the scene, the goal is to synthesize an output image that preserves the same physical environment as the reference scene while correctly generating the entity according to the spatial relation described in the text. Existing methods struggle to balance scene preservation with prompt adherence: they either replicate the scene with high fidelity but poor responsiveness to the prompt, or prioritize prompt compliance at the expense of scene consistency. To resolve this trade-off, we introduce two key contributions: (i) a scene-consistent data construction pipeline that generates diverse, geometrically-grounded training pairs, and (ii) a novel geometry-guided attention loss that leverages cross-view cues to regularize the model's spatial reasoning. Experiments on our scene-consistent benchmark show that our approach achieves better scene alignment and text-image consistency than state-of-the-art baselines, according to both automatic metrics and human preference studies. Our method produces geometrically coherent images with diverse compositions that remain faithful to the textual instructions and the underlying scene structure.
Reframing Music-Driven 2D Dance Pose Generation as Multi-Channel Image Generation
Dec 12, 2025Recent pose-to-video models can translate 2D pose sequences into photorealistic, identity-preserving dance videos, so the key challenge is to generate temporally coherent, rhythm-aligned 2D poses from music, especially under complex, high-variance in-the-wild distributions. We address this by reframing music-to-dance generation as a music-token-conditioned multi-channel image synthesis problem: 2D pose sequences are encoded as one-hot images, compressed by a pretrained image VAE, and modeled with a DiT-style backbone, allowing us to inherit architectural and training advances from modern text-to-image models and better capture high-variance 2D pose distributions. On top of this formulation, we introduce (i) a time-shared temporal indexing scheme that explicitly synchronizes music tokens and pose latents over time and (ii) a reference-pose conditioning strategy that preserves subject-specific body proportions and on-screen scale while enabling long-horizon segment-and-stitch generation. Experiments on a large in-the-wild 2D dance corpus and the calibrated AIST++2D benchmark show consistent improvements over representative music-to-dance methods in pose- and video-space metrics and human preference, and ablations validate the contributions of the representation, temporal indexing, and reference conditioning. See supplementary videos at https://hot-dance.github.io
SpecServe: Efficient and SLO-Aware Large Language Model Serving with Adaptive Speculative Decoding
Mar 07, 2025Large Language Model (LLM) services often face challenges in achieving low inference latency and meeting Service Level Objectives (SLOs) under dynamic request patterns. Speculative decoding, which exploits lightweight models for drafting and LLMs for verification, has emerged as a compelling technique to accelerate LLM inference. However, existing speculative decoding solutions often fail to adapt to varying workloads and system environments, resulting in performance variability and SLO violations. In this paper, we introduce SpecServe, an efficient LLM inference system that dynamically adjusts speculative strategies according to real-time request loads and system configurations. SpecServe proposes a theoretical model to understand and predict the efficiency of speculative decoding across diverse scenarios. Additionally, it implements intelligent drafting and verification algorithms to guarantee optimal performance while achieving high SLO attainment. Experimental results on real-world LLM traces demonstrate that SpecServe consistently meets SLOs and achieves substantial performance improvements, yielding 1.14$\times$-14.3$\times$ speedups over state-of-the-art speculative inference systems.
SerialGen: Personalized Image Generation by First Standardization Then Personalization
Dec 02, 2024

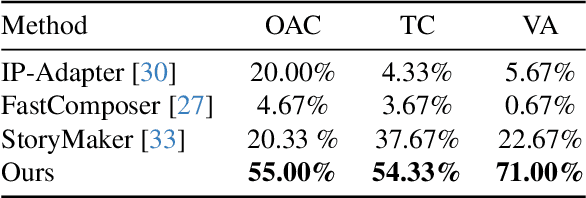

In this work, we are interested in achieving both high text controllability and overall appearance consistency in the generation of personalized human characters. We propose a novel framework, named SerialGen, which is a serial generation method consisting of two stages: first, a standardization stage that standardizes reference images, and then a personalized generation stage based on the standardized reference. Furthermore, we introduce two modules aimed at enhancing the standardization process. Our experimental results validate the proposed framework's ability to produce personalized images that faithfully recover the reference image's overall appearance while accurately responding to a wide range of text prompts. Through thorough analysis, we highlight the critical contribution of the proposed serial generation method and standardization model, evidencing enhancements in appearance consistency between reference and output images and across serial outputs generated from diverse text prompts. The term "Serial" in this work carries a double meaning: it refers to the two-stage method and also underlines our ability to generate serial images with consistent appearance throughout.
RecurFormer: Not All Transformer Heads Need Self-Attention
Oct 10, 2024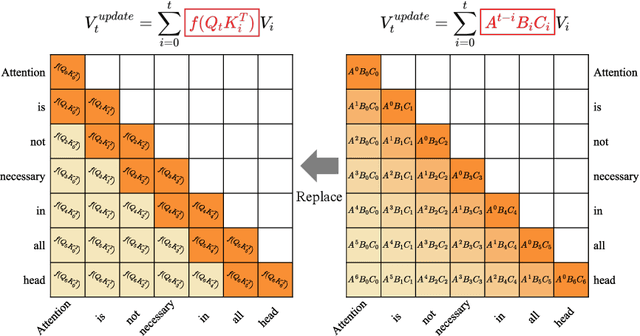
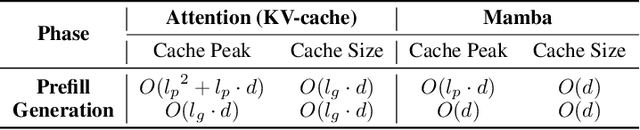
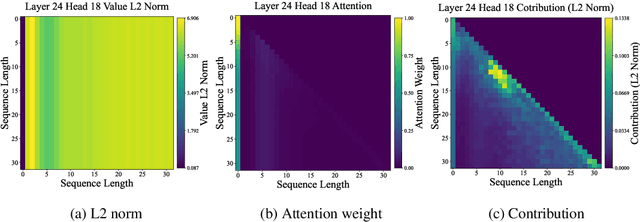
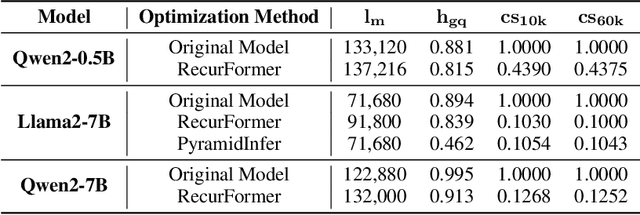
Transformer-based large language models (LLMs) excel in modeling complex language patterns but face significant computational costs during inference, especially with long inputs due to the attention mechanism's memory overhead. We observe that certain attention heads exhibit a distribution where the attention weights concentrate on tokens near the query token, termed as recency aware, which focuses on local and short-range dependencies. Leveraging this insight, we propose RecurFormer, a novel architecture that replaces these attention heads with linear recurrent neural networks (RNNs), specifically the Mamba architecture. This replacement reduces the cache size without evicting tokens, thus maintaining generation quality. RecurFormer retains the ability to model long-range dependencies through the remaining attention heads and allows for reusing pre-trained Transformer-based LLMs weights with continual training. Experiments demonstrate that RecurFormer matches the original model's performance while significantly enhancing inference efficiency. Our approach provides a practical solution to the computational challenges of Transformer-based LLMs inference, making it highly attractive for tasks involving long inputs.
IoT-LLM: Enhancing Real-World IoT Task Reasoning with Large Language Models
Oct 03, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities across textual and visual domains but often generate outputs that violate physical laws, revealing a gap in their understanding of the physical world. Inspired by human cognition, where perception is fundamental to reasoning, we explore augmenting LLMs with enhanced perception abilities using Internet of Things (IoT) sensor data and pertinent knowledge for IoT task reasoning in the physical world. In this work, we systematically study LLMs capability to address real-world IoT tasks by augmenting their perception and knowledge base, and then propose a unified framework, IoT-LLM, to enhance such capability. In IoT-LLM, we customize three steps for LLMs: preprocessing IoT data into formats amenable to LLMs, activating their commonsense knowledge through chain-of-thought prompting and specialized role definitions, and expanding their understanding via IoT-oriented retrieval-augmented generation based on in-context learning. To evaluate the performance, We design a new benchmark with five real-world IoT tasks with different data types and reasoning difficulties and provide the benchmarking results on six open-source and close-source LLMs. Experimental results demonstrate the limitations of existing LLMs with naive textual inputs that cannot perform these tasks effectively. We show that IoT-LLM significantly enhances the performance of IoT tasks reasoning of LLM, such as GPT-4, achieving an average improvement of 65% across various tasks against previous methods. The results also showcase LLMs ability to comprehend IoT data and the physical law behind data by providing a reasoning process. Limitations of our work are claimed to inspire future research in this new era.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.