 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverting the Generation Process of Denoising Diffusion Implicit Models: Empirical Evaluation and a Novel Method
Jun 02, 2026This paper studies the problem of inverting the DDIM image generation process to recover latent variables, particularly the initial noise map, from a generated image. Existing methods often struggle with accuracy in this task. We propose a novel hybrid approach that combines direct inversion via gradient descent for the first step, followed by a fixed-point method for subsequent steps. Empirical evaluations across three datasets demonstrate that our method significantly improves the prediction of initial latent variables while achieving superior reconstruction accuracy. Additionally, we introduce a new evaluation, called the self-interpolation test, which assesses the quality of images generated from interpolated points between the true and predicted latent maps, offering deeper insights into performance. Our results reveal that while existing methods perform reasonably well in reconstruction, they consistently fail to accurately predict the initial latent variables, resulting in poor performance on the self-interpolation test. In contrast, our method outperforms all others across all metrics, providing valuable insights into diffusion models and enhancing their applications in image generation and editing.
MS-DPPs: Multi-Source Determinantal Point Processes for Contextual Diversity Refinement of Composite Attributes in Text to Image Retrieval
Jul 09, 2025
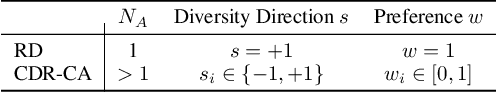
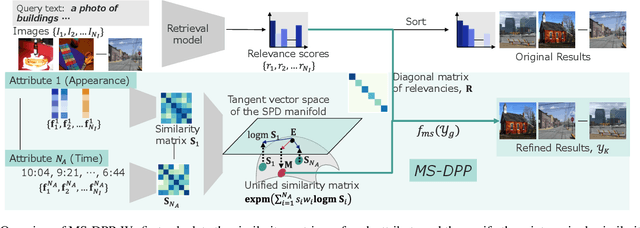
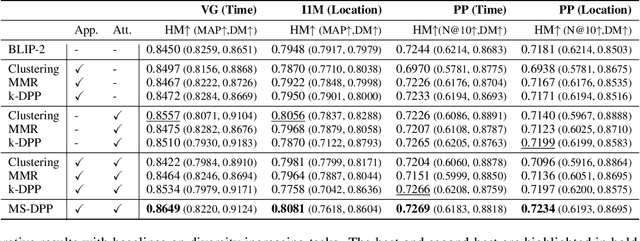
Result diversification (RD) is a crucial technique in Text-to-Image Retrieval for enhancing the efficiency of a practical application. Conventional methods focus solely on increasing the diversity metric of image appearances. However, the diversity metric and its desired value vary depending on the application, which limits the applications of RD. This paper proposes a novel task called CDR-CA (Contextual Diversity Refinement of Composite Attributes). CDR-CA aims to refine the diversities of multiple attributes, according to the application's context. To address this task, we propose Multi-Source DPPs, a simple yet strong baseline that extends the Determinantal Point Process (DPP) to multi-sources. We model MS-DPP as a single DPP model with a unified similarity matrix based on a manifold representation. We also introduce Tangent Normalization to reflect contexts. Extensive experiments demonstrate the effectiveness of the proposed method. Our code is publicly available at https://github.com/NEC-N-SOGI/msdpp.
TB-Bench: Training and Testing Multi-Modal AI for Understanding Spatio-Temporal Traffic Behaviors from Dashcam Images/Videos
Jan 10, 2025



The application of Multi-modal Large Language Models (MLLMs) in Autonomous Driving (AD) faces significant challenges due to their limited training on traffic-specific data and the absence of dedicated benchmarks for spatiotemporal understanding. This study addresses these issues by proposing TB-Bench, a comprehensive benchmark designed to evaluate MLLMs on understanding traffic behaviors across eight perception tasks from ego-centric views. We also introduce vision-language instruction tuning datasets, TB-100k and TB-250k, along with simple yet effective baselines for the tasks. Through extensive experiments, we show that existing MLLMs underperform in these tasks, with even a powerful model like GPT-4o achieving less than 35% accuracy on average. In contrast, when fine-tuned with TB-100k or TB-250k, our baseline models achieve average accuracy up to 85%, significantly enhancing performance on the tasks. Additionally, we demonstrate performance transfer by co-training TB-100k with another traffic dataset, leading to improved performance on the latter. Overall, this study represents a step forward by introducing a comprehensive benchmark, high-quality datasets, and baselines, thus supporting the gradual integration of MLLMs into the perception, prediction, and planning stages of AD.
RP-SLAM: Real-time Photorealistic SLAM with Efficient 3D Gaussian Splatting
Dec 13, 2024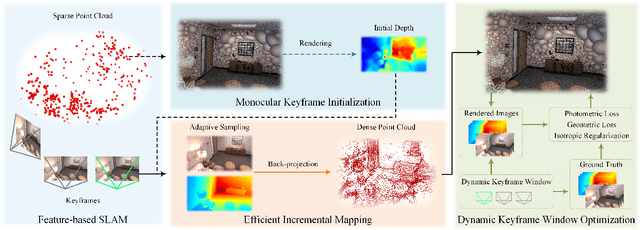

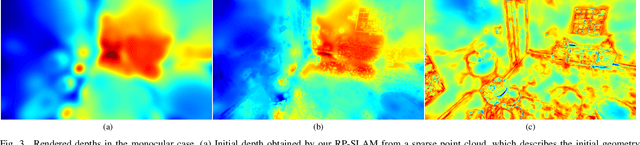

3D Gaussian Splatting has emerged as a promising technique for high-quality 3D rendering, leading to increasing interest in integrating 3DGS into realism SLAM systems. However, existing methods face challenges such as Gaussian primitives redundancy, forgetting problem during continuous optimization, and difficulty in initializing primitives in monocular case due to lack of depth information. In order to achieve efficient and photorealistic mapping, we propose RP-SLAM, a 3D Gaussian splatting-based vision SLAM method for monocular and RGB-D cameras. RP-SLAM decouples camera poses estimation from Gaussian primitives optimization and consists of three key components. Firstly, we propose an efficient incremental mapping approach to achieve a compact and accurate representation of the scene through adaptive sampling and Gaussian primitives filtering. Secondly, a dynamic window optimization method is proposed to mitigate the forgetting problem and improve map consistency. Finally, for the monocular case, a monocular keyframe initialization method based on sparse point cloud is proposed to improve the initialization accuracy of Gaussian primitives, which provides a geometric basis for subsequent optimization. The results of numerous experiments demonstrate that RP-SLAM achieves state-of-the-art map rendering accuracy while ensuring real-time performance and model compactness.
Rethinking Annotation for Object Detection: Is Annotating Small-size Instances Worth Its Cost?
Dec 07, 2024Detecting objects occupying only small areas in an image is difficult, even for humans. Therefore, annotating small-size object instances is hard and thus costly. This study questions common sense by asking the following: is annotating small-size instances worth its cost? We restate it as the following verifiable question: can we detect small-size instances with a detector trained using training data free of small-size instances? We evaluate a method that upscales input images at test time and a method that downscales images at training time. The experiments conducted using the COCO dataset show the following. The first method, together with a remedy to narrow the domain gap between training and test inputs, achieves at least comparable performance to the baseline detector trained using complete training data. Although the method needs to apply the same detector twice to an input image with different scaling, we show that its distillation yields a single-path detector that performs equally well to the same baseline detector. These results point to the necessity of rethinking the annotation of training data for object detection.
Cascaded Multi-Scale Attention for Enhanced Multi-Scale Feature Extraction and Interaction with Low-Resolution Images
Dec 03, 2024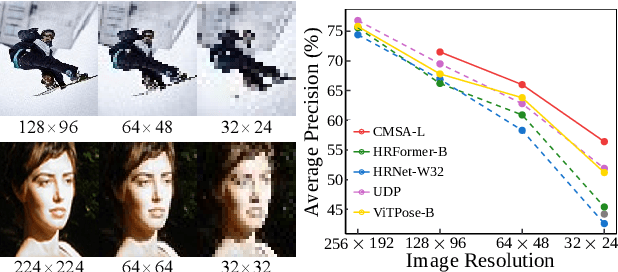
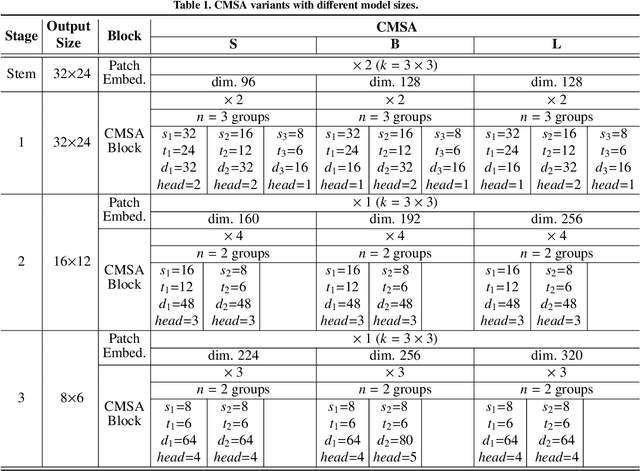
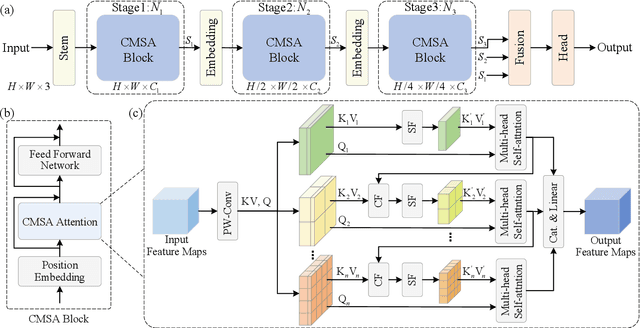
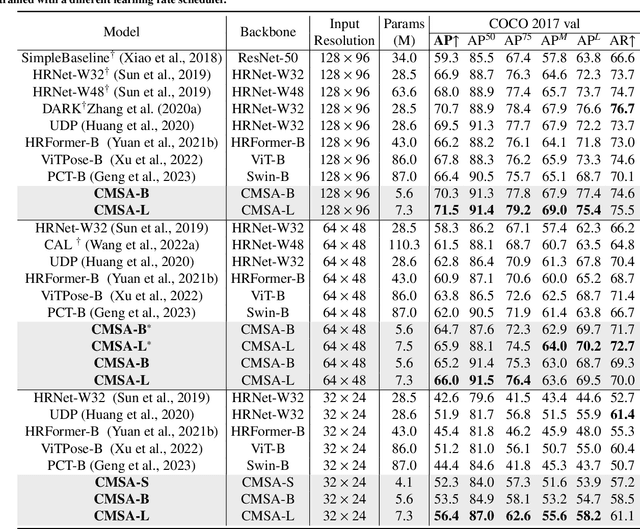
In real-world applications of image recognition tasks, such as human pose estimation, cameras often capture objects, like human bodies, at low resolutions. This scenario poses a challenge in extracting and leveraging multi-scale features, which is often essential for precise inference. To address this challenge, we propose a new attention mechanism, named cascaded multi-scale attention (CMSA), tailored for use in CNN-ViT hybrid architectures, to handle low-resolution inputs effectively. The design of CMSA enables the extraction and seamless integration of features across various scales without necessitating the downsampling of the input image or feature maps. This is achieved through a novel combination of grouped multi-head self-attention mechanisms with window-based local attention and cascaded fusion of multi-scale features over different scales. This architecture allows for the effective handling of features across different scales, enhancing the model's ability to perform tasks such as human pose estimation, head pose estimation, and more with low-resolution images. Our experimental results show that the proposed method outperforms existing state-of-the-art methods in these areas with fewer parameters, showcasing its potential for broad application in real-world scenarios where capturing high-resolution images is not feasible. Code is available at https://github.com/xyongLu/CMSA.
Open-vocabulary vs. Closed-set: Best Practice for Few-shot Object Detection Considering Text Describability
Oct 20, 2024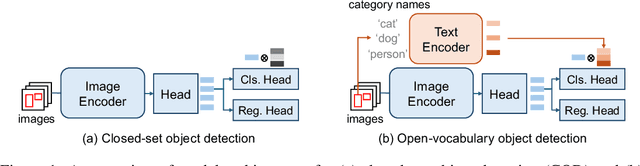
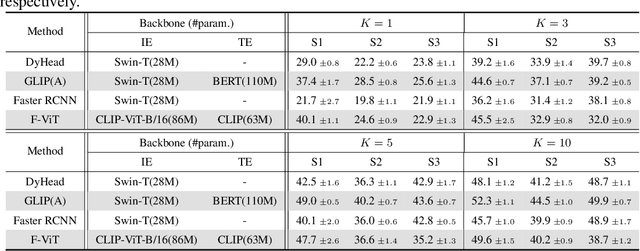
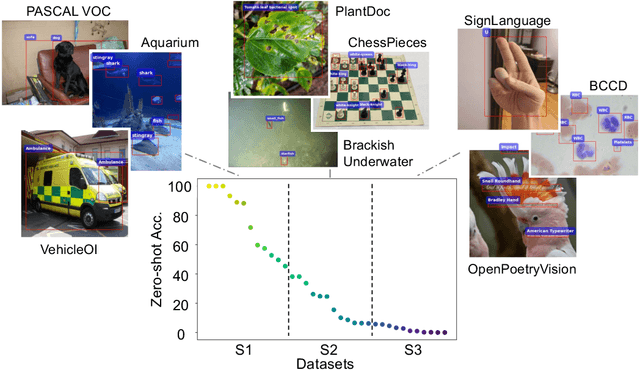
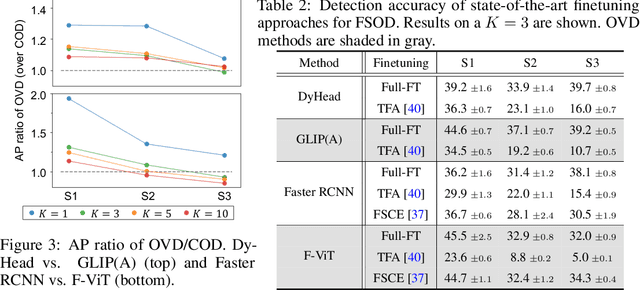
Open-vocabulary object detection (OVD), detecting specific classes of objects using only their linguistic descriptions (e.g., class names) without any image samples, has garnered significant attention. However, in real-world applications, the target class concepts is often hard to describe in text and the only way to specify target objects is to provide their image examples, yet it is often challenging to obtain a good number of samples. Thus, there is a high demand from practitioners for few-shot object detection (FSOD). A natural question arises: Can the benefits of OVD extend to FSOD for object classes that are difficult to describe in text? Compared to traditional methods that learn only predefined classes (referred to in this paper as closed-set object detection, COD), can the extra cost of OVD be justified? To answer these questions, we propose a method to quantify the ``text-describability'' of object detection datasets using the zero-shot image classification accuracy with CLIP. This allows us to categorize various OD datasets with different text-describability and emprically evaluate the FSOD performance of OVD and COD methods within each category. Our findings reveal that: i) there is little difference between OVD and COD for object classes with low text-describability under equal conditions in OD pretraining; and ii) although OVD can learn from more diverse data than OD-specific data, thereby increasing the volume of training data, it can be counterproductive for classes with low-text-describability. These findings provide practitioners with valuable guidance amidst the recent advancements of OVD methods.
An Improved Method for Personalizing Diffusion Models
Jul 07, 2024Diffusion models have demonstrated impressive image generation capabilities. Personalized approaches, such as textual inversion and Dreambooth, enhance model individualization using specific images. These methods enable generating images of specific objects based on diverse textual contexts. Our proposed approach aims to retain the model's original knowledge during new information integration, resulting in superior outcomes while necessitating less training time compared to Dreambooth and textual inversion.
SBCFormer: Lightweight Network Capable of Full-size ImageNet Classification at 1 FPS on Single Board Computers
Nov 07, 2023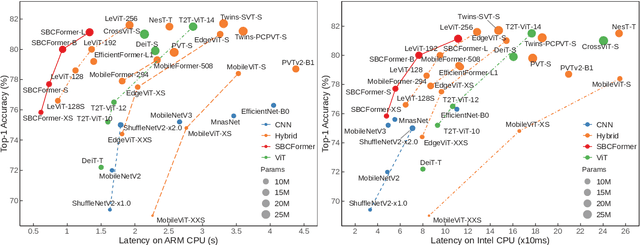
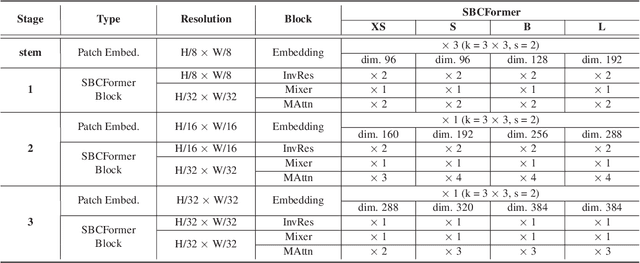
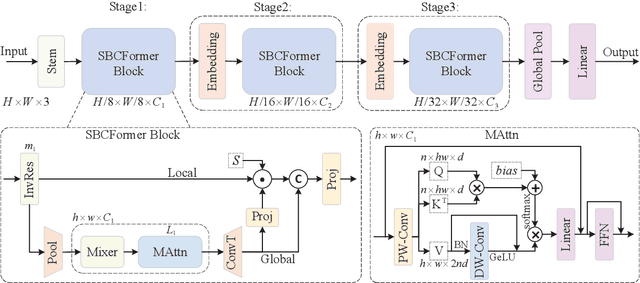
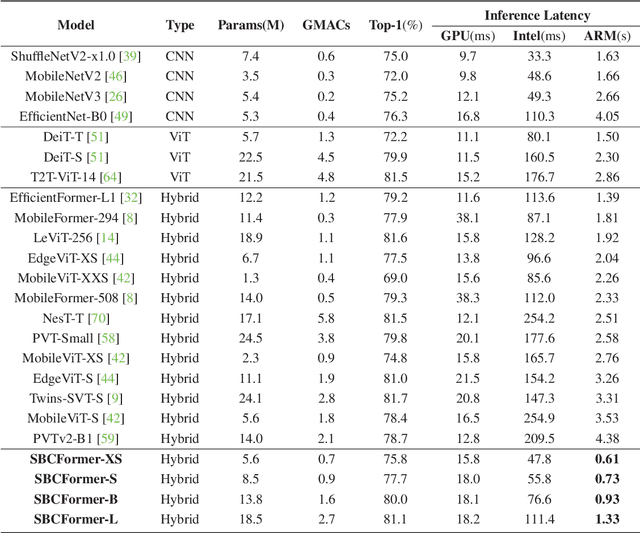
Computer vision has become increasingly prevalent in solving real-world problems across diverse domains, including smart agriculture, fishery, and livestock management. These applications may not require processing many image frames per second, leading practitioners to use single board computers (SBCs). Although many lightweight networks have been developed for mobile/edge devices, they primarily target smartphones with more powerful processors and not SBCs with the low-end CPUs. This paper introduces a CNN-ViT hybrid network called SBCFormer, which achieves high accuracy and fast computation on such low-end CPUs. The hardware constraints of these CPUs make the Transformer's attention mechanism preferable to convolution. However, using attention on low-end CPUs presents a challenge: high-resolution internal feature maps demand excessive computational resources, but reducing their resolution results in the loss of local image details. SBCFormer introduces an architectural design to address this issue. As a result, SBCFormer achieves the highest trade-off between accuracy and speed on a Raspberry Pi 4 Model B with an ARM-Cortex A72 CPU. For the first time, it achieves an ImageNet-1K top-1 accuracy of around 80% at a speed of 1.0 frame/sec on the SBC. Code is available at https://github.com/xyongLu/SBCFormer.
* 11 pages, 2 figures, WACV2024
Visual Abductive Reasoning Meets Driving Hazard Prediction: Problem Formulation and Dataset
Oct 10, 2023



This paper addresses the problem of predicting hazards that drivers may encounter while driving a car. We formulate it as a task of anticipating impending accidents using a single input image captured by car dashcams. Unlike existing approaches to driving hazard prediction that rely on computational simulations or anomaly detection from videos, this study focuses on high-level inference from static images. The problem needs predicting and reasoning about future events based on uncertain observations, which falls under visual abductive reasoning. To enable research in this understudied area, a new dataset named the DHPR (Driving Hazard Prediction and Reasoning) dataset is created. The dataset consists of 15K dashcam images of street scenes, and each image is associated with a tuple containing car speed, a hypothesized hazard description, and visual entities present in the scene. These are annotated by human annotators, who identify risky scenes and provide descriptions of potential accidents that could occur a few seconds later. We present several baseline methods and evaluate their performance on our dataset, identifying remaining issues and discussing future directions. This study contributes to the field by introducing a novel problem formulation and dataset, enabling researchers to explore the potential of multi-modal AI for driving hazard prediction.