 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360° Image Perception with MLLMs: A Comprehensive Benchmark and a Training-Free Method
Mar 17, 2026Multimodal Large Language Models (MLLMs) have shown impressive abilities in understanding and reasoning over conventional images. However, their perception of 360° images remains largely underexplored. Unlike conventional images, 360° images capture the entire surrounding environment, enabling holistic spatial reasoning but introducing challenges such as geometric distortion and complex spatial relations. To comprehensively assess MLLMs' capabilities to perceive 360° images, we introduce 360Bench, a Visual Question Answering (VQA) benchmark featuring 7K-resolution 360° images, seven representative (sub)tasks with annotations carefully curated by human annotators. Using 360Bench, we systematically evaluate seven MLLMs and six enhancement methods, revealing their shortcomings in 360° image perception. To address these challenges, we propose Free360, a training-free scene-graph-based framework for high-resolution 360° VQA. Free360 decomposes the reasoning process into modular steps, applies adaptive spherical image transformations to 360° images tailored to each step, and seamlessly integrates the resulting information into a unified graph representation for answer generation. Experiments show that Free360 consistently improves its base MLLM and provides a strong training-free solution for 360° VQA tasks. The source code and dataset will be publicly released upon acceptance.
CoReTab: Improving Multimodal Table Understanding with Code-driven Reasoning
Jan 27, 2026Existing datasets for multimodal table understanding, such as MMTab, primarily provide short factual answers without explicit multi-step reasoning supervision. Models trained on these datasets often generate brief responses that offers insufficient accuracy and limited interpretability into how these models arrive at the final answer. We introduce CoReTab, a code-driven reasoning framework that produces scalable, interpretable, and automatically verifiable annotations by coupling multi-step reasoning with executable Python code. Using the CoReTab framework, we curate a dataset of 115K verified samples averaging 529 tokens per response and fine-tune open-source MLLMs through a three-stage pipeline. We evaluate the resulting model trained on CoReTab across 17 MMTab benchmarks spanning table question answering, fact verification, and table structure understanding. Our model achieves significant gains of +6.2%, +5.7%, and +25.6%, respectively, over MMTab-trained baselines, while producing transparent and verifiable reasoning traces. These results establish CoReTab as a robust and generalizable supervision framework for improving multi-step reasoning in multimodal table understanding.
TB-Bench: Training and Testing Multi-Modal AI for Understanding Spatio-Temporal Traffic Behaviors from Dashcam Images/Videos
Jan 10, 2025



The application of Multi-modal Large Language Models (MLLMs) in Autonomous Driving (AD) faces significant challenges due to their limited training on traffic-specific data and the absence of dedicated benchmarks for spatiotemporal understanding. This study addresses these issues by proposing TB-Bench, a comprehensive benchmark designed to evaluate MLLMs on understanding traffic behaviors across eight perception tasks from ego-centric views. We also introduce vision-language instruction tuning datasets, TB-100k and TB-250k, along with simple yet effective baselines for the tasks. Through extensive experiments, we show that existing MLLMs underperform in these tasks, with even a powerful model like GPT-4o achieving less than 35% accuracy on average. In contrast, when fine-tuned with TB-100k or TB-250k, our baseline models achieve average accuracy up to 85%, significantly enhancing performance on the tasks. Additionally, we demonstrate performance transfer by co-training TB-100k with another traffic dataset, leading to improved performance on the latter. Overall, this study represents a step forward by introducing a comprehensive benchmark, high-quality datasets, and baselines, thus supporting the gradual integration of MLLMs into the perception, prediction, and planning stages of AD.
KTVIC: A Vietnamese Image Captioning Dataset on the Life Domain
Jan 16, 2024Image captioning is a crucial task with applications in a wide range of domains, including healthcare and education. Despite extensive research on English image captioning datasets, the availability of such datasets for Vietnamese remains limited, with only two existing datasets. In this study, we introduce KTVIC, a comprehensive Vietnamese Image Captioning dataset focused on the life domain, covering a wide range of daily activities. This dataset comprises 4,327 images and 21,635 Vietnamese captions, serving as a valuable resource for advancing image captioning in the Vietnamese language. We conduct experiments using various deep neural networks as the baselines on our dataset, evaluating them using the standard image captioning metrics, including BLEU, METEOR, CIDEr, and ROUGE. Our findings underscore the effectiveness of the proposed dataset and its potential contributions to the field of image captioning in the Vietnamese context.
Visual Abductive Reasoning Meets Driving Hazard Prediction: Problem Formulation and Dataset
Oct 10, 2023



This paper addresses the problem of predicting hazards that drivers may encounter while driving a car. We formulate it as a task of anticipating impending accidents using a single input image captured by car dashcams. Unlike existing approaches to driving hazard prediction that rely on computational simulations or anomaly detection from videos, this study focuses on high-level inference from static images. The problem needs predicting and reasoning about future events based on uncertain observations, which falls under visual abductive reasoning. To enable research in this understudied area, a new dataset named the DHPR (Driving Hazard Prediction and Reasoning) dataset is created. The dataset consists of 15K dashcam images of street scenes, and each image is associated with a tuple containing car speed, a hypothesized hazard description, and visual entities present in the scene. These are annotated by human annotators, who identify risky scenes and provide descriptions of potential accidents that could occur a few seconds later. We present several baseline methods and evaluate their performance on our dataset, identifying remaining issues and discussing future directions. This study contributes to the field by introducing a novel problem formulation and dataset, enabling researchers to explore the potential of multi-modal AI for driving hazard prediction.
Leveraging Video Coding Knowledge for Deep Video Enhancement
Feb 27, 2023


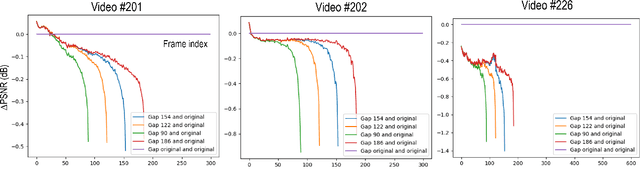
Recent advancements in deep learning techniques have significantly improved the quality of compressed videos. However, previous approaches have not fully exploited the motion characteristics of compressed videos, such as the drastic change in motion between video contents and the hierarchical coding structure of the compressed video. This study proposes a novel framework that leverages the low-delay configuration of video compression to enhance the existing state-of-the-art method, BasicVSR++. We incorporate a context-adaptive video fusion method to enhance the final quality of compressed videos. The proposed approach has been evaluated in the NTIRE22 challenge, a benchmark for video restoration and enhancement, and achieved improvements in both quantitative metrics and visual quality compared to the previous method.
GRIT: Faster and Better Image captioning Transformer Using Dual Visual Features
Jul 20, 2022


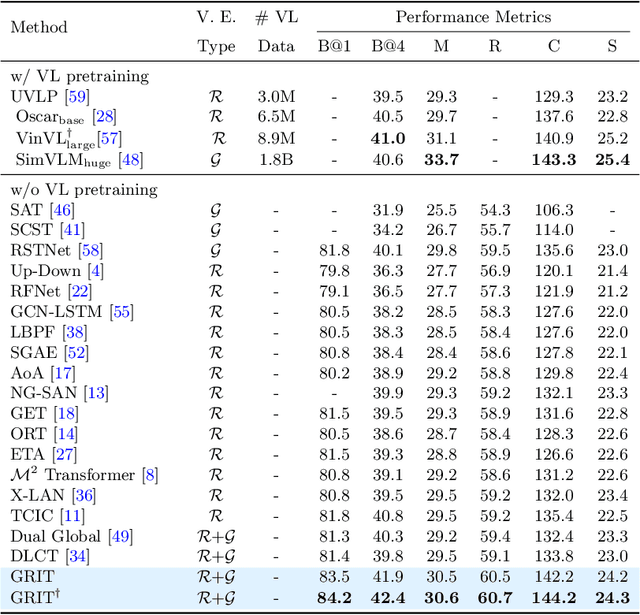
Current state-of-the-art methods for image captioning employ region-based features, as they provide object-level information that is essential to describe the content of images; they are usually extracted by an object detector such as Faster R-CNN. However, they have several issues, such as lack of contextual information, the risk of inaccurate detection, and the high computational cost. The first two could be resolved by additionally using grid-based features. However, how to extract and fuse these two types of features is uncharted. This paper proposes a Transformer-only neural architecture, dubbed GRIT (Grid- and Region-based Image captioning Transformer), that effectively utilizes the two visual features to generate better captions. GRIT replaces the CNN-based detector employed in previous methods with a DETR-based one, making it computationally faster. Moreover, its monolithic design consisting only of Transformers enables end-to-end training of the model. This innovative design and the integration of the dual visual features bring about significant performance improvement. The experimental results on several image captioning benchmarks show that GRIT outperforms previous methods in inference accuracy and speed.
Look Wide and Interpret Twice: Improving Performance on Interactive Instruction-following Tasks
Jun 06, 2021
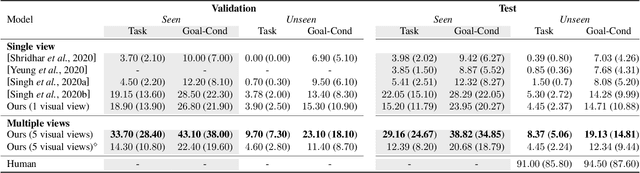
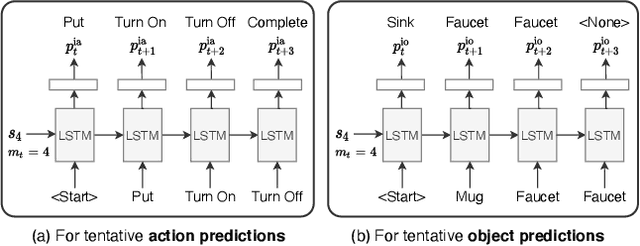
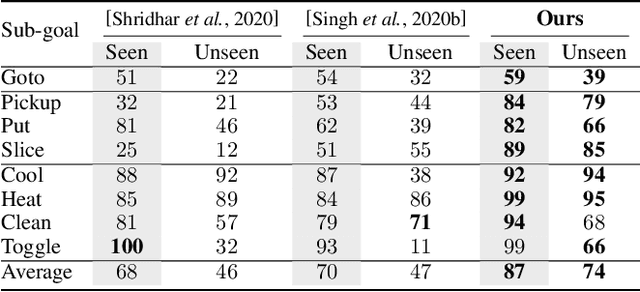
There is a growing interest in the community in making an embodied AI agent perform a complicated task while interacting with an environment following natural language directives. Recent studies have tackled the problem using ALFRED, a well-designed dataset for the task, but achieved only very low accuracy. This paper proposes a new method, which outperforms the previous methods by a large margin. It is based on a combination of several new ideas. One is a two-stage interpretation of the provided instructions. The method first selects and interprets an instruction without using visual information, yielding a tentative action sequence prediction. It then integrates the prediction with the visual information etc., yielding the final prediction of an action and an object. As the object's class to interact is identified in the first stage, it can accurately select the correct object from the input image. Moreover, our method considers multiple egocentric views of the environment and extracts essential information by applying hierarchical attention conditioned on the current instruction. This contributes to the accurate prediction of actions for navigation. A preliminary version of the method won the ALFRED Challenge 2020. The current version achieves the unseen environment's success rate of 4.45% with a single view, which is further improved to 8.37% with multiple views.
Efficient Attention Mechanism for Handling All the Interactions between Many Inputs with Application to Visual Dialog
Nov 26, 2019

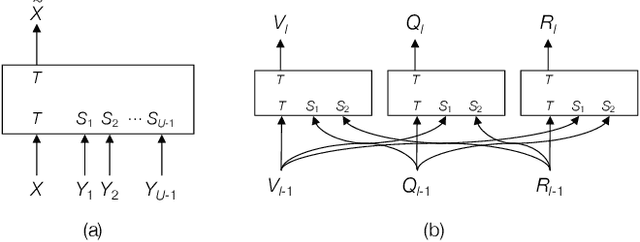
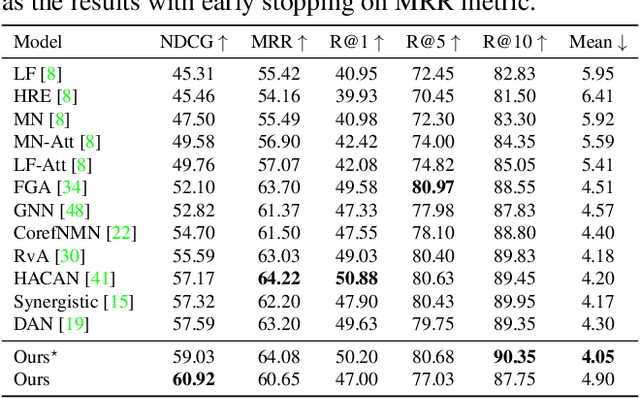
It has been a primary concern in recent studies of vision and language tasks to design an effective attention mechanism dealing with interactions between the two modalities. The Transformer has recently been extended and applied to several bi-modal tasks, yielding promising results. For visual dialog, it becomes necessary to consider interactions between three or more inputs, i.e., an image, a question, and a dialog history, or even its individual dialog components. In this paper, we present a neural architecture that can efficiently deal with all the interactions between many such inputs. It has a block structure similar to the Transformer and employs the same design of attention computation, whereas it has only a small number of parameters, yet has sufficient representational power for the purpose. Assuming a standard setting of visual dialog, a network built upon the proposed attention block has less than one-tenth of parameters as compared with its counterpart, a natural Transformer extension. We present its application to the visual dialog task. The experimental results validate the effectiveness of the proposed approach, showing improvements of the best NDCG score on the VisDial v1.0 dataset from 57.59 to 60.92 with a single model, from 64.47 to 66.53 with ensemble models, and even to 74.88 with additional finetuning.